溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
訓練完目標檢測模型之后,需要評價其性能,在不同的閾值下的準確度是多少,有沒有漏檢,在這里基于IoU(Intersection over Union)來計算。
希望能提供一些思路,如果覺得有用歡迎贊我表揚我~
IoU的值可以理解為系統預測出來的框與原來圖片中標記的框的重合程度。系統預測出來的框是利用目標檢測模型對測試數據集進行識別得到的。
計算方法即檢測結果DetectionResult與GroundTruth的交集比上它們的并集,如下圖:
藍色的框是:GroundTruth
黃色的框是:DetectionResult
綠色的框是:DetectionResult ⋂GroundTruth
紅色的框是:DetectionResult ⋃GroundTruth
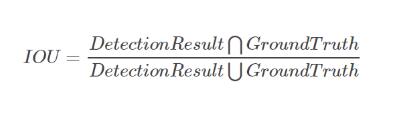

基本思路是先讀取原來圖中標記的框信息,對每一張圖,把所需要的那一個類別的框拿出來,與測試集上識別出來的框進行比較,計算IoU,選擇最大的值作為當前框的IoU值,然后通過設定的閾值(漏檢0, 0.3, 0.5, 0.7)來進行比較統計,最后得到每個閾值下的所有的判定為正確檢測(IoU值大于閾值)的框的數量,然后與原本的標記框的數量一起計算準確度。
其中計算IoU的時候是重新構建一個背景為0的圖,設定框所在的位置為1,分別利用原本標注的框和測試識別的框來構建兩個這樣的圖,兩者相加就能夠讓重疊的部分變成2,于是就可以知道重疊部分的大小(交集),從而計算IoU。
構建代碼如下:
#讀取txt-標準txt為基準-分類別求閾值-閾值為0. 0.3 0.5 0.7的統計
import glob
import os
import numpy as np
#設定的閾值
threshold1=0.3
threshold2=0.5
threshold3=0.7
#閾值計數器
counter0=0
counter1=0
counter2=0
counter3=0
stdtxt=''#標注txt路徑
testtxt=''#測試txt路徑
txtlist=glob.glob(r'%s\*.txt' %stdtxt)#獲取所有txt文件
for path in txtlist:#對每個txt操作
txtname=os.path.basename(path)[:-4]#獲取txt文件名
label=1
eachtxt=np.loadtxt(path) #讀取文件
for line in eachtxt:
if line[0]==label:
#構建背景為0框為1的圖
map1=np.zeros((960,1280))
map1[line[2]:(line[2]+line[4]),line[1]:(line[1]+line[3])]=1
testfile=np.loadtxt(testtxt + txtname + '.txt')
c=0
iou_list=[]#用來存儲所有iou的集合
for tline in testfile:#對測試txt的每行進行操作
if tline[0]==label:
c=c+1
map2=np.zeros((960,1280))
map2[tline[2]:(tline[2]+tline[4]),tline[1]:(tline[1]+tline[3])]=1
map3=map1+map2
a=0
for i in map3:
if i==2:
a=a+1
iou=a/(line[3]*line[4]+tline[3]*tline[4]-a)#計算iou
iou_list.append(iou)#添加到集合尾部
threshold=max(iou_list)#閾值取最大的
#閾值統計
if threshold>=threshold3:
counter3=counter3+1
elif threshold>=threshold2:
counter2=counter2+1
elif threshold>=threshold1:
counter1=counter1+1
elif threshold<threshold1:#漏檢
counter0=counter0+1
以上這篇python:目標檢測模型預測準確度計算方式(基于IoU)就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





