溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關SQL Server如何統計信息更新時采樣百分比對數據預估準確性的影響,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
為什么要寫統計信息
最近看到園子里有人寫統計信息,樓主也來湊熱鬧。
話說經常做數據庫的,尤其是做開發的或者優化的,統計信息造成的性能問題應該說是司空見慣。
當然解決辦法也并非一成不變,“一招鮮吃遍天”的做法已經行不通了(題外話:整個時代不都是這樣子嗎)
當然,還是那句話,既然寫了就不能太俗套,寫點不一樣的,本文通過分析一個類似實際案例來解讀統計信息的更新的相關問題。
對于實際問題,不但要解決問題,更重要的是要從理論上深入分析,才能更好地駕馭數據庫。
何時更新統計信息
(1)查詢執行緩慢,或者查詢語句突然執行緩慢。這種場景很可能是由于統計信息沒有及時更新而遭遇了參數嗅探的問題。
(2)當大量數據更新(INSERT/DELETE/UPDATE)到升序或者降序的列時,這種情況下,統計信息直方圖可能沒有及時更新。
(3)建議在除索引維護(當你重建、整理碎片或者重組索引時,數據分布不會改變)外的維護工作之后更新統計信息。
(4)數據庫的數據更改頻繁,建議最低限度每天更新一次統計信息。數據倉庫可以適當降低更新統計信息的頻率。
(5)當執行計劃出現統計信息缺失警告時,需要手動建立統計信息
統計信息基礎
首先說一個老掉牙的話題,統計信息的更新閾值:
1,表格從沒有數據變成有大于等于1條數據。
2,對于數據量小于500行的表格,當統計信息的第一個字段數據累計變化量大于500以后。
3,對于數據量大于500行的表格,當統計信息的第一個字段數據累計變化量大于500 + (20%×表格數據總量)以后。
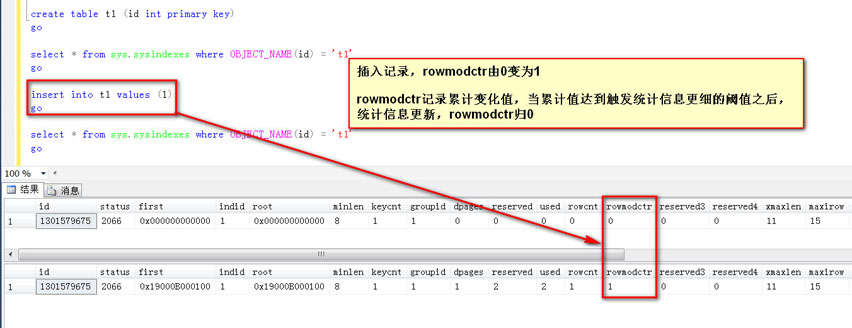
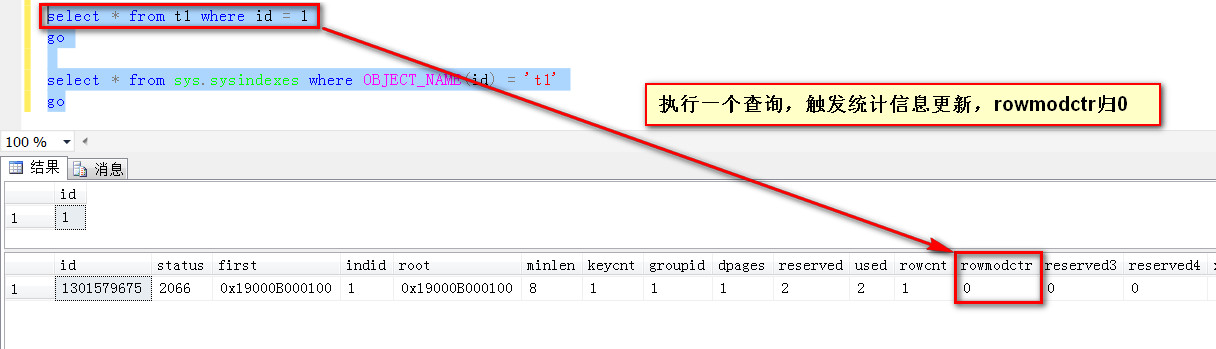
做個查詢,觸發統計信息更新,rowmodct歸0(繼續累積直到下一個觸發的閾值,觸發更新之后再次歸0)
關于統計信息“過期”的問題
下面開始正文,網絡上很多關于統計信息的文章,提到統計信息,很多都是統計信息過期的問題,然后跟新之后怎么怎么樣
尤其在觸發統計信息自動更新閾值的第三個區間:也就是說數據累計變化超過20%之后才能自動觸發統計信息的更新
這一點對于大表來說通常影響是比較大的,比如1000W的表,變化超過20%也+500也就是200W+500行之后才觸發統計信息更新,這個閾值區間的自動觸發閾值,絕大多數情況是不能接受的,于是對于統計信息的診斷就變成了是否“過期”
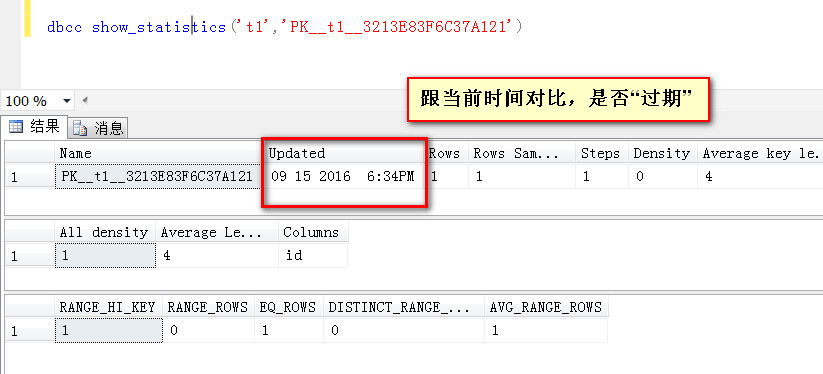
判斷統計信息是否過期,然后通過更新統計信息來促使執行計劃更加準確地預估行數,這一點本無可厚非
但是,問題也就出在這里了:那么怎么更新統計信息?一成不變的做法是否可行,這才是問題的重點。
當然肯定有人說,我就是按照默認方式更新的,更新完之后SQL也變得更加優化了什么的
通過update statistics TableName StatisticName更新某一個索引的統計信息,
或者update statistics TableName更新全表的統計信息
這種情況下往往是小表上可以這么做,當然對于大表或者小表沒有一個標準值,一切要結合事實來說明問題
下面開始本文的主題:
抽象并簡化出業務中的一個實際案例,創建這么一張表,類似于訂單和訂單明細表(主子表),
這里你可以想象成是一個訂單表的子表,Id字段是唯一的,有一個ParentID字段,是非唯一的,
ParentID類似于主表的Id,測試數據按照一個主表Id對應50條子表明細的規律插入數據
CREATE TABLE [dbo].[TestStaitisticsSample]( [Id] [int] IDENTITY(1,1) NOT NULL, [ParentId] [int] NULL, [OtherColumn] [varchar](50) NULL ) declare @i int=0 while(@i<100000000) begin insert into [TestStaitisticsSample](ParentId,OtherColumn)values(@i,NEWID()) /* 中間插入50條,也即一個主表Id對應50條子表明細 */ insert into [TestStaitisticsSample](ParentId,OtherColumn)values(@i,NEWID()) set @i=@i+1 end go create nonclustered index [idx_ParentId] ON [dbo].[TestStaitisticsSample] ( [ParentId] ) go
本來打算插入1億條的,中間我讓他執行我睡午覺去了,醒來之后發現SSMS掛掉了,掛掉了算了,數據也接近1億了,能說明問題就夠了
現在數據分布的非常明確,就是一個ParentId有50條數據,這一點首先要澄清。
測試數據寫入,以及所創建完成之后來更新idx_ParentId 索引上的統計信息,就按照默認的方式來更新,然后來觀察統計信息
默認方式更新統計信息(未指定采樣密度)
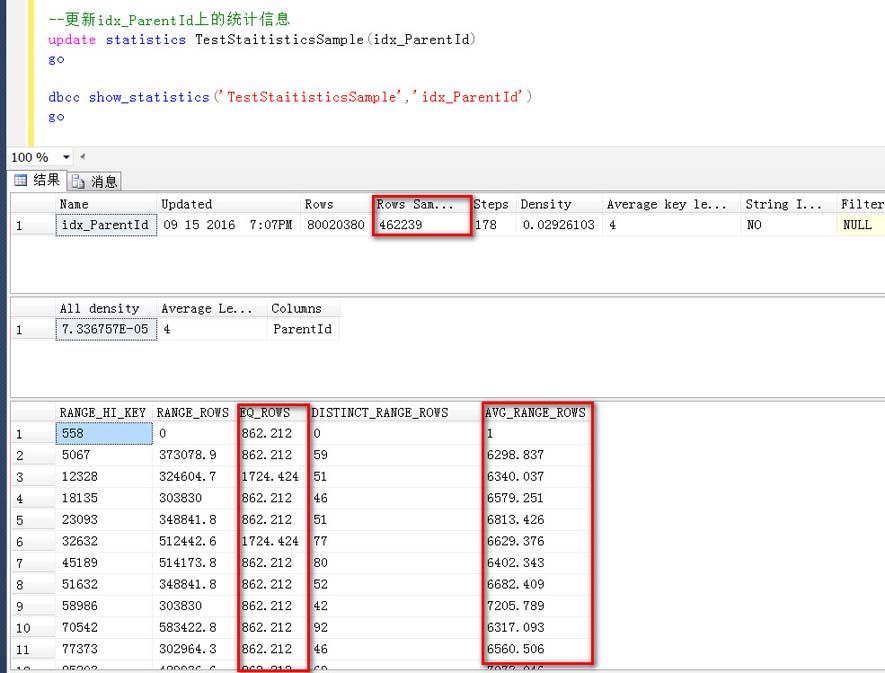
表里現在是8000W多一點記錄,默認更新統計信息時取樣行數是462239行,那么這個統計信息靠譜嗎?
上面說了,造數據的時候,我一個ParentId對應的是50行記錄,這一點非常明確,他這里統計出來的多少?
1,對于取樣的RANG_HI_Key值,比如51632,預估了862.212行
2,對于AVG_RANG_ROW,比如45189到51632之間的每個Id的數據對應的數據行,預估是6682.490行
之前造數據的時候每個Id都是50行,這里的預估靠譜嗎,這個誤差是無法接受的,
很多時候,對于大表,采用默認(未指定采樣密度)的情況下,默認的采樣密度并不足以準確地描述數據分布情況
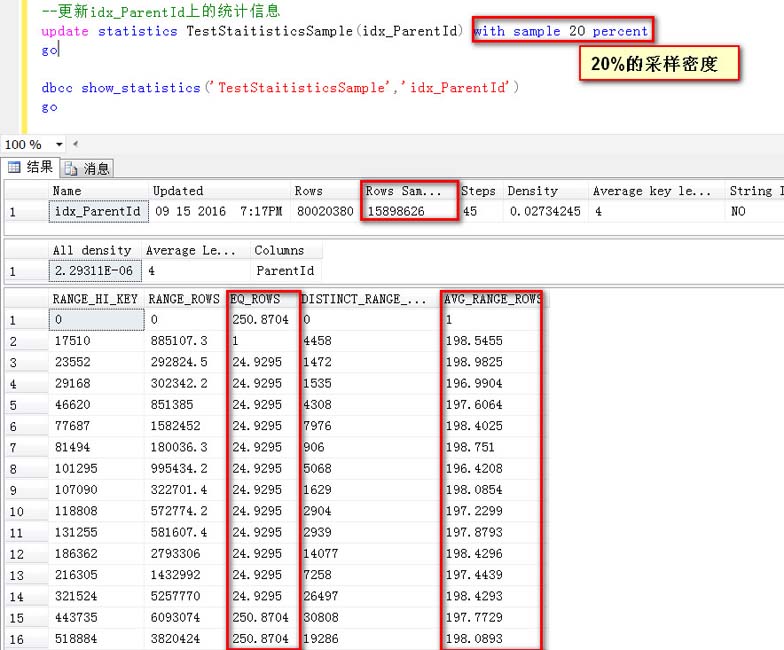
指定一個采樣密度的方式更新統計信息(20%采樣)
這一次用20%的采樣密度,可以看到取樣的行數是15898626行
1,對于取樣的RANG_HI_Key值,比如216305,他給我預估了24.9295行
2,對于AVG_RANG_ROW,比如186302到216305之間的每個Id的行數,預估是197.4439行
觀察比如上面默認的取樣密度,這一次不管是RANG_HI_Key還是AVG_RANG_ROW得預估,都有不一個非常高的下降,開始趨于接近于真實的數據分布(每個Id有50行數據)
整體上看,但是這個誤差還是比較大的,如果繼續提高采樣密度,看看有什么變化?
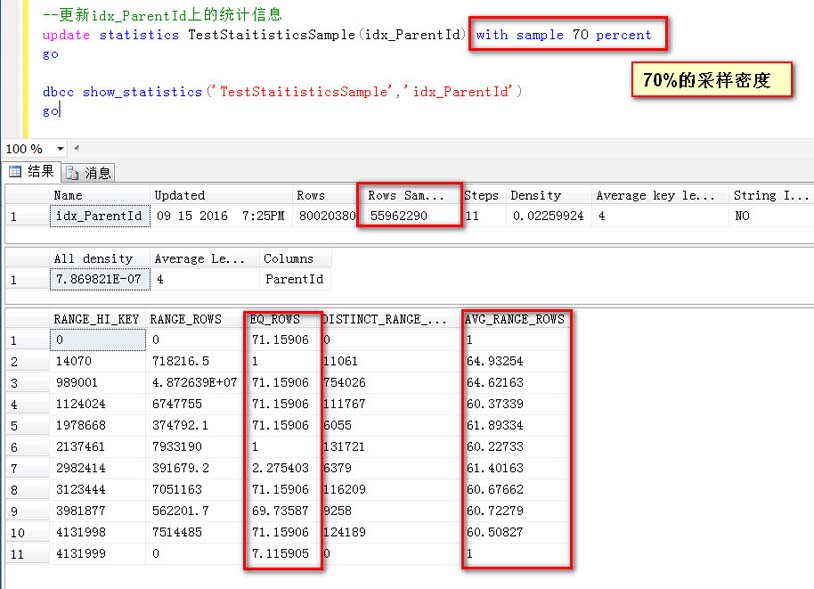
指定一個采樣密度的方式更新統計信息(70%采樣)
這一次用70%的采樣密度,可以看到取樣行數是55962290行
1,對于取樣的RANG_HI_Key值,比如1978668,預估了71.15906行
2,對于AVG_RANG_ROW,比如1124024到1978668之間的每個Id,預估為61.89334行
可以說,對于絕大多數值得預估(AVG_RANG_ROW),都愈發接近于真實值
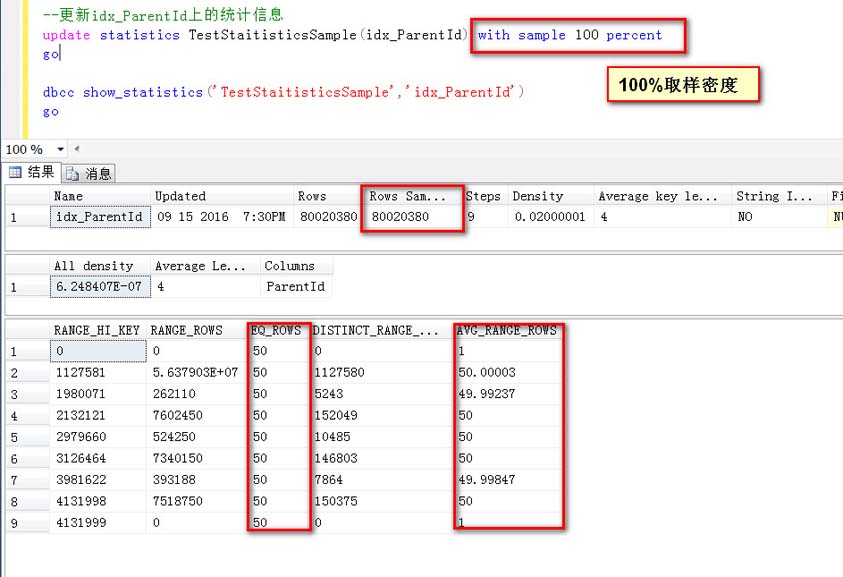
指定一個采樣密度的方式更新統計信息(100%采樣)
可以看到,取樣行數等于總行數,也就是所謂的全部(100%)取樣
看一下預估結果:
比如Id=3981622,預估是50行,3981622與4131988之間的Id的行數,預估為49.99874行,基本上等于真實數據分布
這個就不做過多解釋了,基本上跟真實值是一樣的,只是AVG_RANG_ROW有一點非常非常小的誤差。
取樣密度高低與統計信息準確性的關系
至于為什么默認取樣密度和較低取樣密度情況下,誤差很大的情況我簡單解釋一下,也非常容易理解,因為“子表”中存儲主表ID的ParentId值允許重復,在存在重復值的情況下,如果采樣密度不夠,極有可能造成“以偏概全”的情況
比如對10W行數據取樣1W行,原本10W行數劇中有2000個不重復的ParentId值,如果是10%的取樣,在1W行取樣數據中,因為密度不夠大,只找到了20個不重復的ParentId值,那么就會認為每一行ParentId對應500行數據,這根實際的分布的每個ParentId有一個非常大的誤差范圍
如果提高采樣密度,那么這個誤差就會越來越小。
更新統計信息的時候,高比例的取樣是否可取(可行)
因此在觀察統計信息是否過期,決定更新統計信息的時候,一定要注意取樣的密度,就是說表中有多少行數據,統計信息更新的時候取了多少采樣行,密度有多高。
當然,肯定有人質疑,那你說采樣密度越高,也就是取樣行數越高越準確,那么我就100%取樣。
這樣行不行?
還要分情況看,對于幾百萬或者十幾萬的小表來說,當然沒有問題,這也是為什么數據庫越小,表數據越少越容易掩蓋問題的原因。
對于大表,上億的,甚至是十幾億的,你按照100%采樣試一試?
舉個實際例子:
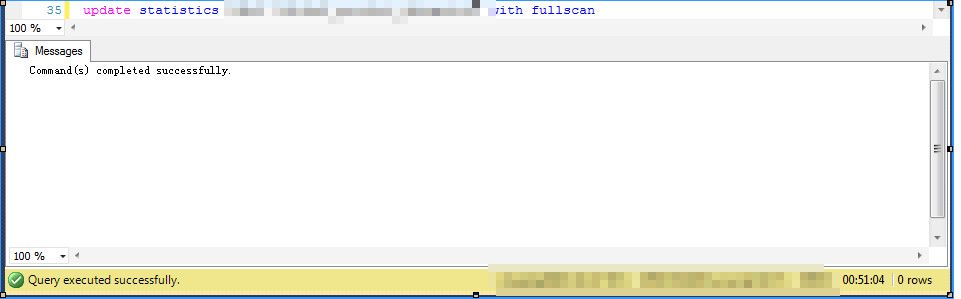
我這里對一個稍微大一點的表做個全表統計信息的更新,測試環境,服務器沒負載,存儲是比普通的機械硬盤要強很多的SAN存儲
采用full scan,也就是100%采樣的更新操作,看一下,僅僅這一樣表的update statistic操作就花費了51分鐘
試想一下,對一個數百GB甚至數TB的庫來說,你敢這么搞一下。
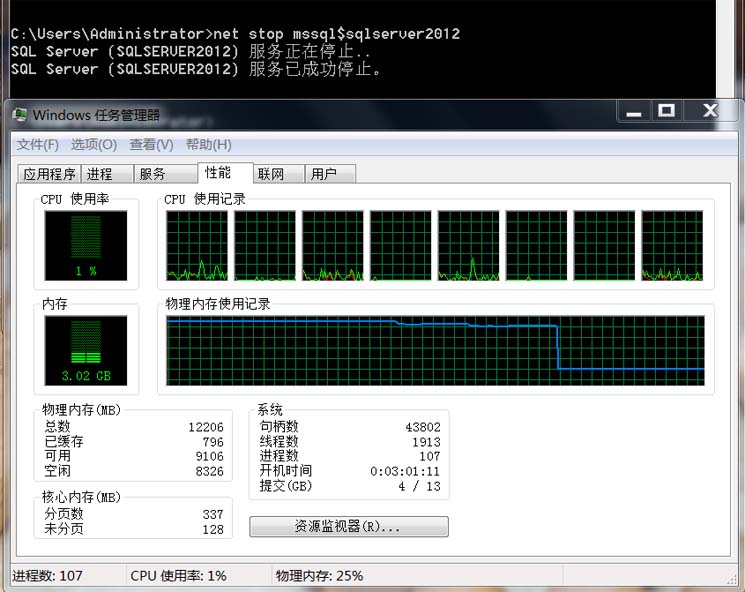
扯一句,這個中秋節過的,折騰了大半天,話說做測試過程中電腦有開始有點卡,
做完測試之后停掉SQLServer服務,瞬間內存釋放了7個G,可見這些個操作還是比較耗內存的
關于“SQL Server如何統計信息更新時采樣百分比對數據預估準確性的影響”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





