溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Python依賴庫太多怎么辦的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
在 Python 的項目中,如何管理所用的全部依賴庫呢?最主流的做法是維護一份“requirements.txt”,記錄下依賴庫的名字及其版本號。
那么,如何來生成這份文件呢?在上篇文章《由淺入深:Python 中如何實現自動導入缺失的庫?》中,我提到了一種常規的方法:
pip freeze > requirements . txt
這種方法用起來方便,但有幾點不足:
它搜索依賴庫的范圍是全局環境,因此會把項目之外的庫加入進來,造成冗余(一般是在虛擬環境中使用,但還是可能包含無關的依賴庫)
它只會記錄以“pip install”方式安裝的庫
它對依賴庫之間的依賴關系不做區分
它無法判斷版本差異及循環依賴等情況
…………
可用于項目依賴管理的工具有很多,本文主要圍繞與 requirements.txt 文件相關的、比較相似卻又各具特色的 4 個三方庫,簡要介紹它們的使用方法,羅列一些顯著的功能點。至于哪個是最好的管理方案呢?賣個關子,請往下看……
pipreqs
這是個很受歡迎的用于管理項目中依賴庫的工具,可以用“pip install pipreqs”命令來安裝。它的主要特點有:
搜索依賴庫的范圍是基于目錄的方式,很有針對性
搜索的依據是腳本中所 import 的內容
可以在未安裝依賴庫的環境上生成依賴文件
查找軟件包信息時,可以指定查詢方式(只在本地查詢、在 PyPi 查詢、或者在自定義的 PyPi 服務)
基本的命令選項如下:
Usage : pipreqs [ options ] <path> Options : -- use - local Use ONLY local package info instead of querying PyPI -- pypi - server <url> Use custom PyPi server -- proxy <url> Use Proxy , parameter will be passed to requests library . You can also just set the environments parameter in your terminal : $ export HTTP_PROXY = "http://10.10.1.10:3128" $ export HTTPS_PROXY = "https://10.10.1.10:1080" -- debug Print debug information -- ignore <dirs> ... Ignore extra directories -- encoding <charset> Use encoding parameter for file open -- savepath <file> Save the list of requirements in the given file -- print Output the list of requirements in the standard output -- force Overwrite existing requirements . txt -- diff <file> Compare modules in requirements . txt to project imports . -- clean <file> Clean up requirements . txt by removing modules that are not imported in project .
其中需注意,很可能遇到編碼錯誤:UnicodeDecodeError:'gbk'codec can't decode byte 0xae in。需要指定編碼格式“--encoding=utf8”。
在已生成依賴文件“requirements.txt”的情況下,它可以強行覆蓋、比對差異以及清除不再使用的依賴項。
pigar
pigar 同樣可以根據項目路徑來生成依賴文件,而且會列出依賴庫在文件中哪些位置使用到了。這個功能充分利用了 requirements.txt 文件中的注釋,可以提供很豐富的信息。
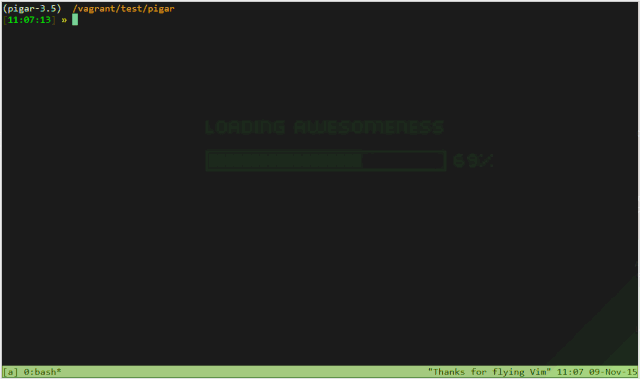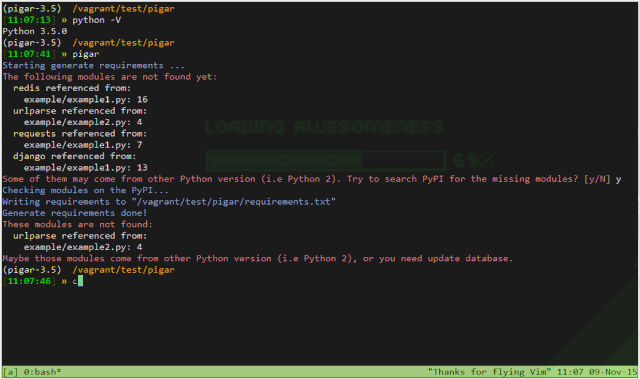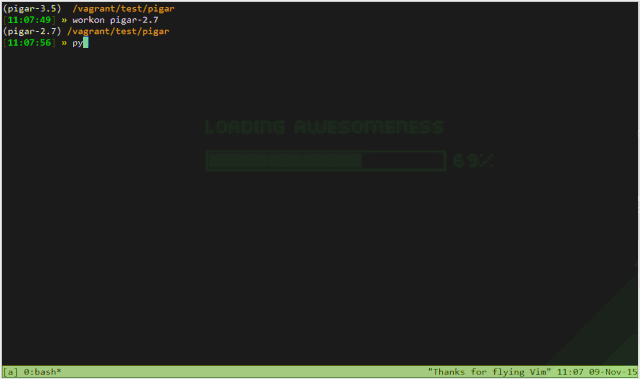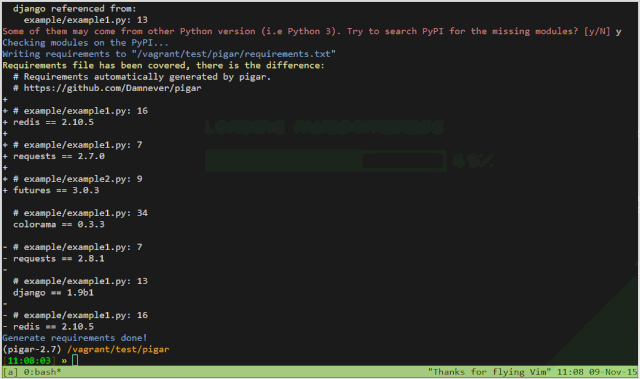
pigar 對于查詢真實的導入源很有幫助,例如 bs4 模塊來自 beautifulsoup4 庫, MySQLdb 則來自于 MySQL_Python 庫。可以通過“-s”參數,查找真實的依賴庫。
$ pigar - s bs4 MySQLdb
它使用解析 AST 的方式,而非正則表達式的方式,可以很方便地從 exec/eval 的參數、文檔字符串的文檔測試中提取出依賴庫。
另外,它對于不同 Python 版本的差異可以很好地支持。例如, concurrent.futures 是 Python 3.2+ 的標準庫,而在之前早期版本中,需要安裝三方庫 futures ,才能使用它。pigar 做到了有效地識別區分。(PS:pipreqs 也支持這個識別,詳見這個合入:https://github.com/bndr/pipreqs/pull/80)
pip-tools
pip-tools 包含一組管理項目依賴的工具:pip-compile 與 pip-sync,可以使用命令“pip install pip-tools”統一安裝。它最大的優勢是可以精準地控制項目的依賴庫。
兩個工具的用途及關系圖如下:

pip-compile 命令主要用于生成依賴文件和升級依賴庫,另外它可以支持 pip 的“Hash-Checking Mode ”,并支持在一個依賴文件中嵌套其它的依賴文件(例如,在 requirements.in 文件內,可以用“-c requirements.txt”方式,引入一個依賴文件)。
它可以根據 setup.py 文件來生成 requirements.txt,假如一個 Flask 項目的 setup.py 文件中寫了“install_requires=['Flask']”,那么可以用命令來生成它的所有依賴:
$ pip - compile # # This file is autogenerated by pip-compile # To update, run: # # pip-compile --output-file requirements.txt setup.py # click == 6.7 # via flask flask == 0.12 . 2 itsdangerous == 0.24 # via flask jinja2 == 2.9 . 6 # via flask markupsafe == 1.0 # via jinja2 werkzeug == 0.12 . 2 # via flask
在不使用 setup.py 文件的情況下,可以創建“requirements.in”,在里面寫入“Flask”,再執行“pip-compile requirements.in”,可以達到跟前面一樣的效果。
pip-sync 命令可以根據 requirements.txt 文件,來對虛擬環境中進行安裝、升級或卸載依賴庫(注意:除了 setuptools、pip 和 pip-tools 之外)。這樣可以有針對性且按需精簡地管理虛擬環境中的依賴庫。
另外,該命令可以將多個“*.txt”依賴文件歸并成一個:
$ pip-sync dev-requirements.txt requirements.txt
pipdeptree
它的主要用途是展示 Python 項目的依賴樹,通過有層次的縮進格式,顯示它們的依賴關系,不像前面那些工具只會生成扁平的并列關系。

除此之外,它還可以:
生成普遍適用的 requirements.txt 文件
逆向查找某個依賴庫是怎么引入進來的
提示出相互沖突的依賴庫
可以發現循環依賴,進行告警
生成多種格式的依賴樹文件(json、graph、pdf、png等等)
它也有缺點,比如無法穿透虛擬環境。如果要在虛擬環境中工作,必須在該虛擬環境中安裝 pipdeptree。因為跨虛擬環境會出現重復或沖突等情況,因此需要限定虛擬環境。但是每個虛擬環境都安裝一個 pipdeptree,還是挺讓人難受的。
感謝各位的閱讀!關于“Python依賴庫太多怎么辦”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





