溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天訓練faster R-CNN時,發現之前跑的很好的程序(是指在運行程序過程中,顯卡利用率能夠一直維持在70%以上),今天看的時候,顯卡利用率很低,所以在想是不是我的訓練數據torch.Tensor或者模型model沒有加載到GPU上訓練,于是查找如何查看tensor和model所在設備的命令。
import torch import torchvision.models as models model=models.vgg11(pretrained=False) print(next(model.parameters()).is_cuda)#False data=torch.ones((5,10)) print(data.device)#cpu
上述是我在自己的筆記本上(顯然沒有GPU)的打印情況。
上次被老板教授了好久,出現西安卡利用率一直很低的情況千萬不能認為它不是問題,而一定要想辦法解決。比如可以在加載訓練圖像的過程中(__getitem__方法中)設定數據增強過程中每個步驟的時間點,對每個步驟的時間點進行打印,判斷花費時間較多的是哪些步驟,然后嘗試對代碼進行優化,因為torhc.utils.data中的__getitem__方法是由CPU上的一個num_workers執行一遍的,如果__getitem__方法執行太慢,則會導致IO速度變慢,即GPU在大多數時間都處于等待CPU讀取數據并處理成torch.cuda.tensor的過程,一旦CPU讀取一個batch size的數據完畢,GPU很快就計算結束,從而看到的現象是:GPU在絕大多數時間都處于利用率很低的狀態。
所以我總結的是,如果GPU顯卡利用率比較低,最可能的就是CPU數據IO耗費時間太多(我之前就是由于數據增強的裁剪過程為了裁剪到object使用了for循環,導致這一操作很耗時間),還有可能的原因是數據tensor或者模型model根本就沒有加載到GPU cuda上面。其實還有一種可能性很小的原因就是,在網絡前向傳播的過程中某些特殊的操作對GPU的利用率不高,當然指的是除了網絡(卷積,全連接)操作之外的其他的對于tensor的操作,比如我之前的faster R-CNN顯卡利用率低就是因為RPN中的NMS算法速度太慢,大約2-3秒一張圖,雖然這時候tensor特征圖在CUDA上面,而且NMS也使用了CUDA kernel編譯后的代碼,也就是說NMS的計算仍然是利用的CPU,但是由于NMS算法并行度不高,所以對于GPU的利用不多,導致了顯卡利用率低,之前那個是怎么解決的呢?
哈哈,說到底還是環境的問題非常重要,之前的faster R-CNN代碼在python2 CUDA9.0 pytorch 0.4.0 環境下編譯成功我就沒有再仔細糾結環境問題,直接運行了,直到后來偶然換成python3 CUDA9.0 pytorch 0.4.1 環境才極大地提高了顯卡利用率,并且通過設置了幾十個打印時間點之后發現,真的就是NMS的速度現在基本能維持在0.02-0.2數量級范圍內。
下圖分別表示之前(顯卡利用率很低)時的NMS處理單張圖像所消耗的時間(之所以會有長有短是因為我支持不同分辨率的圖像訓練),后面一張圖是GPU利用率一直能維持在很高的情況下NMS處理時間,由于數據增強部分的代碼完全沒有修改,故而換了環境之后我就沒有再打印數據增強每個步驟所消耗的時間了。
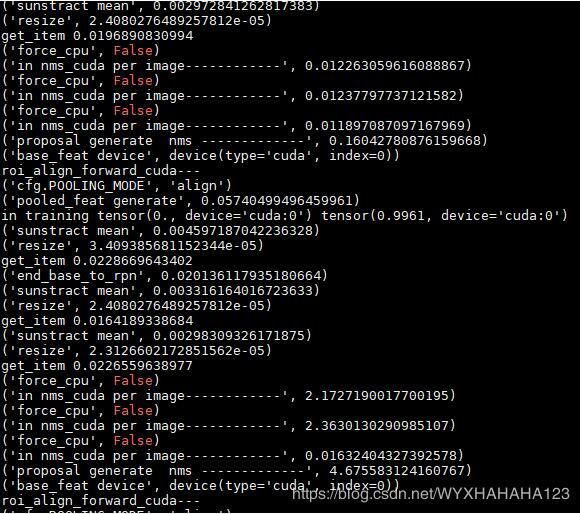
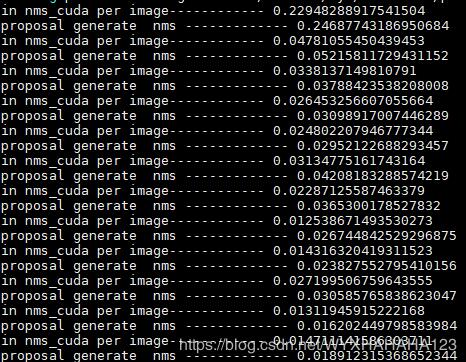
以上這篇pytorch查看torch.Tensor和model是否在CUDA上的實例就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





