溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
目錄:
(一)了解通配符和正則的作用
(二)通配符的使用
(三)正則表達式的使用
(四)擴展正則表達式的使用
(一)了解通配符和正則的作用
(1.1)在我們日常的工作中,我們都會使用到通配符或者正則表達式。通配符是一種特殊語句,主要有星號(*)和問號(?),用來模糊搜索文件。當查找文件夾時,可以使用它來代替一個或多個真正字符;當不知道真正字符或者懶得輸入完整名字時,常常使用通配符代替一個或多個真正的字符。正則表達式是計算機科學的一個概念,正則表達式通常被用來檢索、替換那些符合某個模式的文本,正則表達式是對字符串操作的一種邏輯公式,就是用事先定義好的一些特定字符、及這些特定字符的組合,組成一個“規則字符串”,這個“規則字符串”用來表達對字符串的一種過濾邏輯。
(1.2)不管是通配符還是正則表達式,其功能都是實現模糊匹配,用來匹配某一類東西,并不是匹配具體的某一個值。通配符一般用于shell中,正則表達式一般用于其他語言。
(二)通配符的使用
(2.1)首先第一個是“[]”中括號[list],匹配的是list中的任意單一字符。例如a[xyz]b,a與b之間必須也只能有一個字符,但只能是x或y或z,如:axb,ayb,azb
(2.2)第二個是“[c1-c2]”,用來表示字符的范圍,匹配c1-c2的任意單一字符,如[0-9]或[a-z]。例如“a[0-9]b”表示的是0到9之間必須也只能有一個字符,如:a0b、a1b、a2b、a3b、a4b、a5b、a6b、a7b、a8b、a9b
注意:如果我們需要匹配的是單個字母,且不分大小寫,則我們可以使用“[a-zA-Z]”來進行表示。
(2.3)第三個是“[!c1-c2]或[^c1-c2]”,匹配的是不在c1-c2的任意字符。例如a[!0-9]b,a[^0-9]b表示a與b之間只有一個字符,并且不是數字0-9之間的字符,符合要求的有:acb、adb
(2.4)示例:我們在vms002主機上創建一個rh224目錄,然后在rh224目錄中創建相關的文件:11111、a111、a_111、a22、lwang、lWang、rh224。接著我們查詢第一個字符時a到z之間的,第二個字符是非數字的,后面的字符都是任意的。
# mkdir rh224
# touch 11111 a111 a_111 a22 lwang lWang rh224
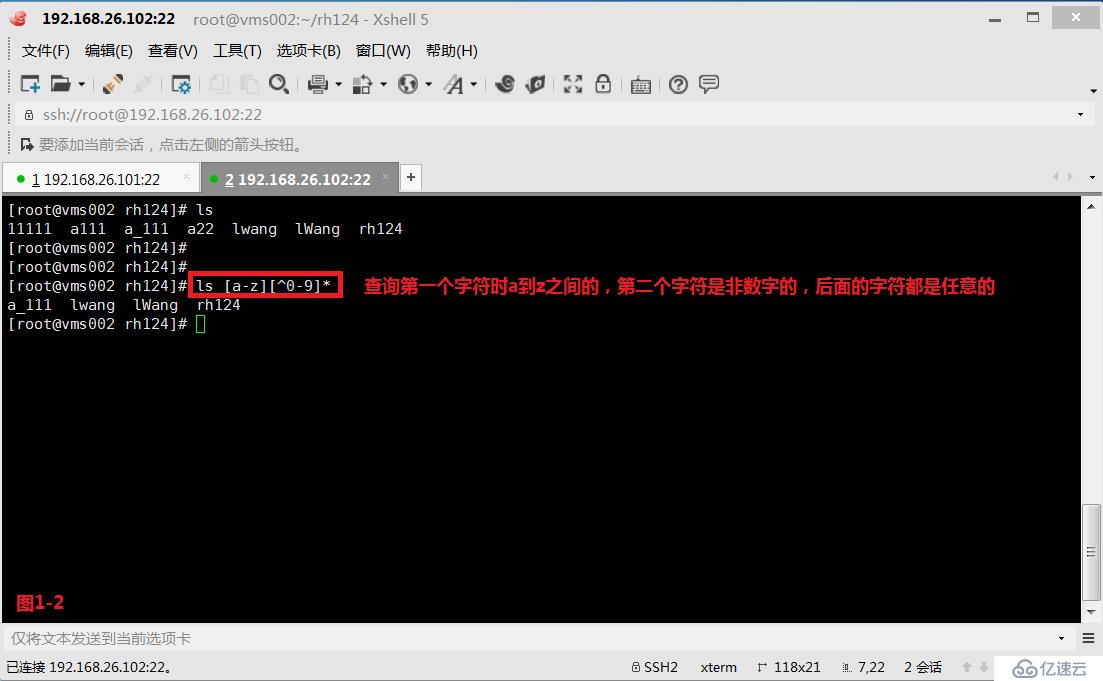
# ls [a-z][^0-9]*---查詢第一個字符時a到z之間的,第二個字符是非數字的,后面的字符都是任意的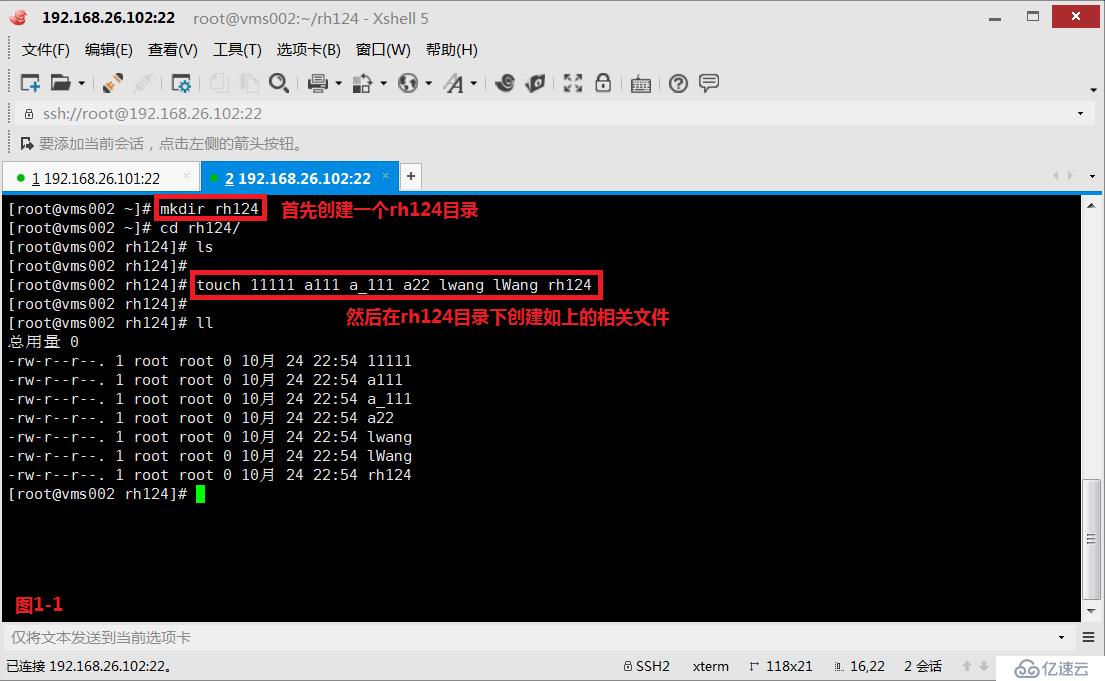
(2.5)示例:接著我們的需求是在rh224目錄下找到格式為第一個字符是a到z之間,第二個字符是a或者“-”或者z三個字符中的任意一個,后面的字符是任意的。這樣我們就可以符合要求的文件名a-1
# touch a-1
# ls [a-z][a-z]*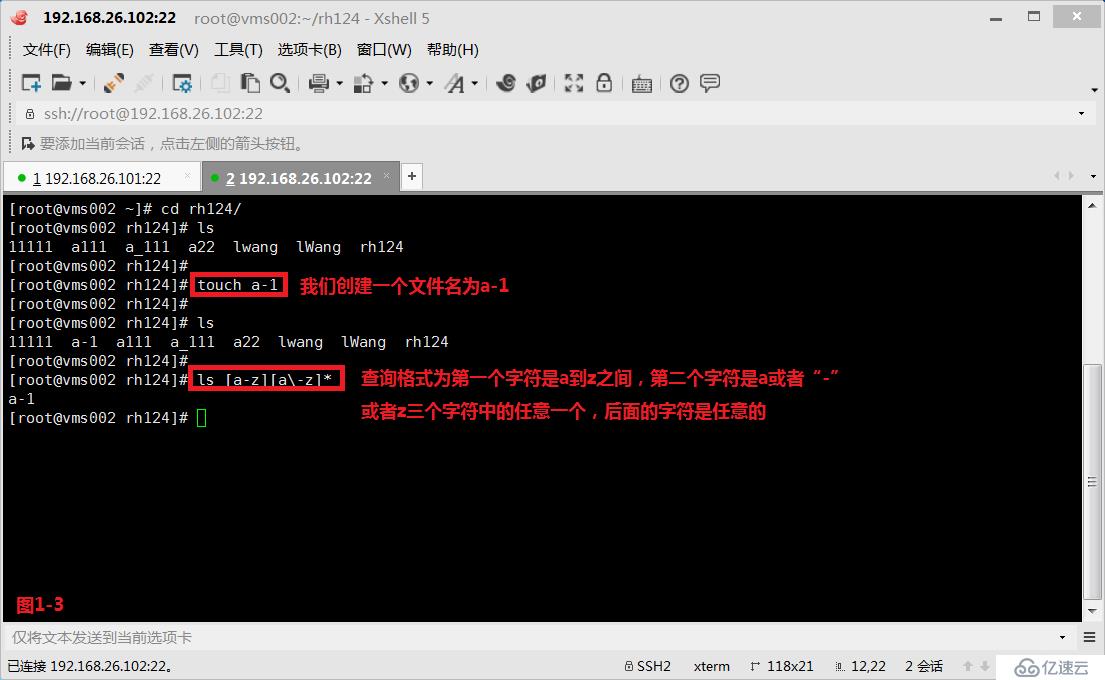
(2.6)第四個是精確指定字符的大小寫“[[:upper:]]”、“[[:lower:]]”,由于我們使用[a-z]的時候可能會匹配出a到z和A到Z之間的字符,大小寫并不能精確匹配,所以我們可以使用“[[:upper:]]”表示純大寫的字符,我們可以使用“[[:lower:]]”表示純小寫的字符。
# ls [[:upper:]]*---查詢所有純大寫字目開頭的文件名
# ls [[:lower:]]*---查詢所有純小寫字母開頭的文件名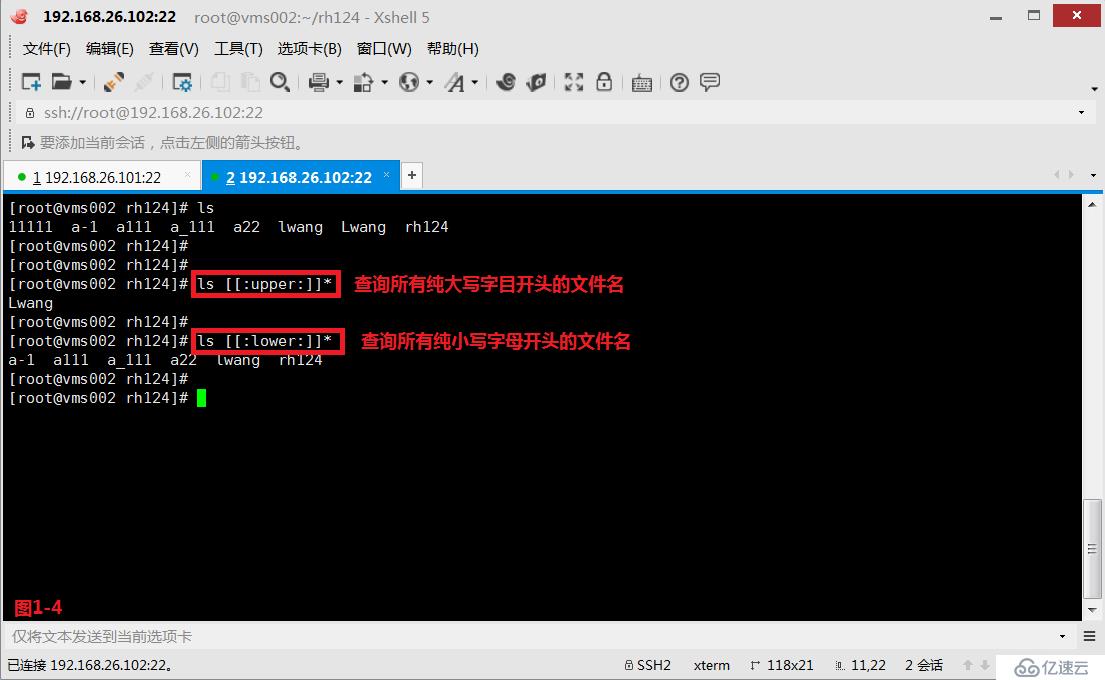
(2.7)當然第四個精確指定字符中還是有其他表示特定字符的方式的:“[[:alpha:]]”表示的是只匹配字母,“[[:alnum:]]”表示的是匹配字母和數字,“[[:digit:]]”表示的是匹配純數字。
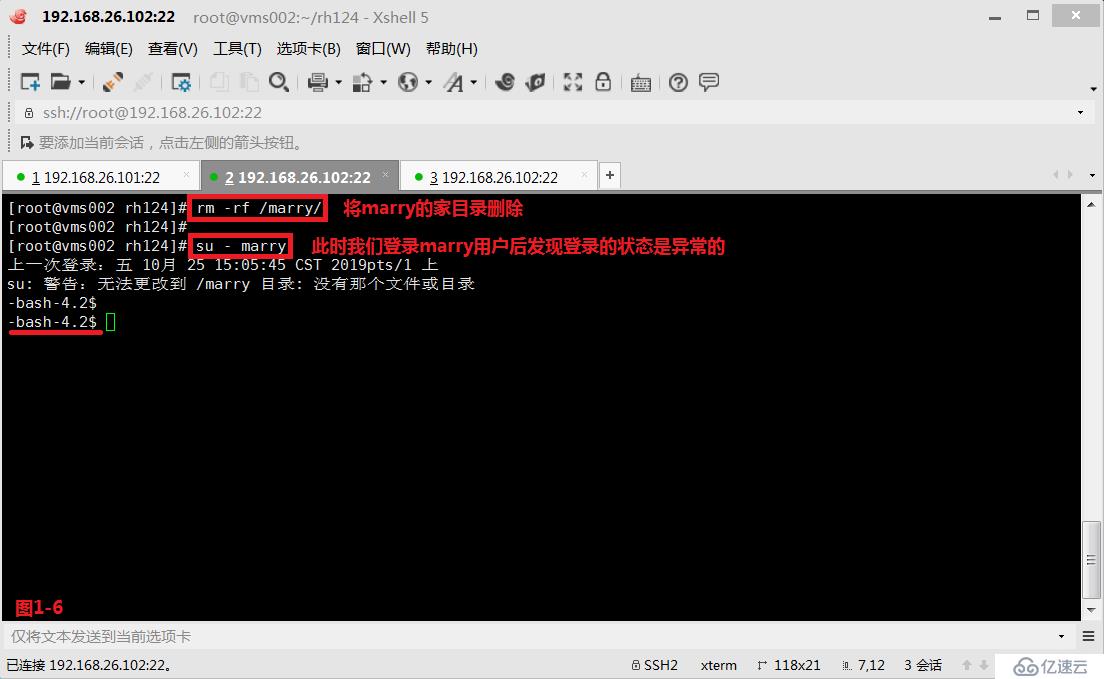
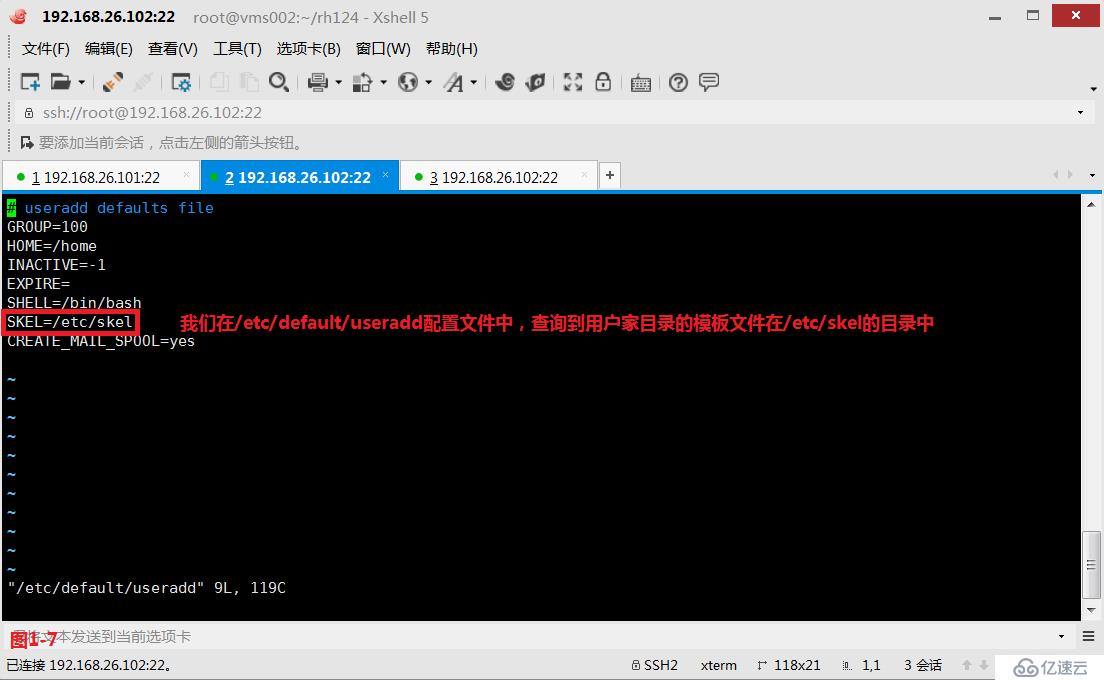
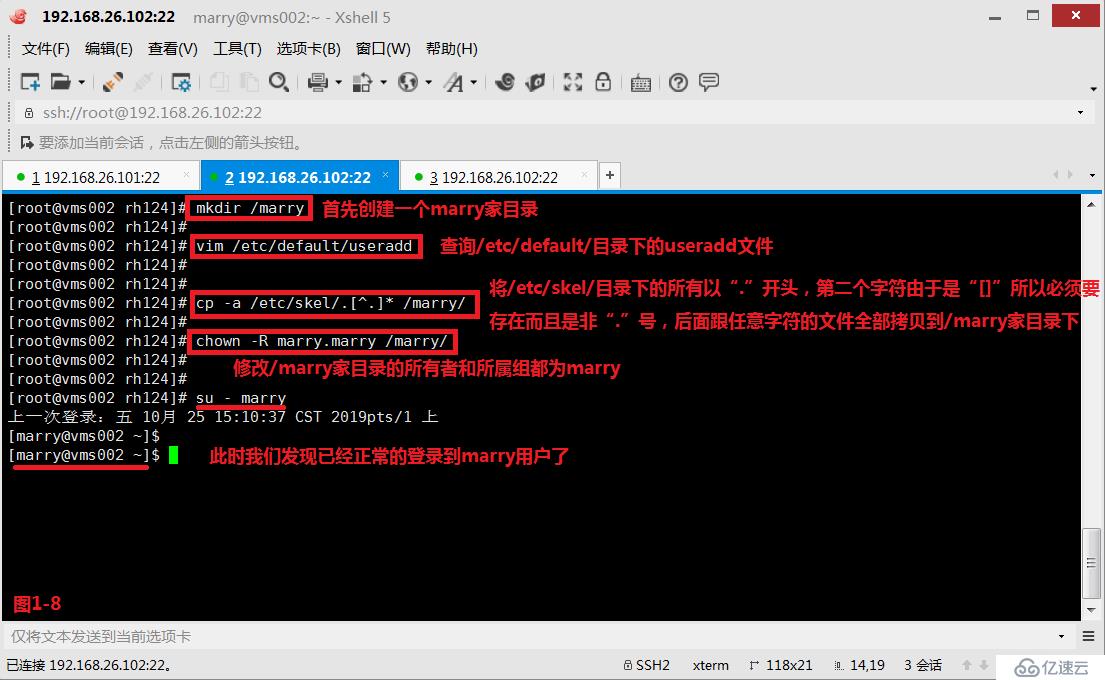
(2.8)示例:現在我們的系統中沒有marry用戶,我們首先創建一個marry用戶,并且指定在根下創建marry的家目錄(圖1-5)。然后我們將marry家目錄刪除,此時我們切換到marry用戶后發現由于沒有家目錄,所以切換后是異常的狀態(圖1-6),此時我們在/etc/default/useradd配置文件中,查詢到用戶家目錄的模板文件在/etc/skel的目錄中(圖1-7),我們將/etc/skel中的所有模板文件都拷貝到marry家目錄下,并修改了屬主和屬組的相關信息,此時便可以正常的進行marry用戶的切換了(圖1-8)。
# useradd -d /marry marry---創建一個marry用戶,并且指定在根下創建marry的家目錄
# rm -rf /marry/---刪除marry的家目錄
# vim /etc/default/useradd---查詢/etc/default/目錄下的useradd文件
# cp -a /etc/skel/.[^.]* /marry/---將/etc/skel/目錄下的所有以“.”開頭,第二個字符由于是“[]”所以必須要存在而且是非“.”號,后面跟任意字符的文件全部拷貝到/marry家目錄下,skel表示骨架、框架(圖1-8)
# chown -R marry.marry /marry/---修改/marry家目錄的所有者和所屬組都為marry(圖1-8)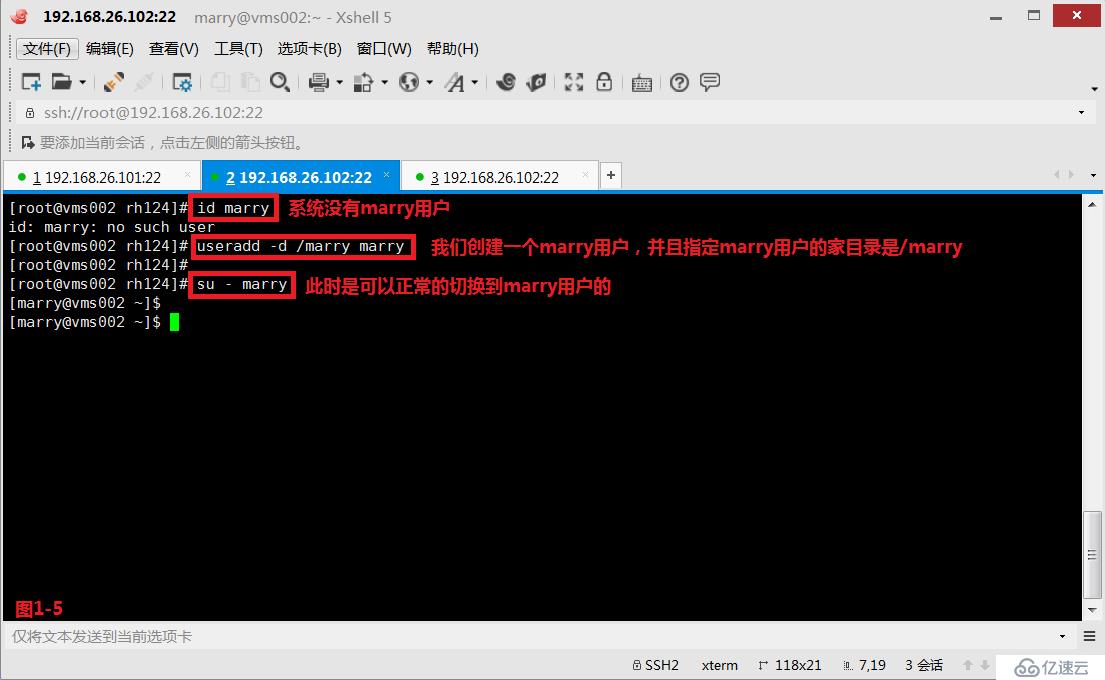
(2.9)第五個是“?”問號,匹配的是任意一個字符。例如在rh224目錄中,我們查詢“[a-z]????”,表示的是查詢第一個字符是字母構成,后面會有四個任意的字符構成的文件名。
注意:“?”問號是不能匹配到表示隱藏文件的“.”點號的。即表示如果現在系統中有“.aa”文件,我們使用“???”是不能匹配出這個隱藏文件的,如果我們想要匹配出這類隱藏文件則應該開啟全局通配符處理。
# ls [a-z]????---查詢第一個字符是字母構成,后面會有四個任意的字符構成的文件名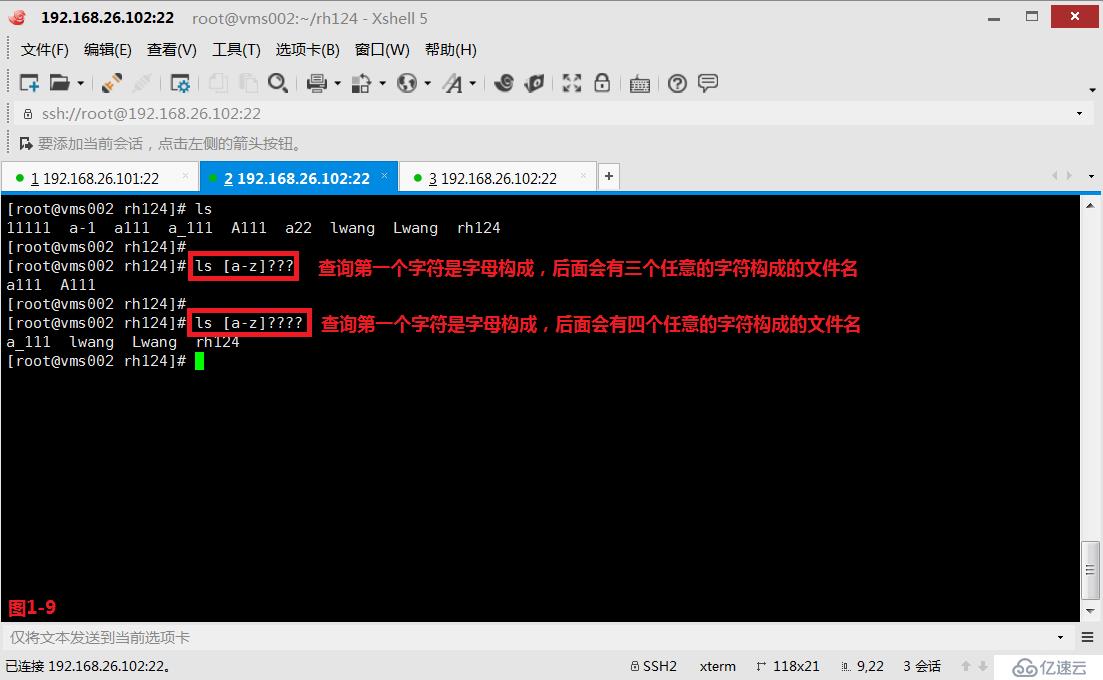
(2.10)第六個是“*”星號,表示匹配任意長度的任意字符。例如我們將所有文件名以a字母開頭,且后面是任意字符的文件都刪除掉
# touch aaa bb cc aa2---創建如下的四個文件
# rm -rf a*---將所有文件名以a字母開頭,后面是任意字符的文件都刪除掉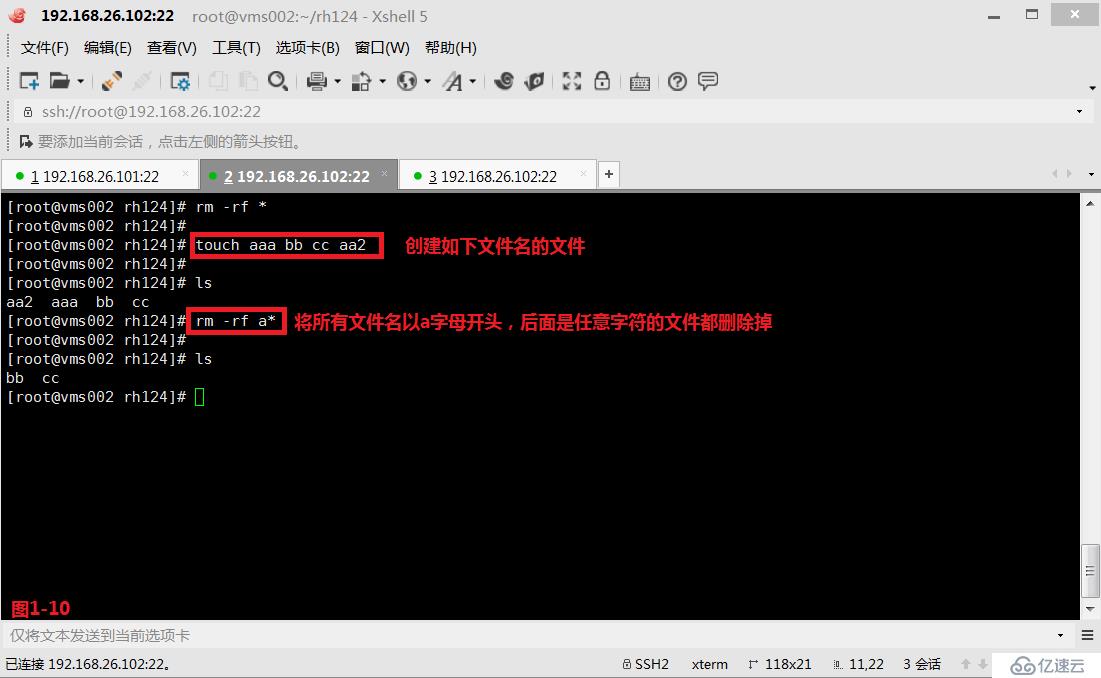
(2.11)第七個是“\”反斜線,表示轉義符,有時候我們在當前系統中安裝vsftp軟件的時候我們可能會使用“# yum install vsftp*”進行安裝,但是由于我們在執行系統命令的時候,首先是在shell進程中運行然后才到達YUM倉庫中去進行相關的軟件包查找工作。即我們在執行“vsftp*”的時候,shell會首先對“vsftp*”進行shell解析,查找當前目錄中是否有符合“vsftp*”格式的文件,如果現在我們的當前目錄中存在著一個文件vsftp123,則此時shell會將“vsftp*”解析成“vsftp123”,然后再到YUM倉庫中去查找“vsftp123”的軟件包進行安裝,而這樣的情況并不是我們所希望的。所以我們在shell中執行安裝軟件包的命令時,一般是建議使用轉義符“# yum install vsftp\*”這樣的格式進行安裝是比較好的,這樣就可以防止shell對我們所使用的通配符進行解析的情況產生。
# yum install vsftp\*---使用轉義符對通配符進行轉義,防止shell對通配符進行解析
# yum install 'vsftp*'---也可以使用單引號來進行轉義,防止shell對通配符進行解析
(2.12)需要注意的是,我們在創建文件的時候,文件名是不可能包含“/”的,因為有“/”就是代表創建了一個目錄。
# touch rh224/cc---此時“rh224/cc”并不是表示一個文件名,而是表示在rh224/目錄下創建一個cc文件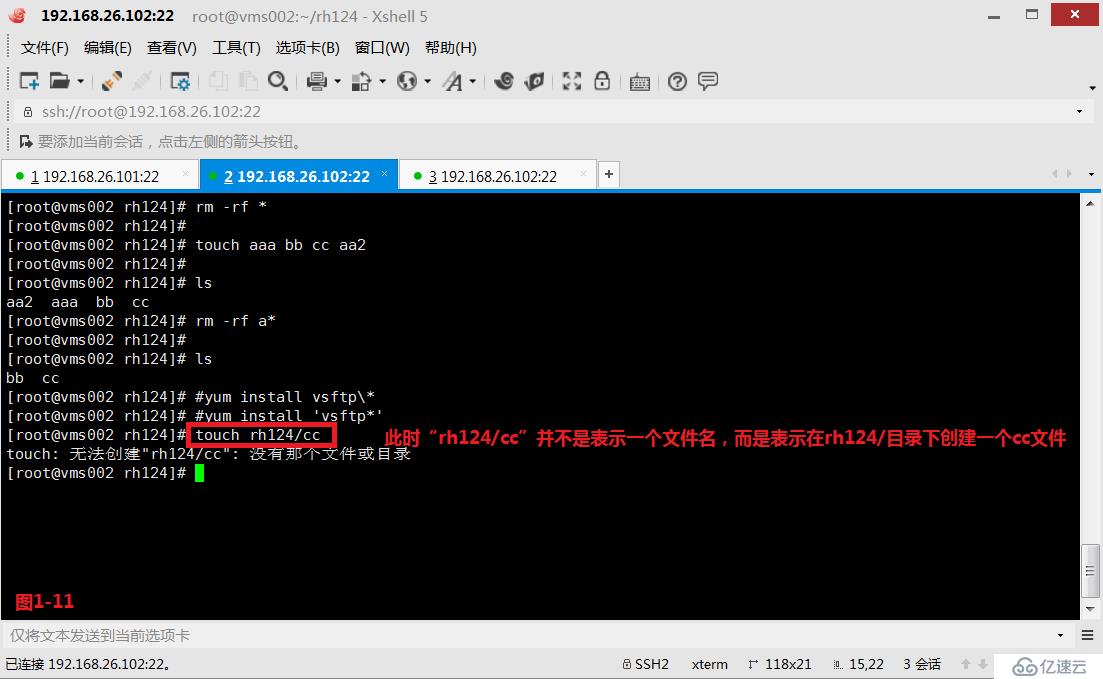
(三)正則表達式的使用
(3.1)正則表達式是用來匹配字符串的,針對文件內容的文本過濾工具,大都用到正則表達式,如vim、grep、awk、sed等。正則表達式和我們上面說的通配符實現的效果都是一樣的,是為了實現查詢信息的模糊匹配。
(3.2)第一個“^”表示開頭,例如我們先將/etc/passwd文件拷貝到當前目錄中,然后查詢passwd文件中以root字符開頭的行,此時可以使用“^”來進行標識。
# grep ^root passwd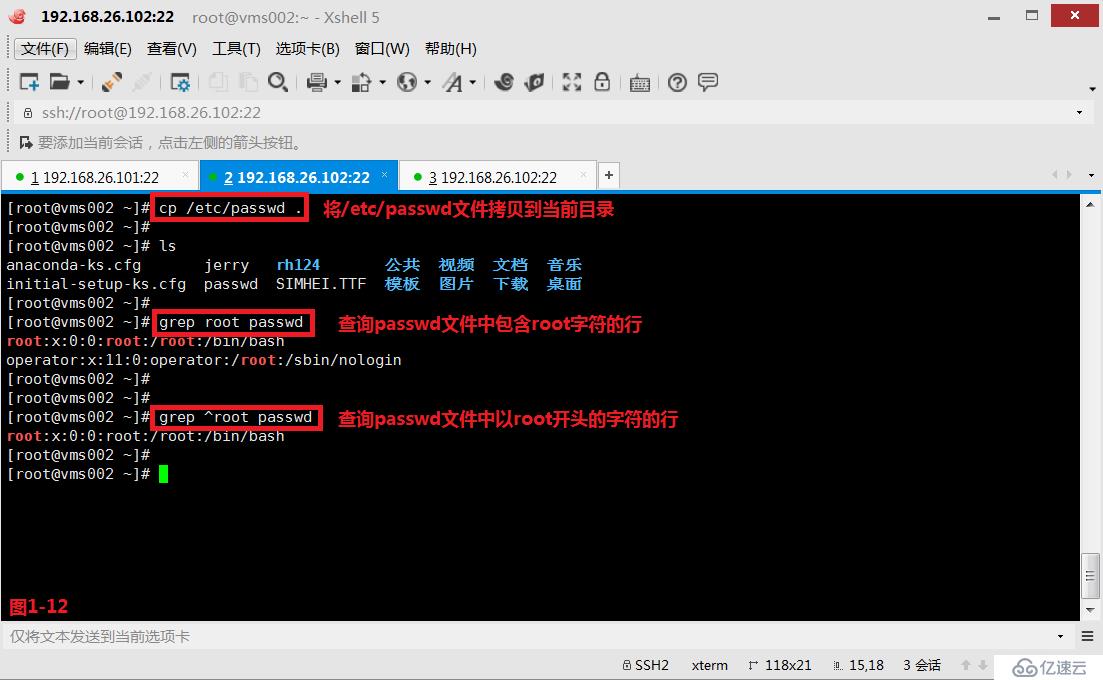
(3.3)第二個“$”表示行末,我們先將passwd文件中的相關行進行設計一下,然后查找每一行行末是“bash”字符的行。
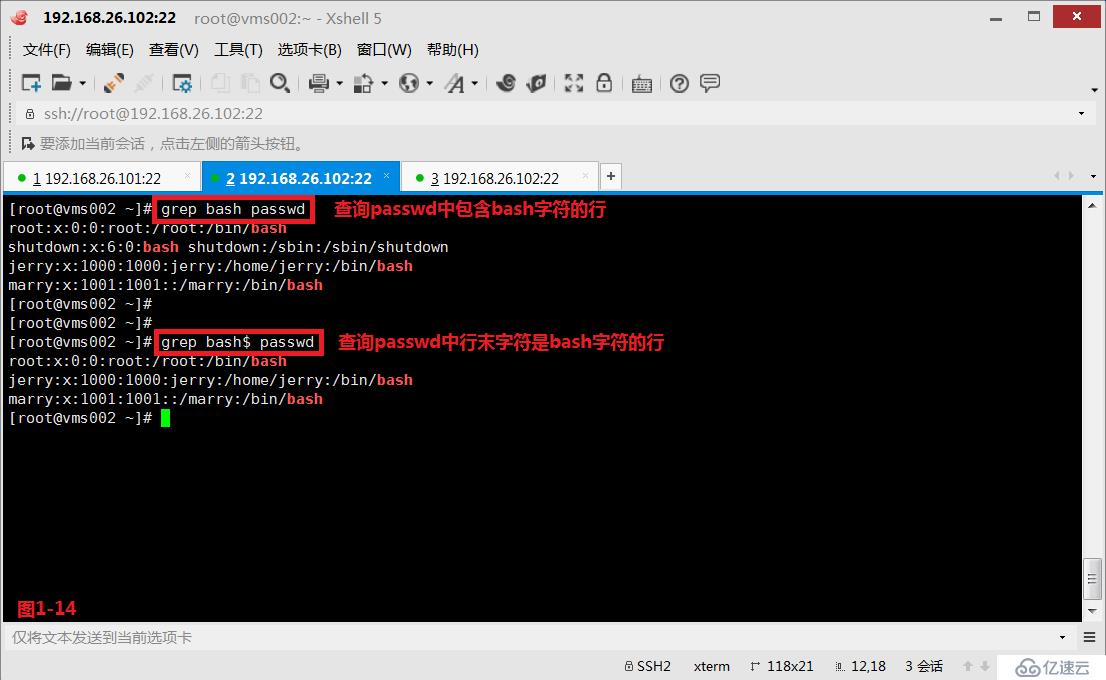
# grep bash$ passwd---查詢行末字符是bash字符的所有行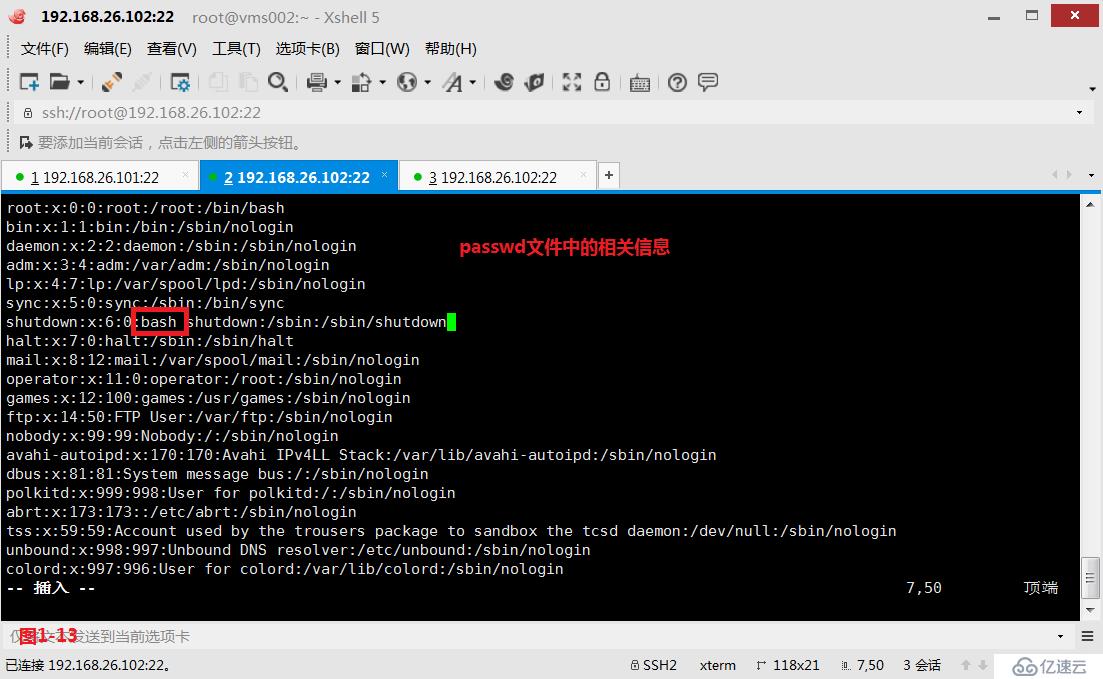
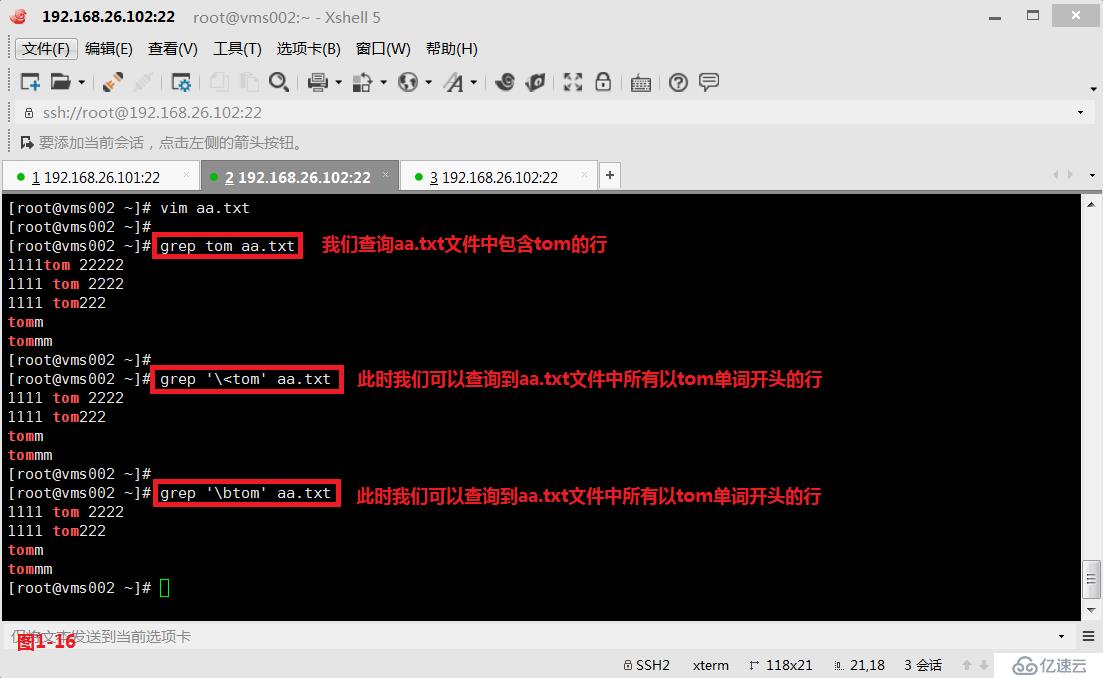
(3.4)第三個“\<”或者“\b”表示錨定的是單詞的開頭,我們先來創建一個aa.txt的文件,然后我們查詢“\<tom”以tom字符開頭的所有行。
# grep '\<tom' aa.txt---查詢以tom字符開頭的所有行
# grep '\btom' aa.txt---查詢以tom字符開頭的所有行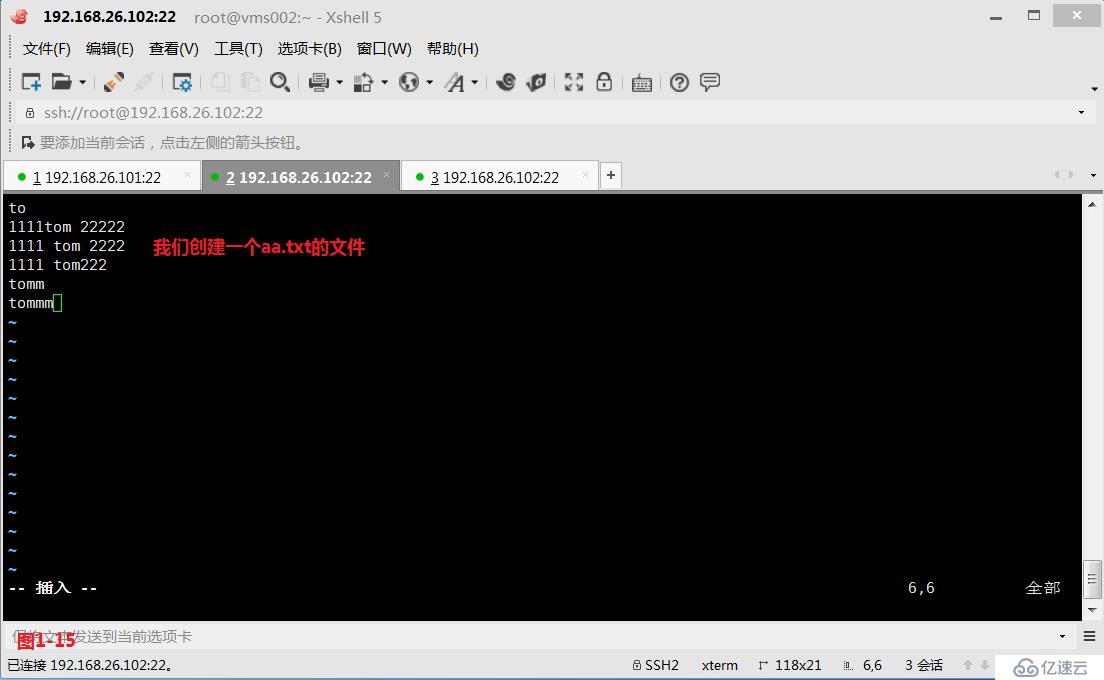
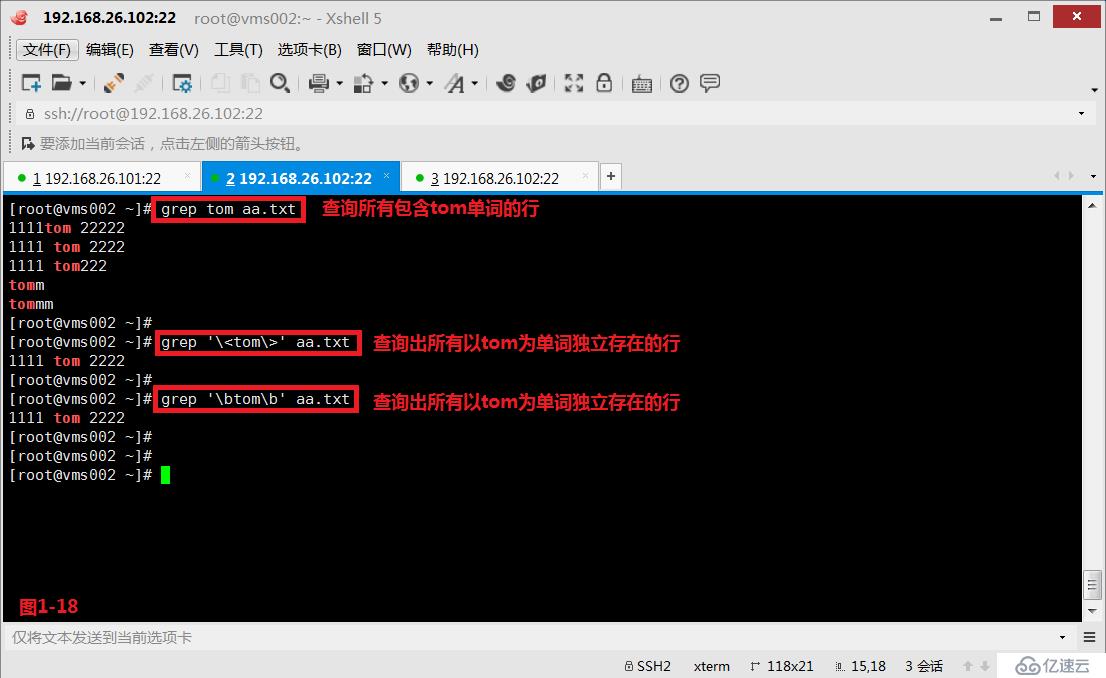
(3.5)第四個“\>”或者“\b”表示錨定的是單詞的末尾,在aa.txt文件中,我們查詢“tom\>”以tom字符結束的所有行(圖1-17)。如果我們希望查詢出所有以tom為單詞獨立存在的行時,我們可以同時使用“\<”和“\>”符號(圖1-18)。
# grep 'tom\>' aa.txt---查詢“tom\>”以tom字符結束的所有行
# grep 'tom\b' aa.txt---查詢“tom\b”以tom字符結束的所有行
# grep '\<tom\>' aa.txt---查詢出所有以tom為單詞獨立存在的行
# grep '\btom\b' aa.txt ---查詢出所有以tom為單詞獨立存在的行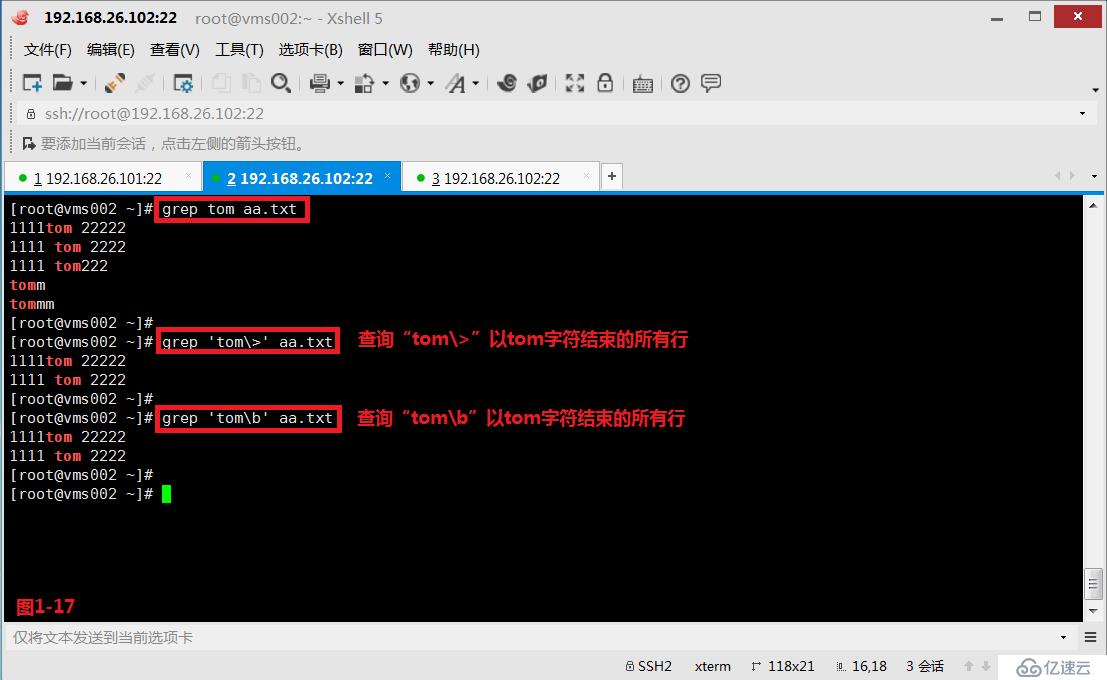
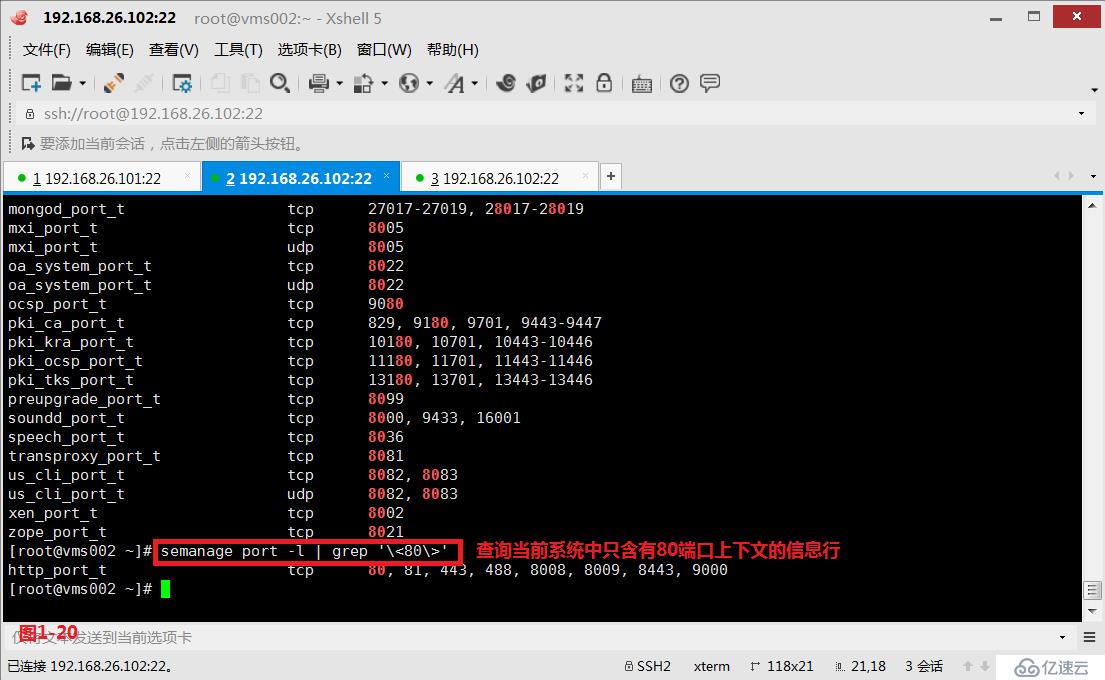
(3.6)示例:現在我們希望查詢SELinux中對端口設置的上下文信息,如果需要過濾具體的端口號的信息,則可以使用“\<\>”來指定獨立的單詞信息,例如過濾出只包含80端口上下文的行,如果我們只是使用“grep 80”過濾出的信息是不正確的(圖1-19),我們應該使用“grep '\<80\>'”才是正確的(圖1-20)。
# semanage port -l | grep 80---查詢當前系統中所有包含80端口上下文的信息
# semanage port -l | grep '\<80\>'---查詢當前系統中只含有80端口上下文的信息行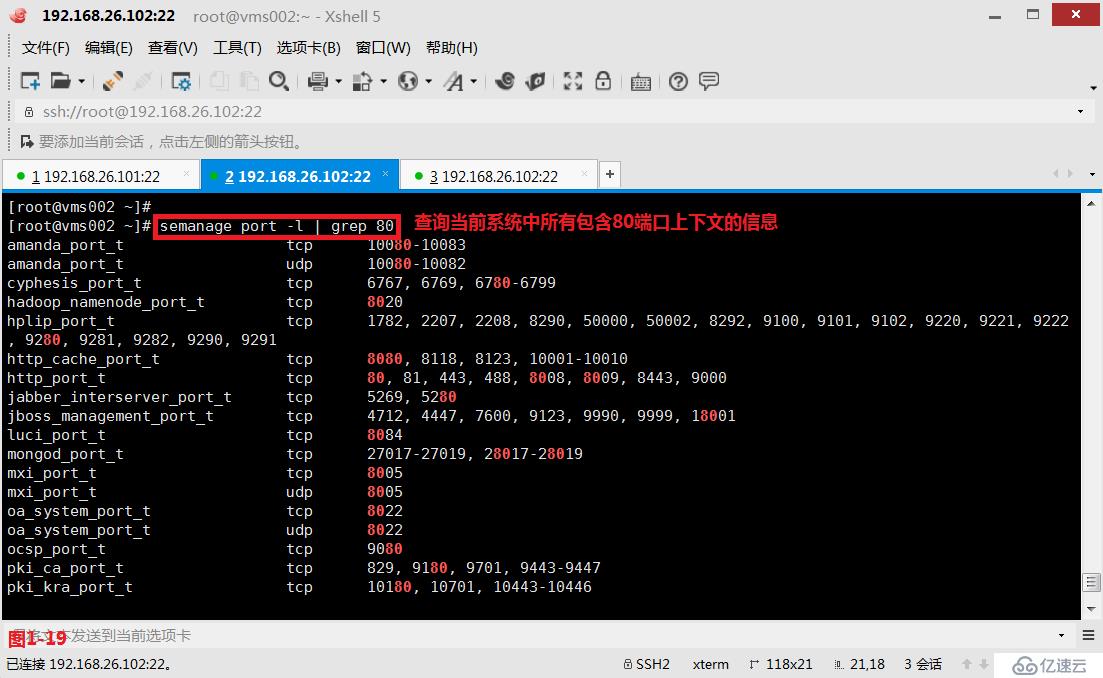
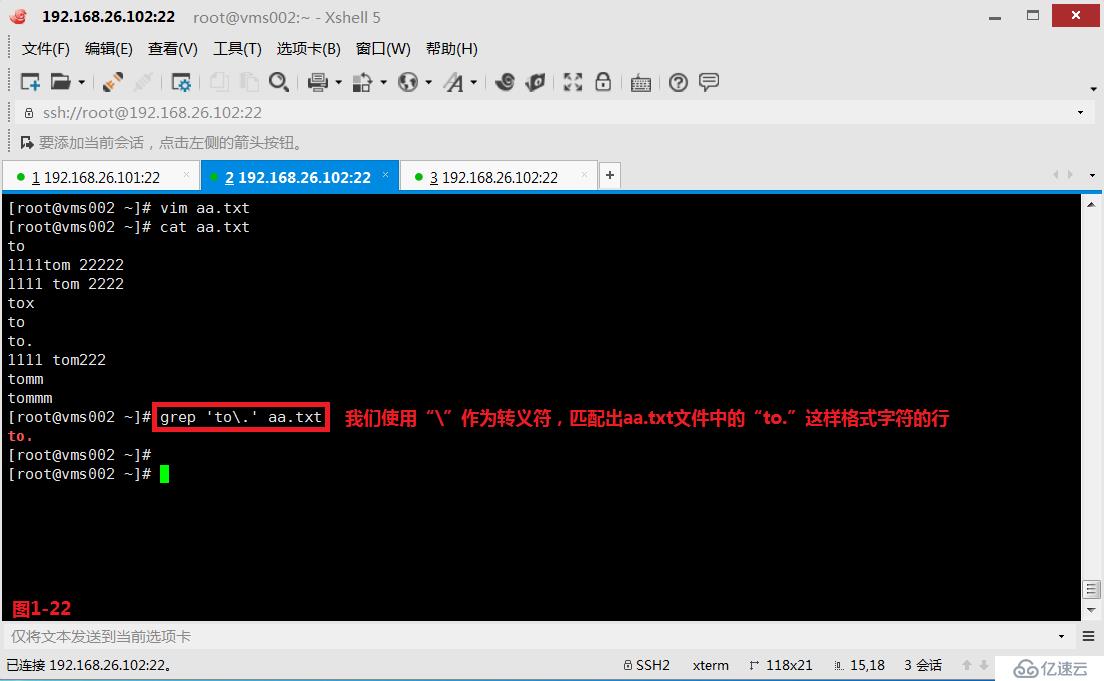
(3.7)第五個“.”表示單個任意字符,和通配符中的“?”問號的意義一致。例如我們想要匹配出aa.txt文件中to單詞后跟任意一個字符的所有符合要求的行(圖1-21)。如果我們希望“.”符號沒有模糊查詢的意思,就代表它本身的字符的意思,則我們可以使用“\”作為轉義符,這樣就可以直接查詢出包含“to.”字樣的行(圖1-22)。
# grep 'to.' aa.txt---查詢出所有符合to單詞后還會跟一個任意字符的行
# grep 'to\.' aa.txt---使用轉義符,直接查詢包含“to.”字符的行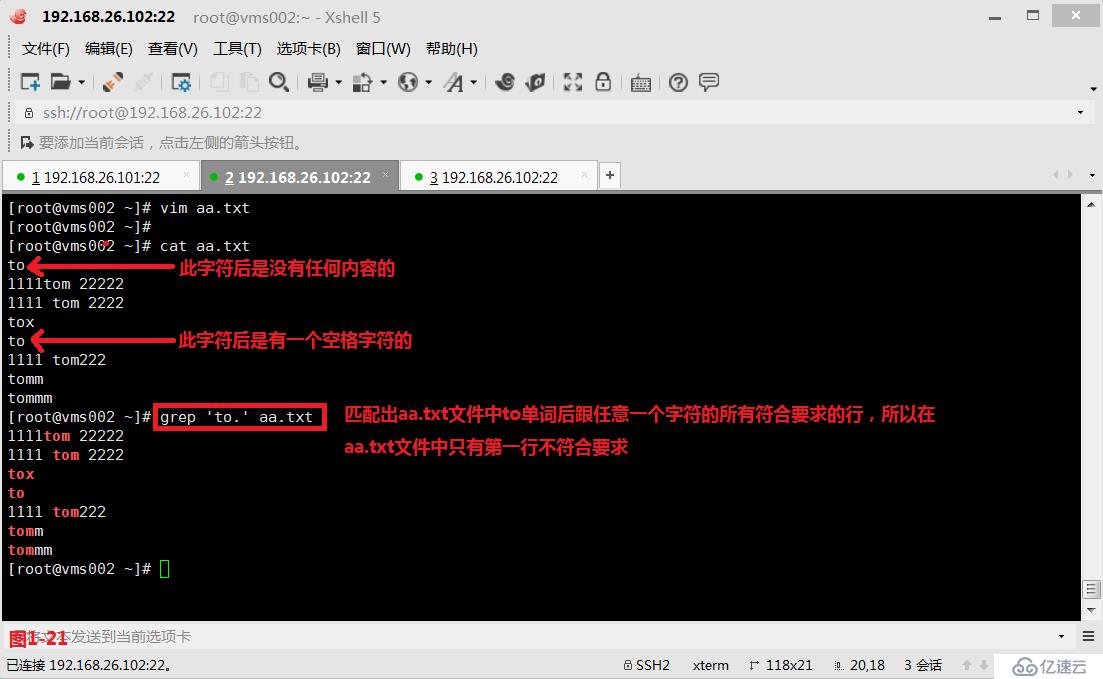
(3.8)第六個“[]”,表示的是匹配指定范圍內的任意單個字符。
(3.9)第七個“[^]”,表示的是匹配指定范圍外的任意單個字符。
(3.10)分組概念
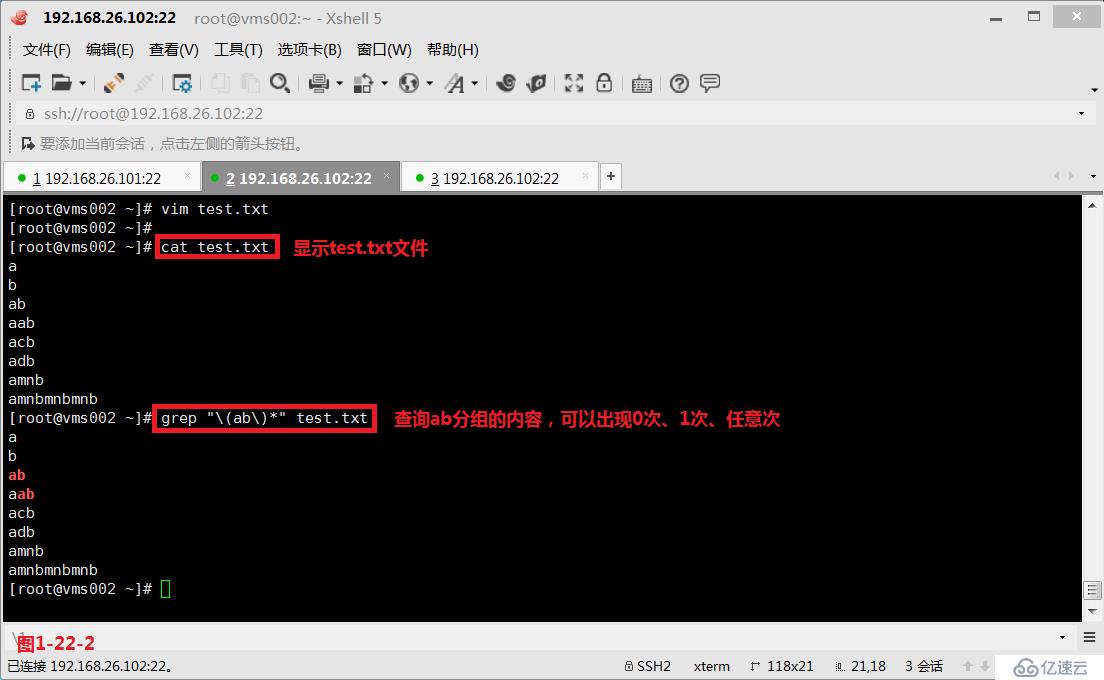
(3.10.1)第八個“\(\)”,表示的是分組。例如“\(ab\)*”表示ab單詞可以出現0次、1次或任意次。我們創建一個test.txt文件(圖1-22-1),然后我們使用“\(ab\)*”將符合條件的都篩選出來(圖1-22-2)。
# grep "(ab)*" test.txt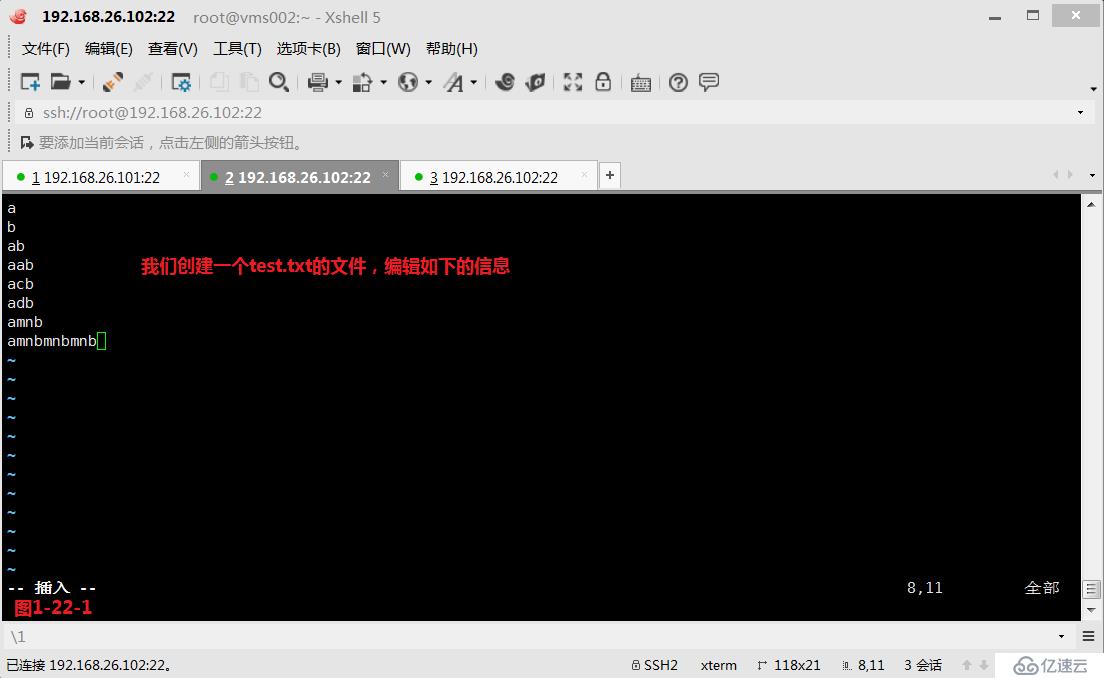
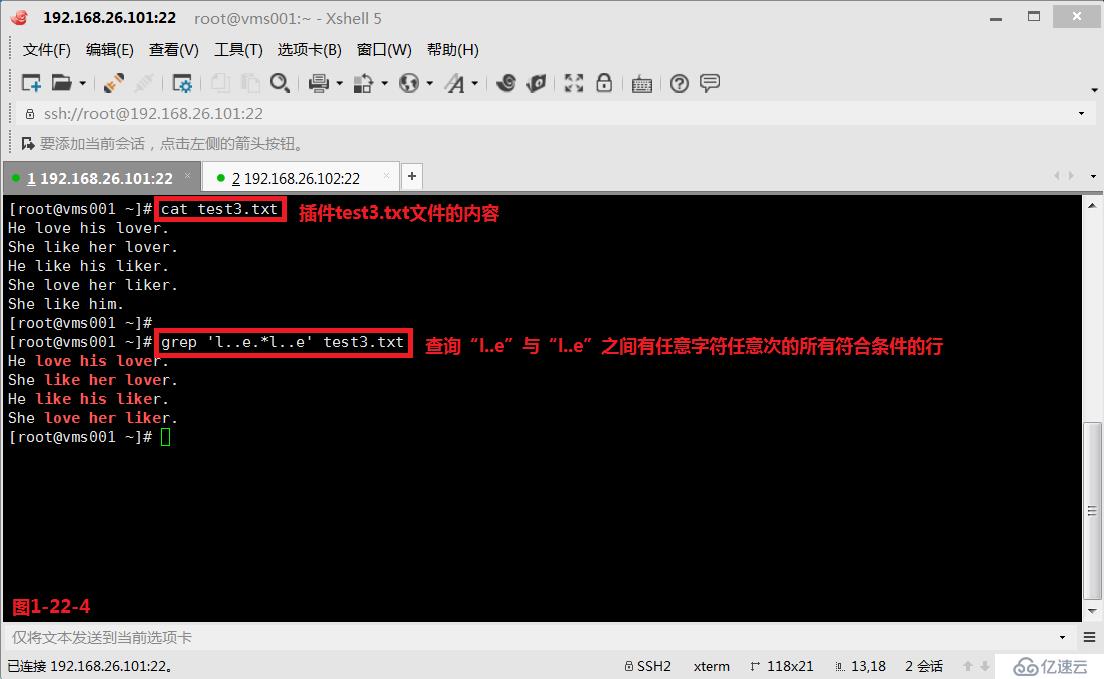
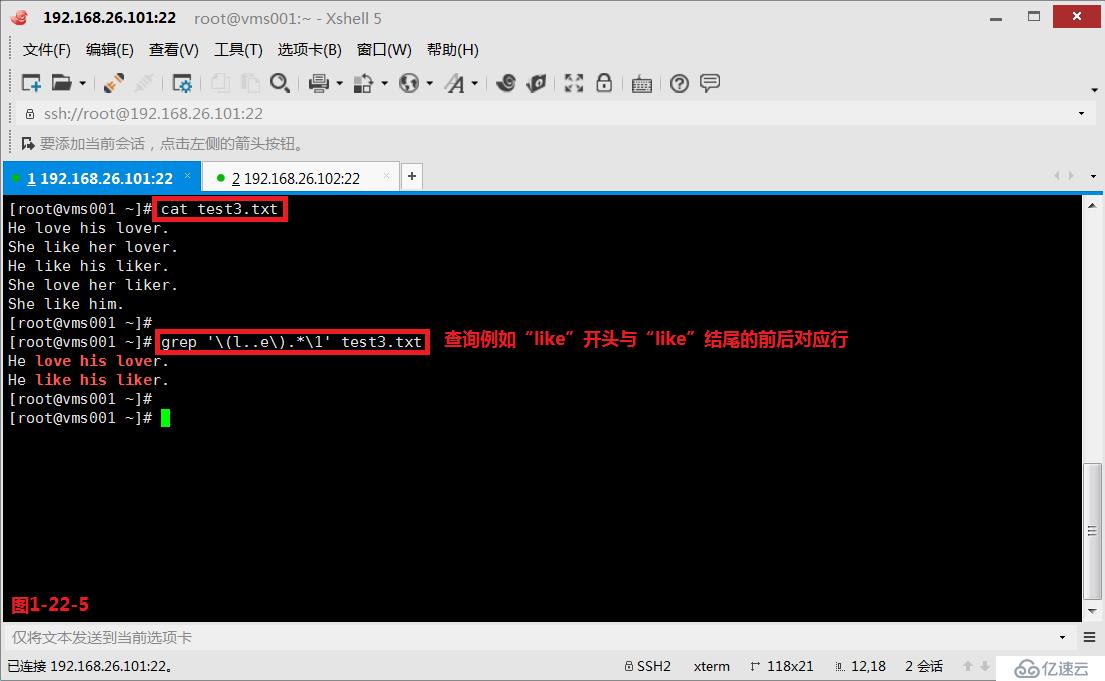
(3.10.2)我們創建一個文件test3.txt,然后編輯如下的內容,我們查詢“l..e”與“l..e”之間有任意字符任意次的所有符合條件的行,此時我們發現test3.txt文件中的第1行至第4行的內容都被篩選出來了(圖1-22-4)。此時我們如果希望出現的行中前后兩個字符是完全一致的才符合要求并顯示,即test3.txt文件中的第1行和第3行顯示出來,此時我們需要使用后項引用的方式來完成要求(圖1-22-5)。
分組:\(\)
后項引用:
\1:引用第一個左括號以及與之對應的右括號所包括的所有內容
\2:引用第二個左括號以及與之對應的右括號所包括的所有內容
\3:引用第三個左括號以及與之對應的右括號所包括的所有內容
# grep 'l..e.*l..e' test3.txt---查詢“l..e”與“l..e”之間有任意字符任意次的所有符合條件的行
# grep '\(l..e\).*\1' test3.txt---查詢例如“like”開頭與“like”結尾的前后對應行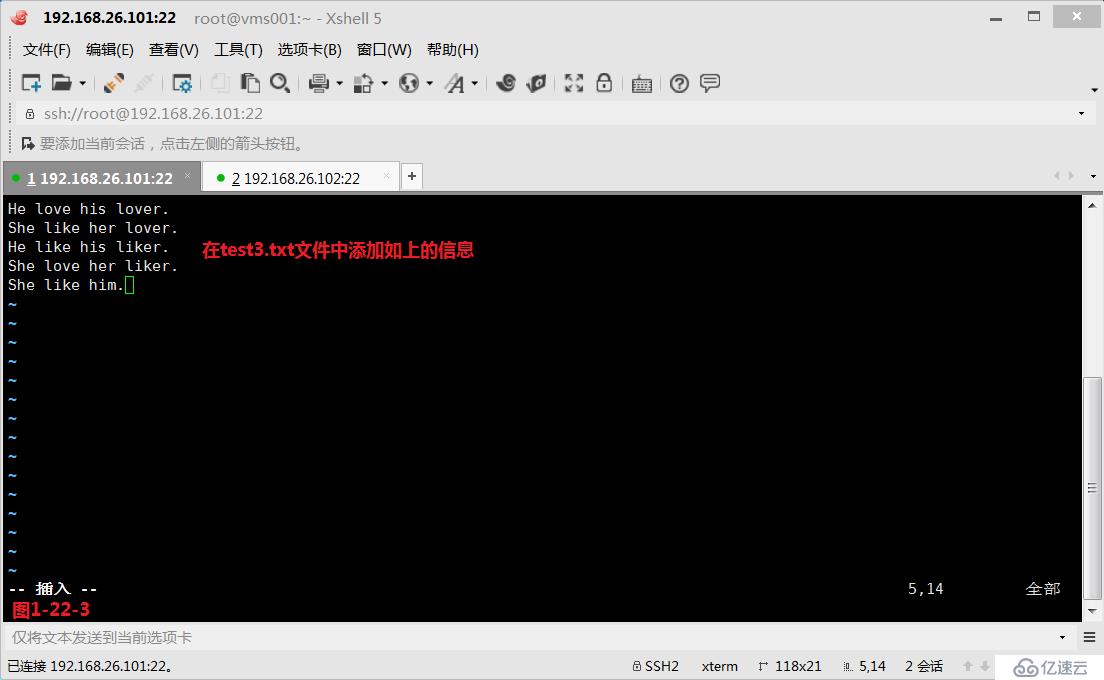
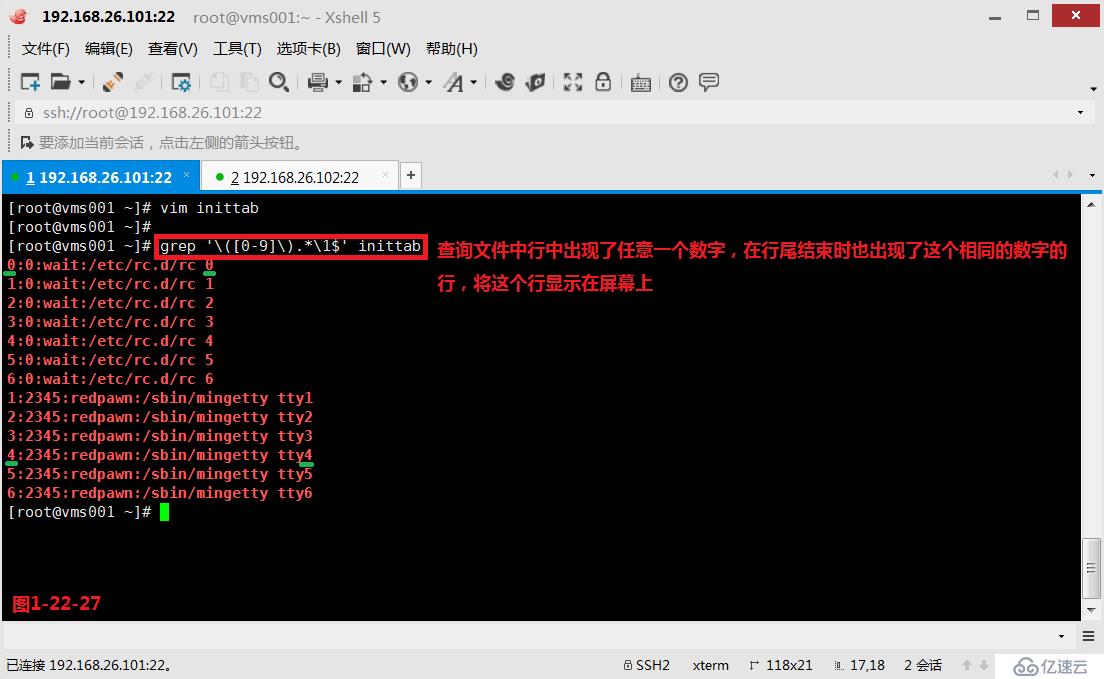
(3.10.3)示例:我們在當前目錄下創建一個inittab的文件,然后我們查詢文件中行中出現了任意一個數字,在行尾結束時也出現了這個相同的數字的行,將這個行顯示在屏幕上。
# grep '\([0-9]\).*\1$' inittab---其中“\([0-9]\)”表示行中出現的任意一個數字,“\1$”表示在行尾結束時也出現了這個相同的數字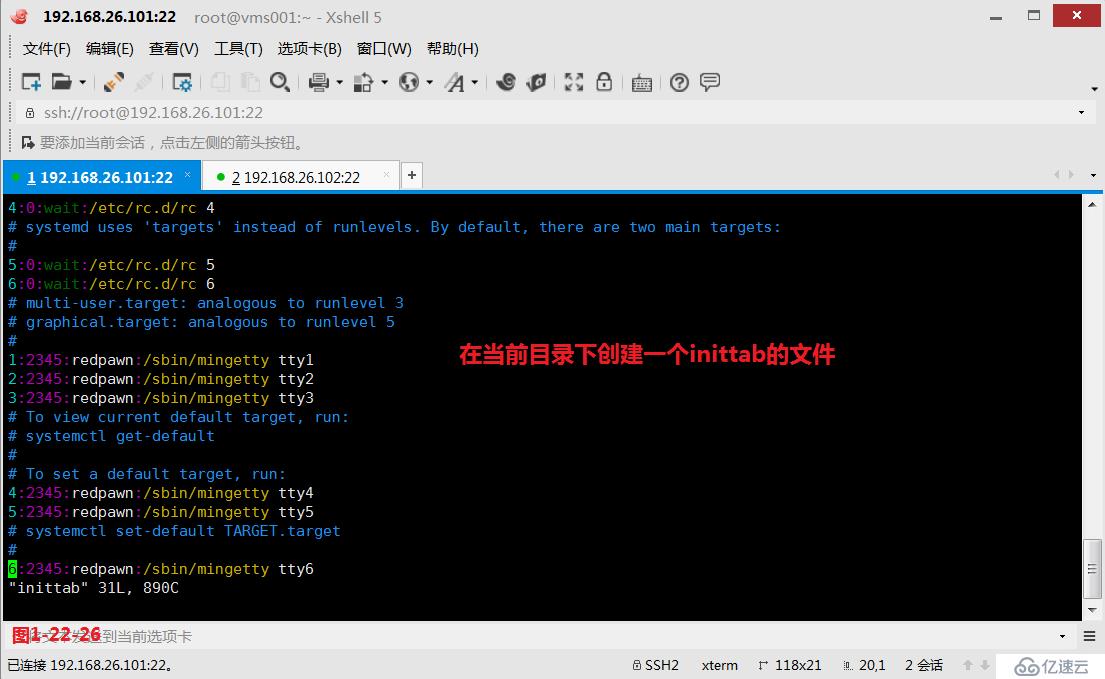
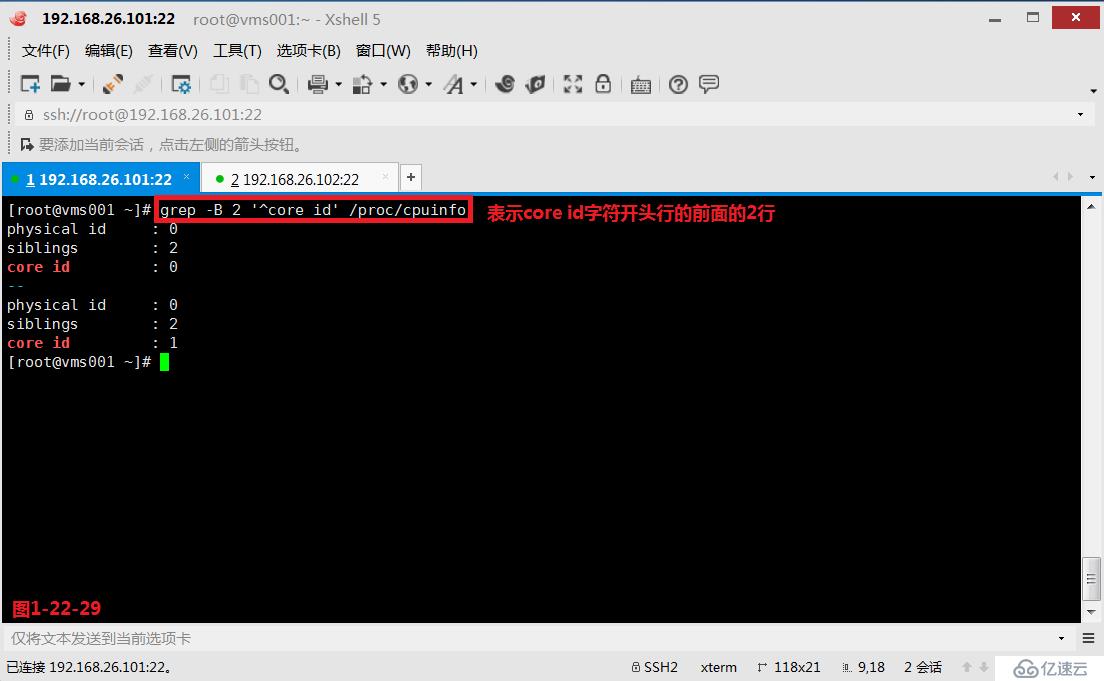
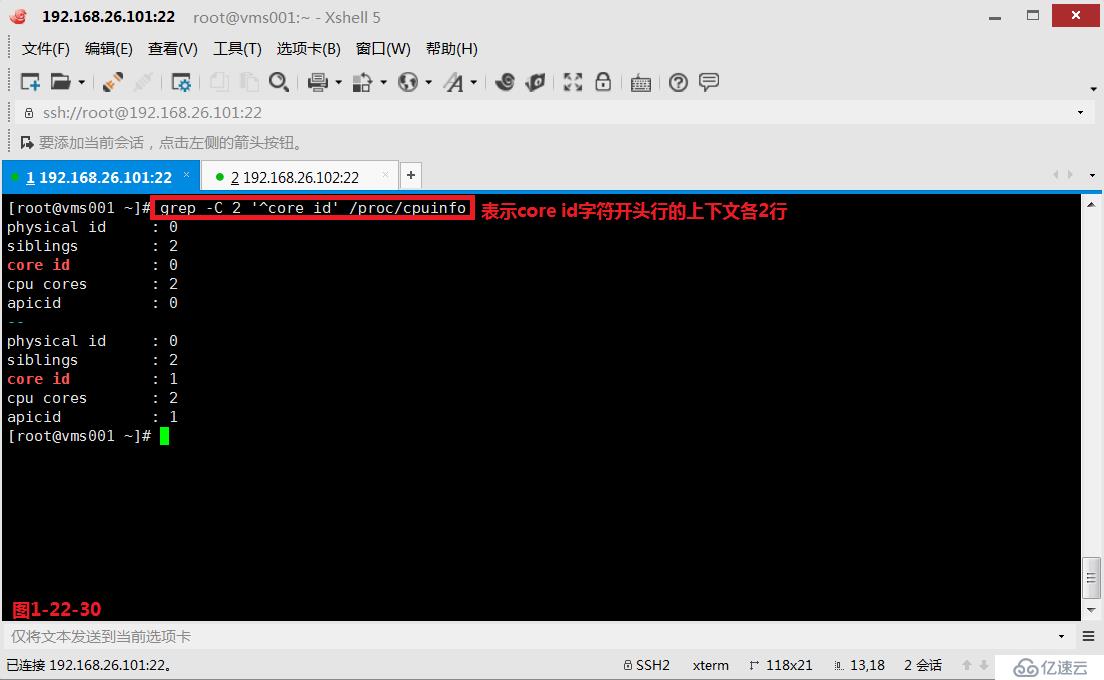
(3.11)我們在使用grep命令的時候可以使用“-A”、“-B”、“-C”參數,其中-A表示的是after后面,其中-B表示的是before前面,其中-C表示的是context上下文。
# grep -A 2 '^core id' /proc/cpuinfo---表示core id字符開頭行的后面的2行
# grep -B 2 '^core id' /proc/cpuinfo---表示core id字符開頭行的前面的2行
# grep -C 2 '^core id' /proc/cpuinfo---表示core id字符開頭行的上下文各2行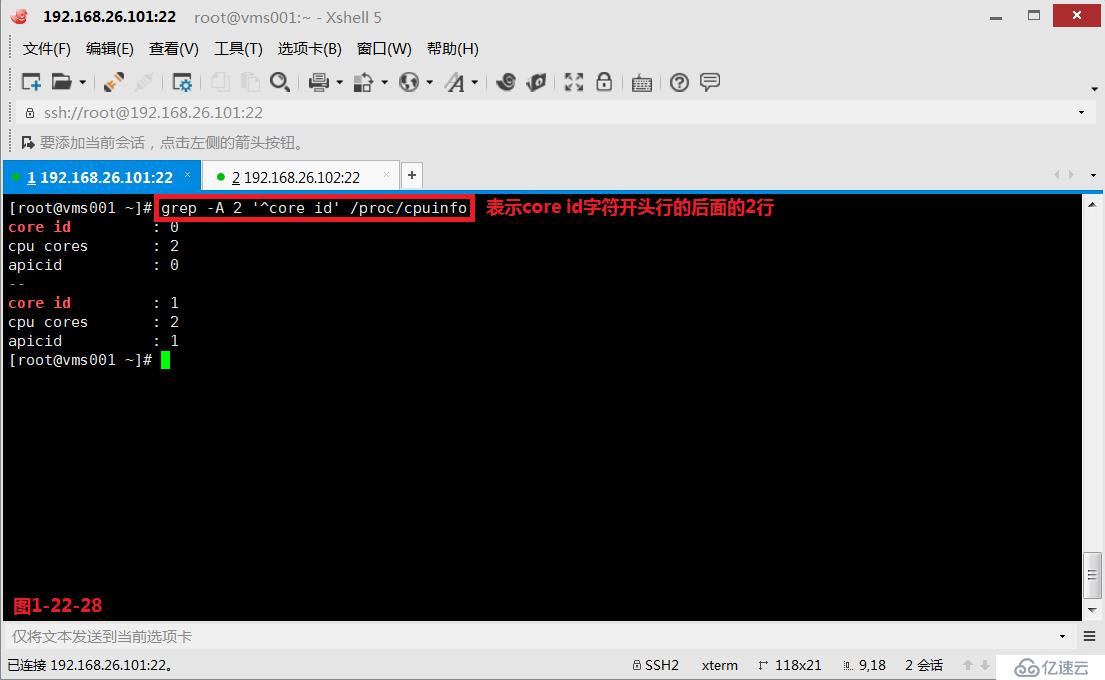
(四)擴展正則表達式的使用
(4.1)以上我們所使用的正則表達式在進行查詢的時候可以配合grep命令進行使用“grep 表達式 file”。不過有些正則表達式grep命令并不支持,此時我們應該使用“grep -E 表達式 file”或者“egrep 表達式 file”啟用擴展的正則表達式進行查詢。有時候還有一些正則表達式是擴展的正則表達式也解決不了的,此時我們應該使用“grep -P 表達式 file”即調用perl語言中的正則表達式進行查詢。分割線擴展正則表達式。
注意:egrep -o表示的是僅僅輸出查詢出的字符
(4.2)第一個“?”表示它前面出現的字符,出現0次或者1次。“to.?”表示的意思是to后會跟一個任意的字符,但是這樣任意的字符可能出現0次,也可能出現1次,所以此時aa.txt 文件中包括“to”在內的所有行都是符合要求的。此時由于使用的“?”問號,所以我們需要使用擴展的正則表達式egrep進行匹配查詢。
# egrep 'to.?' aa.txt---其中to后會跟一個任意的字符,但是這樣任意的字符可能出現0次,也可能出現1次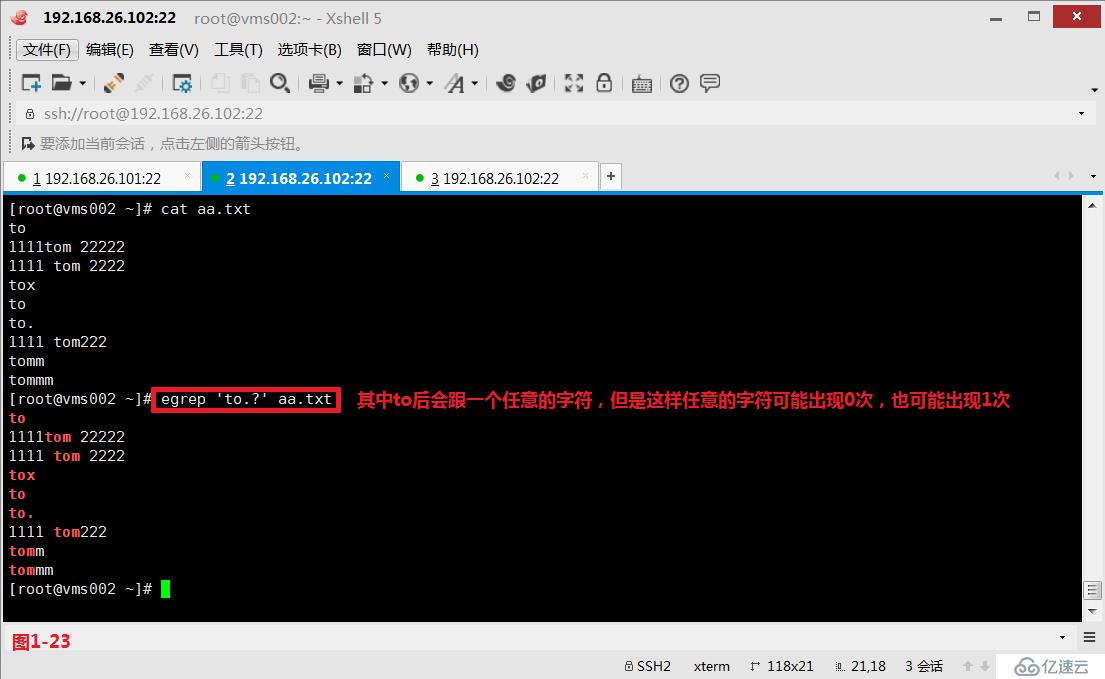
(4.3)第二個“+”表示它前面的字符出現1次或者多次。此時我們查詢“to.+”表示的意思是在to單詞后面有一個任意字符,同時這個任意字符出現可能是1次,也可能出現多次,所以在aa.txt文件中除了第一行不符合要求,其他的行都是符合要求的。同時我們需要使用擴展的正則表達式egrep進行匹配查詢。
# egrep 'to.+' aa.txt---也稱貪婪匹配,在to單詞后面有一個任意字符,同時這個任意字符出現可能是1次,也可能出現多次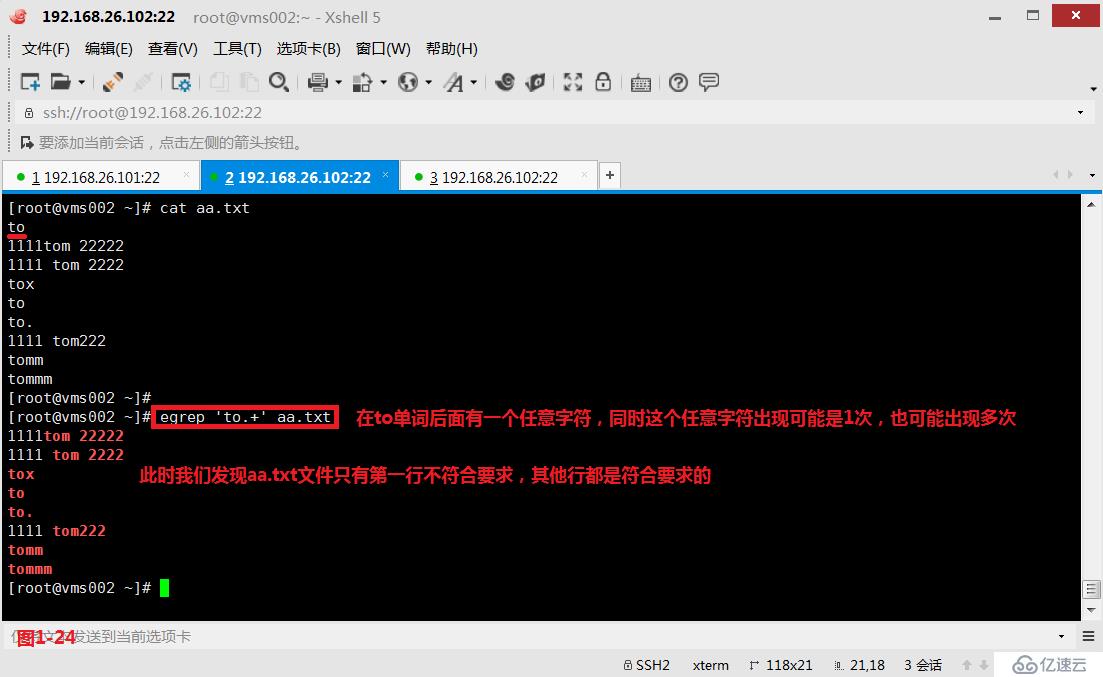
(4.4)第三個“*”表示它前面的字符出現任意次數。此時我們查詢“to.*”表示匹配的是to單詞后有一個任意字符,并且這個任意字符出現任意次,包括0次、1次、任意次。所以此時aa.txt文件中所有行都是符合匹配的要求的。同時我們需要使用擴展的正則表達式egrep進行匹配查詢。
# egrep 'to.*' aa.txt---查詢匹配to單詞后有一個任意字符,并且這個任意字符出現任意次,包括0次、1次、任意次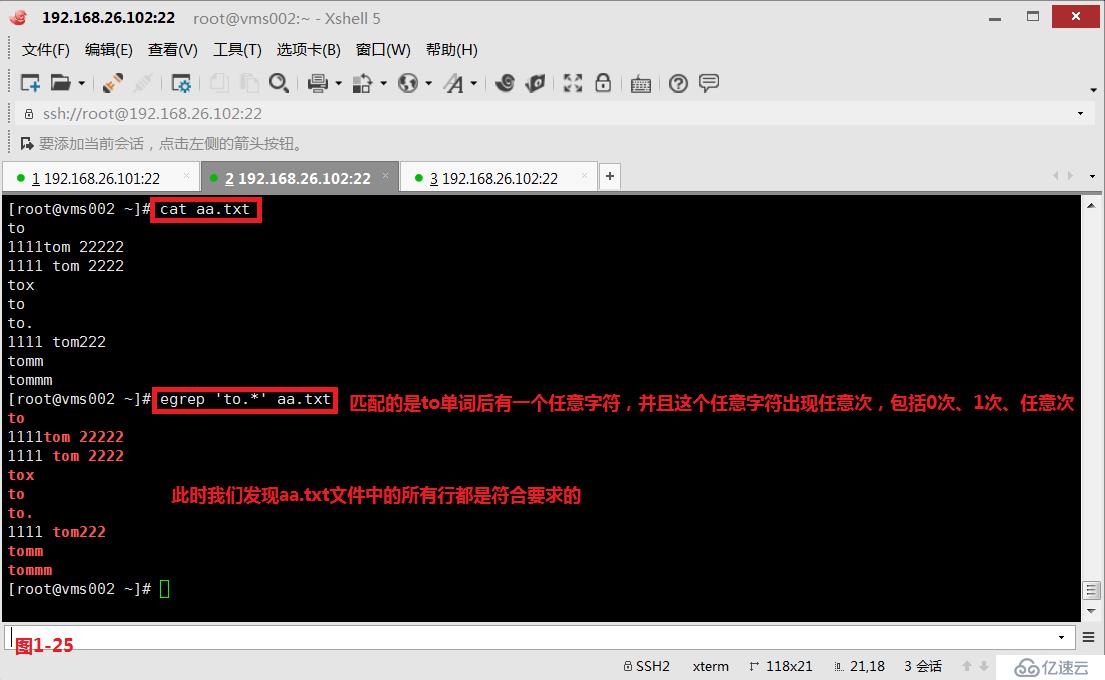
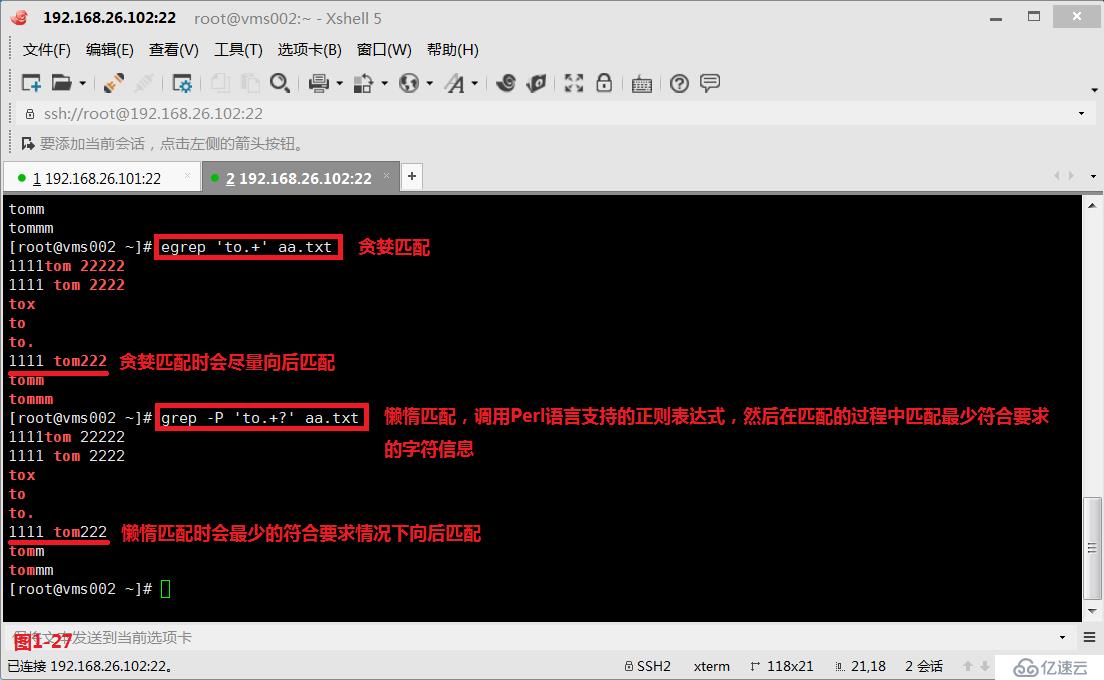
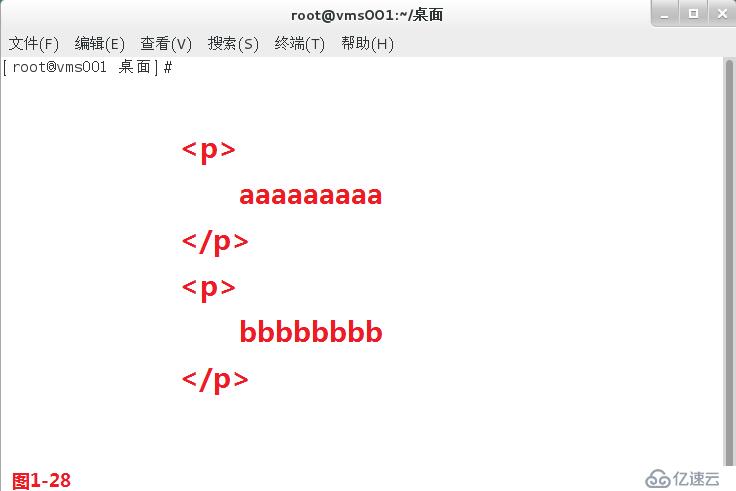
(4.5)在模式匹配的過程中我們有兩個概念,第一個是貪婪匹配,第二個是懶惰匹配,默認是工作在貪婪模式中。其中貪婪匹配表示的是盡可能多的向后面進行匹配,例如“to.+”表示的是to單詞后會有一個任意字符,并且這個任意的字符至少是1個,最多可以任意的個數,所以匹配的時候符合要求的行會盡可能的向后進行匹配,同時我們需要使用擴展的正則表達式egrep進行匹配查詢(圖1-26)。而懶惰匹配表示的是在符合要求的情況下盡可能少的向后進行匹配,例如“to.+?”表示的是to單詞后會有一個任意字符,“+”表示并且這個任意字符至少匹配一個,最多可以匹配任意的個數,“?”表示前面的部分可以出現0次或者1次,所以此時就會按照最少符合要求的情況進行懶惰匹配,同時我們需要使用擴展的正則表達式“grep -P”進行匹配查詢(圖1-27)。以上的應用也是非常廣泛的,有時候我們在網站進行信息抓取的時候我們希望從<p>標志位開始的抓取,到</p>標志位結束,此時如果我們使用貪婪匹配的模式進行抓取,那么我們抓取的信息便包含a和b兩段內容,如果我們使用懶惰匹配的模式進行抓取,那么我們抓取的信息就只會包含a段的內容(圖1-28)。
# egrep 'to.+' aa.txt---貪婪匹配,在to單詞后面有一個任意字符,同時這個任意字符出現可能是1次,也可能出現多次,同(3.9)
# grep -P 'to.+?' aa.txt---懶惰匹配,調用Perl語言支持的正則表達式,然后在匹配的過程中匹配最少符合要求的字符信息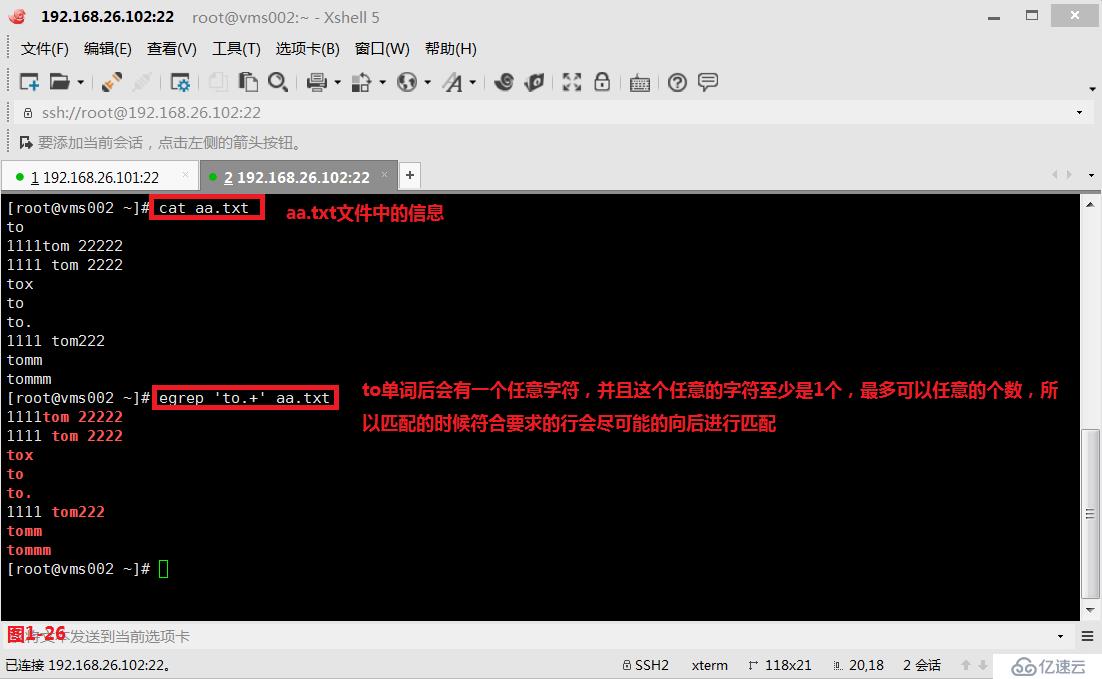
(4.6)第四個是在使用grep -P時的“{n,m}”,在使用常規grep時的“{n,m}”,表示的是匹配次數在n到m之間,包括邊界;其中grep -P時的“{n}”或者常規grep時的“{n}”表示必須匹配n次;grep -P時的“{n,}”或者常規grep時的“{n,}”表示匹配n次及以上。
# grep -P 'tom{2}' aa.txt---查詢m出現兩次的所有符合字段
# grep -P 'tom{2,}' aa.txt---查詢m出現次數在兩次及兩次以上的所有符合字段
# grep 'tom{2,}' aa.txt---查詢m出現次數在兩次及兩次以上的所有符合字段,由于使用的是常規grep,所以需要用“{2,}”表示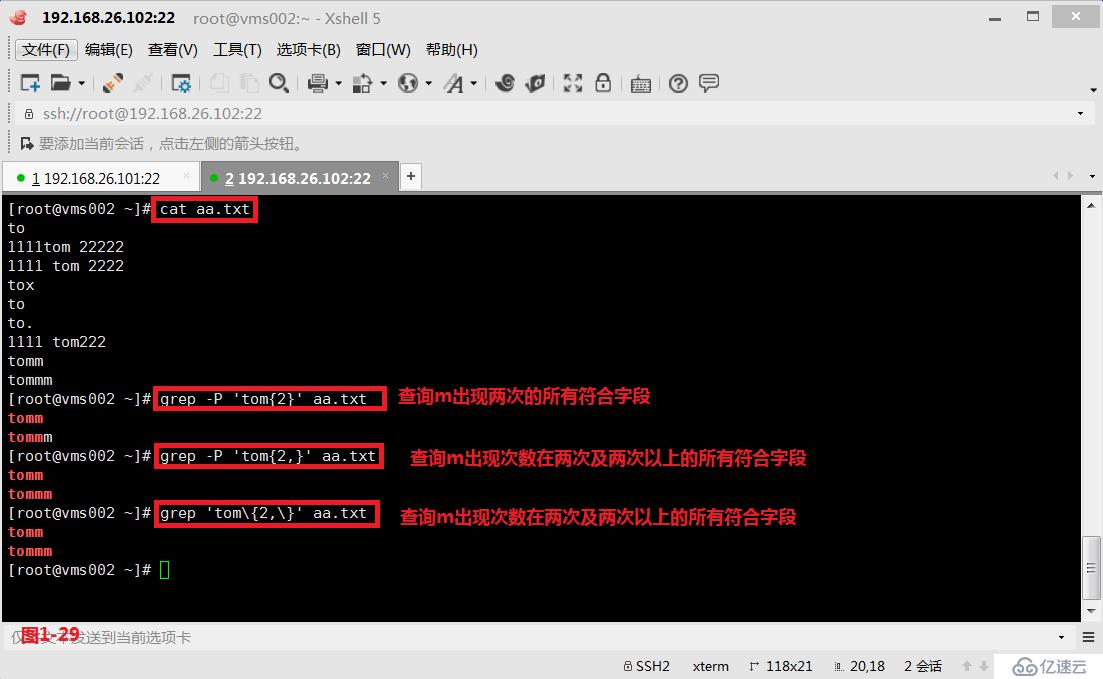
(4.7)第五個是可以使用指定的字符表示特定類型的一類字符。
[[:alpha:]]:表示所有字母
[[:alnum:]]:表示字母與數字字符
[[:ascii:]]:表示ASCII字符
[[:blank:]]:表示空格或制表符
[[:cntrl:]]:表示ASCII控制符
[[:digit:]]:表示數字
[[:graph:]]:表示可見字符,非控制、非空格字符
[[:lower:]]:表示小寫字母
[[:print:]]:表示可打印字符
[[:punct:]]:表示標點符號字符
[[:space:]]:表示空白字符,包括垂直制表符
[[:upper:]]:表示大寫字母
[[:xdigit:]]:十六進制數字
(4.8)查詢實例
(4.8.1)示例:查詢IP地址,目前在我們的/var/log/messages文件主要保存的是系統的日志信息,其中也會有包含IP地址的字符信息,我們的需求是將其中所有IP地址格式的信息全部過濾出來。由于我們知道IP地址的格式可以是192.168.26.101,也可以是1.1.1.1,所以此時我們可以使用“[0-9]{1,3}”表示IP地址的一段信息,使用“{3}”表示數字和點組成的信息重復3次,最后再加上一段數字,此時我們便可以得到這樣一個表示IP地址格式的正則表達式:([0-9]{1,3}.){3}[0-9]{1,3}
# less /var/log/messages---查看包含系統日志的文件
# egrep '([0-9]{1,3}.){3}[0-9]{1,3}' /var/log/messages---查詢出日志中所有包含IP地址的所有字符信息的行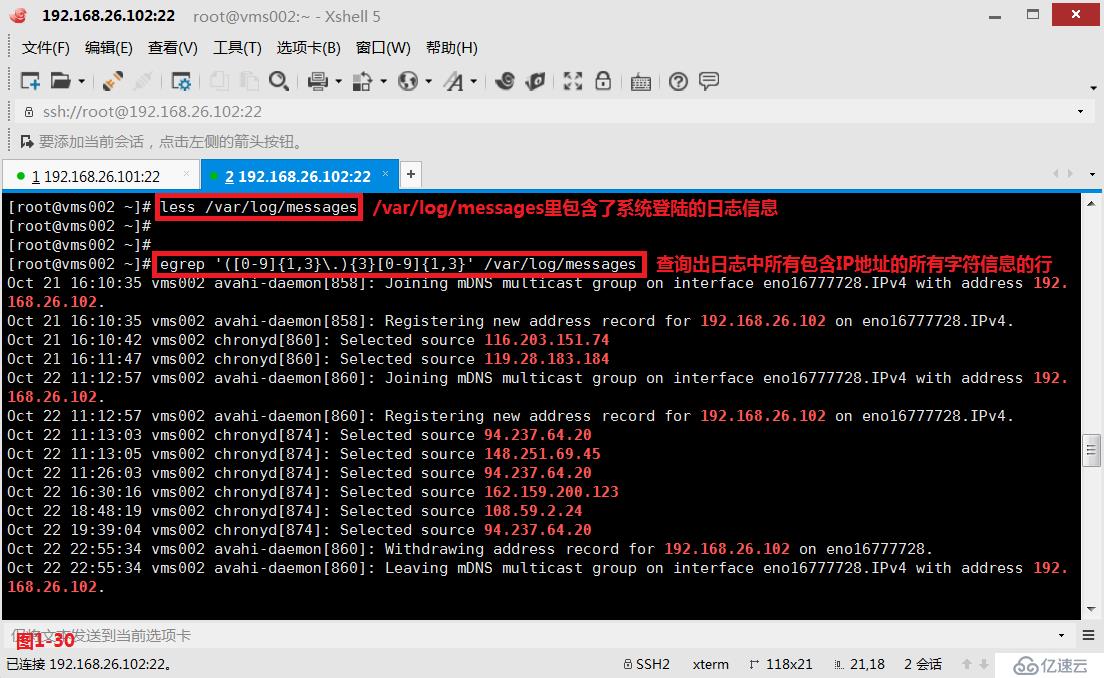
(4.8.2)示例:找出/boot/grub2/grub.cfg文件中1-255之間的數字。此時我們可以使用的正則表達式為:\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>
# egrep '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>' /boot/grub2/grub.cfg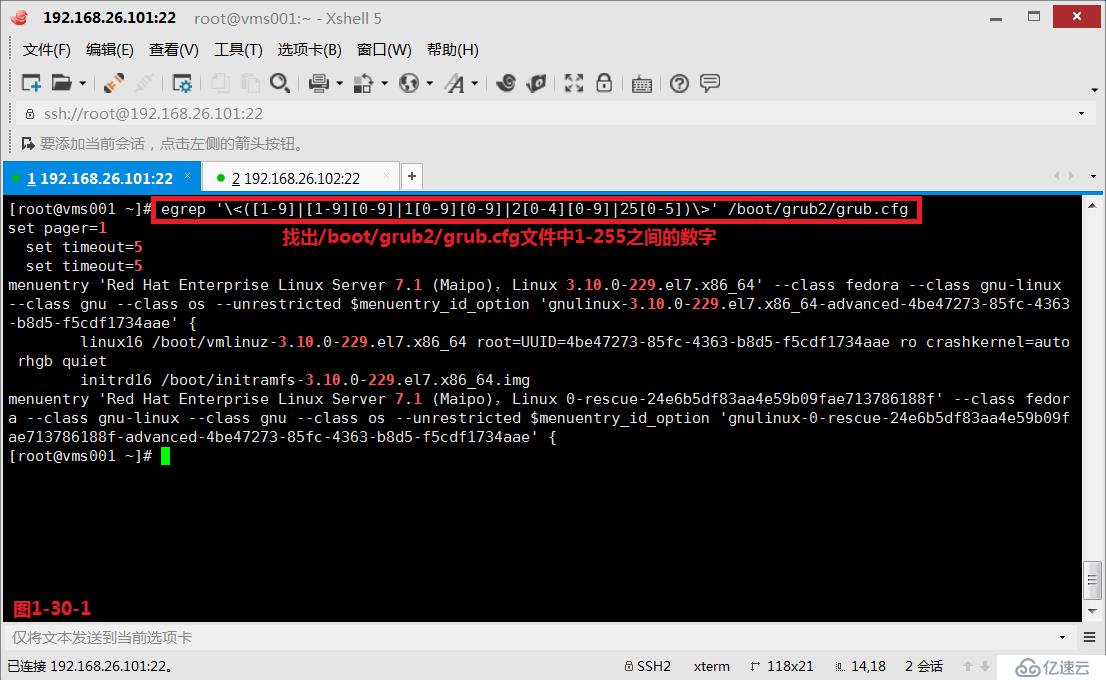
(4.8.3)示例:粗略查詢所有符合IP地址格式要求的字符串,例如0.0.0.0至255.255.255.255這樣的格式,此時我們可以按照如下的方式進行查詢。
# ifconfig | egrep -o '\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'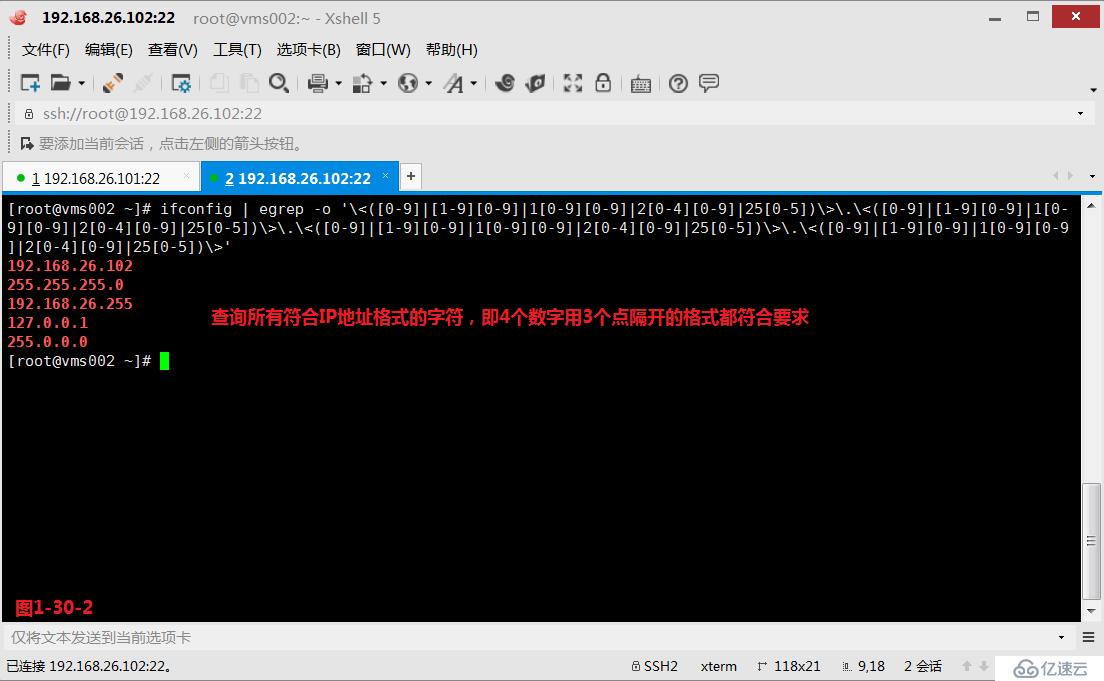
(4.8.4)示例:精確查詢所有格式為IP地址,并且符合五類IP地址中A類、B類、C類IP地址的所有適合的字段。
A類:1-127
B類:128-191
C類:192-223
# ifconfig | egrep '\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[01][0-9]|22[0-3])\>(\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>){2}\.\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>'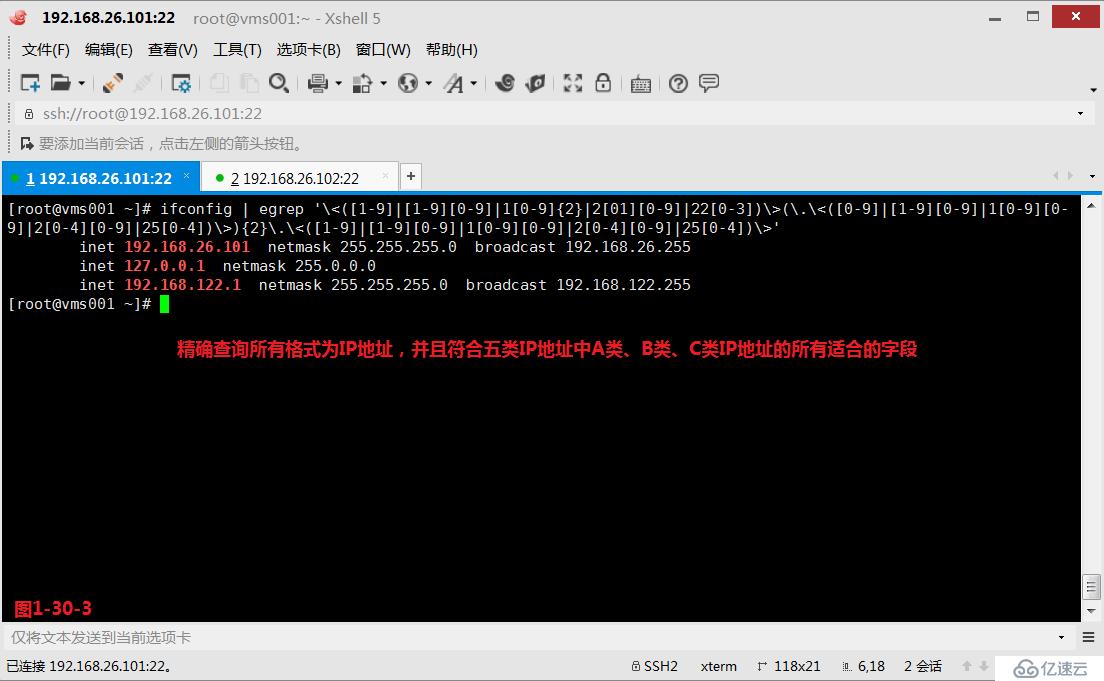
(4.9)一般我們在表示正則表達式中表達式的部分的時候是建議加上單引號將表達式引起來的。如果我們在系統中如果原先存在一個toz文件名的文件,此時我們對表達式不加單引號的情況下,首先會將查詢的“to?”發送到shell中進行shell解析,此時sehll會對應“to?”在系統中查找并解析成“toz”,然后再將“toz”發送到egrep中進行解析,此時在aa.txt文件中是查詢不出來任何信息的。所以一般是需要將表示正則表達式中表達式的部分的時候是建議加上單引號這樣可以防止shell解析的情況發生。
# egrep 'to?' aa.txt---查詢aa.txt中to單詞后出現一個任意字符,這個任意字符出現0次或者1次
# egrep to\? aa.txt---和以上使用單引號的效果一致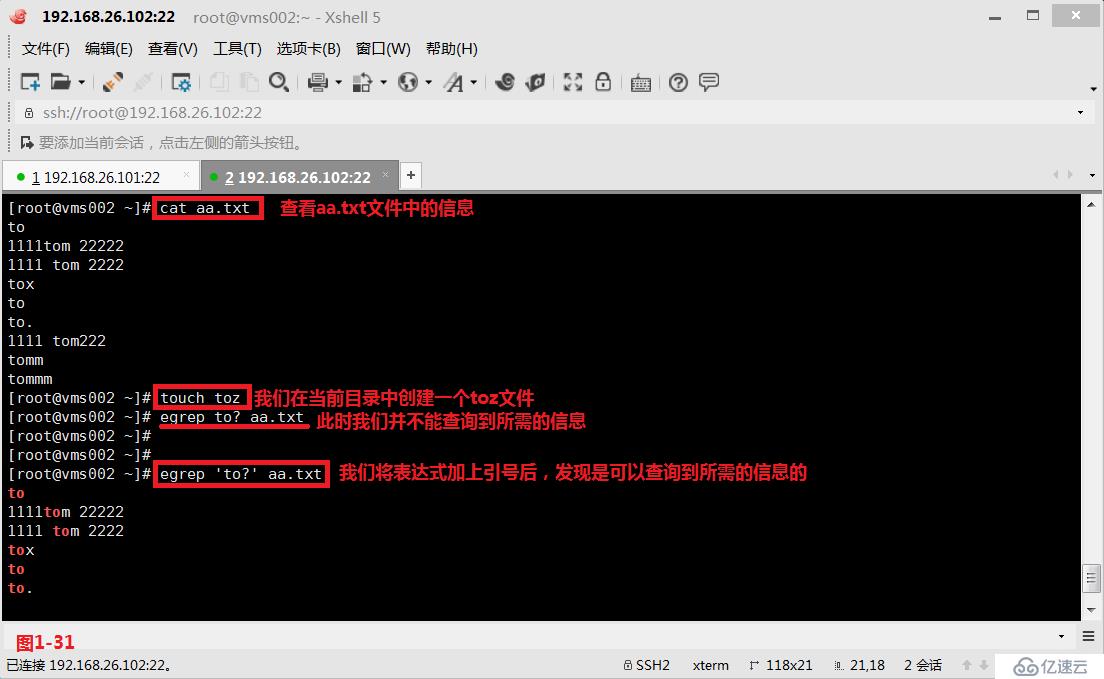
—————— 本文至此結束,感謝閱讀 ——————
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





