溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
翻譯自:
https://www.mssqltips.com/sqlservertip/5710/whats-new-in-the-first-public-ctp-of-sql-server-2019/
問題
SQL Server 2019的第一個公共CTP版已經發布,充滿了增強和新特性(其中很多也可以在預覽形式Azure SQL Database里找到)。我之前有深入了解過,允許我分享一下我的經驗。你也可以查看SQL Server團隊最新的博文和更新的官方技術文檔。
解決方案
我將討論一些新的引擎特性,分為下五個方面:性能、問題定位、安全、可用性和開發。這次,對于有些特性我有更詳細的內容,事實上已經寫了完整的博文詳述幾個。當更多的文檔和文章可用時,我將回頭更新這些部分。放心,這不是一個詳盡的列表,只是直到CTP 2.0版我已了解的內容。還會有更多內容到來。
性能
表變量延遲編譯(Table variable deferred compilation)
表變量名聲有點不好,大多因為預估。默認,SQL Server預計只有一行會出現在表變量中,當實際有多行時會導致某些有趣的計劃選擇。避免這種情況的典型變通方案是使用OPTION (RECOMPILE),但這需要修改代碼,當行數通常相同時單次重編譯很浪費時間。引入了跟蹤標志2453來模擬重編譯行為,但是需要運行在一個跟蹤標志下,只有當發現又很明顯行數變化時才會發生。
在兼容級別150,當表變量調用時你可以延遲編譯,意思是,直到表變量被填充一次才會構建一個計劃。預估將基于表變量的第一次使用,再次之后將沒有重編譯發生。這是一個在一直重編譯以獲得實際每次預估,和從不重編譯一直預估為1之間的折中。 如果你的行數保持相對穩定就很好,并且這個數遠遠大于1就更好,但如果這個數大幅波動就沒什么用。
在最近發表的博文中,我深入研究了該功能,SQL Server中的表變量延遲編譯,Brent Ozar在更快的表變量和新的參數嗅探問題也談到了它。
行模式內存授予反饋(Row mode memory grant feedback)
SQL Server 2017引入了批模式內存授予反饋,在這里有詳細描述。本質上,對于任何與執行計劃有關的內存授予牽涉到批模式操作者,SQL Server會預估查詢的內存使用,并將它與請求內存相比較。如果請求的內存太低或太高,導致溢出或浪費內存,它會在下次運行的時候調整與執行計劃相關的內存授予。這要么會減少授予以允許更高并發量,要么增加授予以提高性能。
現在在兼容級別150下,對于行模式查詢我們也獲得了該行為。如果一個查詢被發現需要訪問磁盤,對于后續的執行將會增加內存授予。如果查詢的實際內存使用少于內存授予的一半,后續授予請求將會更低。Brent Ozar在這篇文章適當的內存授予中講得更細。
基于行存儲的批模式(Batch mode over rowstore)
自從SQL Server 2012,對帶有列存儲索引的表查詢在批模式的性能增強中收益。性能提升是由于相對一行行執行,查詢處理器執行批處理。數據行可以在存儲引擎上面以批的形式存儲,可以避免并行交換算子。Paul White(Twitter賬號@SQL_Kiwi)提醒我如果你使用一個空的列存儲表可以執行批模式操作,存儲的行由不可見的操作符聚集成批。然而,這個黑 客行為會取消從批模式處理獲得的任何提升。在Stack Exchange的回答中有些信息。
在兼容級別150下,SQL Server 2019會在特定的熱點案例中自動選擇批模式,即使沒有出現列存儲索引。你會想,為什么不只創建一個列存儲索引并使用它?或者使用上面提到的黑 客行為?這種情況擴展到傳統的行存儲對象,因為列存儲索引不總是可能的,由于大量原因,包括缺乏特性支持(例如觸發器),大量的更新刪除負載下,或者缺乏第三方支持。上面提到的黑 客行為只是一個壞消息。
我創建了一個1千萬行的簡單表,在整型列上創建了一個單一聚集索引,然后運行如下查詢:
SELECT sa5, sa2, SUM(i1), SUM(i2), COUNT(*) FROM dbo.FactTable WHERE i1 > 100000 GROUP BY sa5, sa2 ORDER BY sa5, sa2;
這個查詢清晰的顯示了一個聚集索引查找和并行,但是沒有任何列存儲索引的跡象(顯示在SentryOne執行計劃瀏覽器,一個免費查詢調優工具):

如果你深入研究,會發現幾乎所有的操作符都以批模式運行,甚至排序和標量計算:
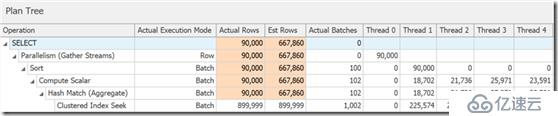
你可以通過保持在一個更低的兼容級別上、通過修改數據庫范圍配置(在將來的CTP版本會到來),或通過使用DISALLOW_BATCH_MODE查詢提示來禁止該功能:
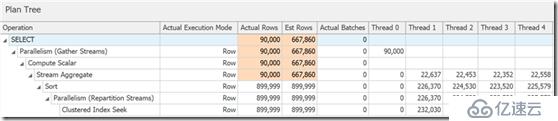
SELECT … OPTION (USE HINT ('DISALLOW_BATCH_MODE'));在這個案例中以上查詢計劃有一個額外的交換運算符,所有的運算符以行模式執行,該查詢花費了三倍時間去運行:

你可以在這個圖上看到,但是在執行計劃樹的詳細信息里,你也可以看到謂詞直到排序后才會消除行:
批模式的選擇不總是必殺器。而是與行計數的決定,操作符相關的類型和批模式期待收益有關。
APPROX_COUNT_DISTINCT
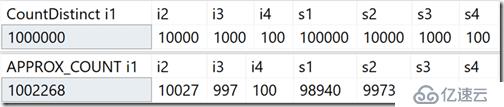
新的聚合函數為數據倉庫場景設計,等價于COUNT(DISTINCT())。替代執行昂貴的排序去重操作以確定實際行數,它依賴于統計信息來獲取相對真實的數據。你會發現差距是實際計數的2%,97%的時間,通常用于高級別分析,值用于填充一個報表,或快速預估。
我創建了一個表,有一個值范圍在100到1000000之間的唯一值的整型列,和一個值范圍在100到100000之間的唯一值的字符串列。除了主要整型列上的聚集索引主鍵,沒有其他索引。針對這些列的COUNT(DISTINCT())和APPROX_COUNT_DISTINCT()的比較結果,你可以看到差異總在2%以內。
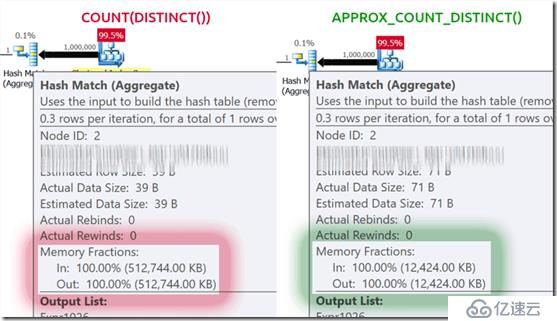
如果你是內存受限的,回報是巨大的,適用于大多數情況。如果你這個案例中查看執行計劃,你會看到在哈希匹配操作符上內存占用量的巨大差異:
注意:
如果你已經是內存受限的,你只會看到重要的性能提升。在我的系統上,由于更多CPU被新的函數使用,運行時間稍微更長一些:

如果我有更大的表,更少的可用內存給到SQL Server,更高的并發量,或任何組合,結果很有可能不一樣。
查詢作用域的兼容級別提示(Query-scoped compatibility level hints)
有一個查詢在與當前數據庫不同的兼容級別下運行得更好?現在你可以使用新的查詢提示支持六個不同的兼容級別和五個不同的基數預估模式。以下顯示了在每個案例中使用的可用兼容級別,示例語法和CE模式。你可以看到它如何影響預估,甚至對于系統目錄視圖:

長話短說:不再需要記錄跟蹤標志,或懷疑是否仍然需要擔心在TF 4199下你的優化修復被覆蓋,或被某些服務包或累積更新包所消除。注意,這些額外的提示當前也被添加到SQL Server 2017累積更新10中(查看Pedro Lopes的博文查看更多詳細信息)。你也可以看到所有可用提示:
SELECT name FROM sys.dm_exec_valid_use_hints;
但請一直記住提示是最后的依靠。它們讓你擺脫困境,但是你不能長期讓你的代碼像那樣,因為隨著之后的更新行為會改變。
問題定位
默認開啟輕量級跟蹤(Lightweight profiling on by default)
這個增強需要一點背景知識。SQL Server 2014引入了DMV sys.dm_exec_query_profiles,允許用戶運行查詢,同時收集查詢執行期間所有操作符的診斷信息。在查詢完成后,這個信息可以被用來確定哪個操作符實際做了最多工作并且為什么。沒有運行那個特定查詢的任何用戶,仍然可以對任何會話啟用STATISTICS XML或STATISTICS PROFILE,或者對于所有會話通過query_post_execution_showplan擴展事件(通過該事件會對整體性能帶來潛在的巨大壓力)來獲得這個數據的解析。
SSMS 2016添加了功能基于從DMV收集的信息通過執行計劃實時顯示數據移動,它對于問題定位非常有用。執行計劃瀏覽器也提供了對于查詢執行期間可視化數據的實時和重放能力。
從SQL Server 2016 SP1開始,你也可以對于所有會話啟用輕量版本的數據收集,通過使用跟蹤標志7412或者query_thread_profile擴展事件,以便你可以立即獲得任何會話的確切信息而不用在他們的會話中顯示啟用任何東西(特別是負面影響性能的東西)。與此有關的更多信息在Pedro Lopes的博文中。
在SQL Server 2019,這個進程跟蹤默認被啟用。所以你不需要運行一個特定擴展事件會話,或者任何跟蹤標志,或者在任何獨立查詢開啟STATISTICS選項;你只能對并發會話在任何時候從DMV查看數據。你可以使用一個新的數據庫范圍配置叫LIGHTWEIGHT_QUERY_PROFILING來關閉它,但該語法不能工作在CTP 2.0(這將會被將來的CTP修復)。
聚集列存儲索引統計信息在克隆數據庫時可用(Clustered Columnstore Index Statistics Available in Clone Databases)
在當前版本的SQL Server,克隆數據庫只會從聚集列存儲索引帶來原始統計對象,忽略任何在創建后對該表所做的任何更新。如果你對依賴于基數預估的查詢調優和其他性能測試使用克隆,這些案例可能無效。Parikshit Savjani在這篇博文描述了限制,并提供了一個工作區:在開始克隆前,生成了一個針對每個對象運行DBCC SHOW_STATISTICS…WITH STATS_STREAM的腳本。這個成本很高,完全容易忘記。
在SQL Server 2019,這些更新的統計信息也只能在克隆時自動可用,因此你可以測試不同的查詢場景,并基于真實統計信息獲得可靠的計劃,不用對所有表運行STATS_STREAM。
對于列存儲的壓縮預估(Compression estimates for Columnstore)
在當前版本,存儲過程sys.sp_estimate_data_compression_savings有如下檢查:
if (@data_compression not in ('NONE', 'ROW', 'PAGE'))意味著它允許你檢查行或頁壓縮(或去看下移除當前壓縮的影響)。在SQL Server 2019,該檢查現在像這樣:
if (@data_compression not in ('NONE', 'ROW', 'PAGE', 'COLUMNSTORE', 'COLUMNSTORE_ARCHIVE'))這是個好消息,因為它允許你粗略預估添加一個列存儲索引到一個表的影響,或者轉換一個表或分區到一個更激進的列存儲格式,不用存儲表到另一個系統并實際嘗試它。在我的系統上有一個1千萬行的表,提供五個參數運行該存儲過程:
EXEC sys.sp_estimate_data_compression_savings @schema_name = N'dbo', @object_name = N'FactTable', @index_id = NULL, @partition_number = NULL, @data_compression = N'NONE'; -- repeat for ROW, PAGE, COLUMNSTORE, COLUMNSTORE_ARCHIVE
結果:

如同其他壓縮類型,精確性依賴于行取樣,和這些數據在其他數據中的代表性。當然,這是一個猜猜看的很好方式而不用精準數據。
獲得頁信息的新函數(New function to retrieve page info)
DBCC PAGE和DBCC IND長期用于收集包含分區、索引或表的信息。但它們是未公開的和不支持的命令。關于涉及多個索引或頁的問題對于自動化解決方案是相當乏味的。
隨著sys.dm_db_database_page_allocations的到來,DMF返回特定對象的所有頁的一個集合。仍然是未公開的,該功能展示了在大表上的實際問題--謂詞下推:即使獲得單頁的信息,也得讀取整個結構,這可能是頗為忌諱的。
SQL Server 2019引入了另一個DMF sys.dm_db_page_info。它基本返回了一頁上的所有信息,沒有分配DMF的開銷。在當前版本,你得已經知道使用這個函數的頁號。這可能是有意的,因為這樣是唯一確保性能的方法。因此如果你嘗試確定一個索引或表里的所有頁,你仍然需要使用分配DMF。之后我會寫些關于這個函數的博文。
安全
始終使用安全包加密敏感數據(Always Encrypted using Secure Enclaves)
今天,在傳輸中始終使用安全包加密敏感數據,和在每個進程端在內存中加密和解密。不幸的是,這通常會引入關鍵的處理約束,這樣不能執行運算和過濾。意味著為了執行一個范圍查找,整個數據集得被發送。
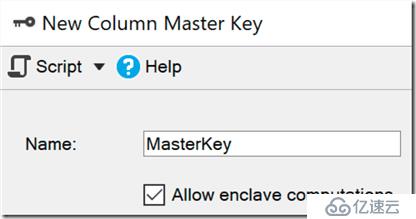
一個安全包是一個保護的內存區域,在哪里運算和過濾被委托(在Windows中,這使用基于虛擬化的安全)。數據在引擎中保持加密,但是在安全包中可以被安全加密或解密。你只需要添加ENCLAVE_COMPUTATIONS選項到主秘鑰,你可以再SSMS中勾選“Allow enclave computations”復選框:
與老方法相比(通過向導,或者Set-SqlColumnEncyption命令,或應用程序,需要將數據庫的所有數據完全移出、加密、然后發送回數據庫),現在你幾乎可以立即加密數據:
ALTER TABLE dbo.Patients ALTER COLUMN SSN char(9) -- currently not encrypted! ENCRYPTED WITH ( COLUMN_ENCRYPTION_KEY = ColumnEncryptionKeyName, ENCRYPTION_TYPE = Randomized, ALGORITHM = 'AEAD_AES_256_CBC_HMAC_SHA_256' ) NOT NULL;
這允許通配符和范圍查找、排序等,以及查詢內的就地加密,無安全損失,因為安全包允許加密和解密在服務器上發生。你也可以執行安全包中的加密秘鑰輪詢。
我猜該特性將讓很多組織修正目標,但在這個CTP版某些優化仍舊是很棒的,而它們默認沒啟用。但在這篇文章啟用豐富的運算你可以了解到如何開啟。
在配置管理中的證書管理(Certificate Management in Configuration Manager)
管理SSL和TLS證書一直是一個痛點,很多人不得不執行冗長乏味的工作和自制的腳本,在企業中部署和維護證書。隨著SQL Server 2019配置管理器的功能更新,允許你快速查看和驗證任何實例的證書,找出即將過期的證書,在AG中跨多個副本(從一個地方:主副本)、或者FCI中的所有節點(從一個地方:活躍節點)同步部署證書。
我還沒有嘗試所有這些操作,但是它們應該能對舊版的SQL Server起作用,只要從SQL Server 2019版的SQL Server配置管理器來執行。
內置數據分類和審計(Built-In Data Classification and Auditing)
在SSMS 17.5,SQL Server團隊在SSMS中添加了分類數據的功能,你可以識別可能包含敏感信息的列,或者可能不遵守各種標準(HIPAA、SOX、PCI和GDPR)。該向導使用一個算法,對于它認為可能導致規范性問題的列給出建議,但你可以自己添加、調整它的建議,并從列表消除任何列。使用擴展屬性存儲這些分類;基于SSMS的報表使用相同的信息來顯示這些被識別的列。報表外,這些屬性不可見。
在SQL Server 2019對于該元數據有個新命令,在Azure SQL Database也有,叫做ADD SENSITIVITY CLASSIFICATION。這允許你像SSMS向導一樣做同樣的事情,但是信息不再存儲為擴展屬性,任何對數據的訪問自動以新的XML列data_sensitivity_information顯示在審計中。這包含了在審計事件中訪問的所有信息類型。
例如,有如下表:
CREATE TABLE dbo.Contractors ( FirstName sysname, LastName sysname, SSN char(9), HourlyRate decimal(6,2) );
可以看到,這四列要么容易數據泄露,要么不應該對每個訪問該表的人可用,至少,我們需要提高可見性。因此可以用不同方式分類這些列:
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.FirstName, dbo.Contractors.LastName WITH (LABEL = 'Confidential a€“ GDPR', INFORMATION_TYPE = 'Personal Info'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.SSN WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'National ID'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.HourlyRate WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'Financial');
現在,不用看sys.extended_properties,你可以查看sys.sensitivity_classifications的元數據:

如果你對該表審計SELECT或DML,你不必修改審計;創建了分類后一個SELECT *將在審計日志中產生新的data_sensitivity_information列:
<sensitivity_attributes> <sensitivity_attribute label="Confidential - GDPR" information_type="Personal Info" /> <sensitivity_attribute label="Highly Confidential" information_type="National ID" /> <sensitivity_attribute label="Highly Confidential" information_type="Financial" /> </sensitivity_attributes>
這明顯不能解決所有規范性問題,但是開了個好頭。如果你試用向導自動識別列,那么會自動將sp_addextendedproperty調用翻譯為ADD SENSITIVITY CLASSIFICATION命令,可以很好的遵從規范性。之后我會寫更多關于此的博文。
你也可以基于標簽元數據自動或更新權限。對一個用戶、組或完全可管理的角色,創建一個禁止訪問所有Confidential – GDPR列的動態SQL語句。之后我會展開來講。
可用性
可恢復在線索引創建(Resumable online index creation)
SQL Server 2017引入了暫停和恢復在線索引重建的功能,對于你想修改使用的CPU數很有用,在一個故障轉移事件后繼續剩下的操作,或者只是填補維護窗口間的空白。之前的博文我已講到該特性,關于SQL Server 2017中的可恢復在線索引重建。
在SQL Server 2019,你可以使用相同的語法在線創建索引,你可以暫停和恢復,甚至設置運行時上線(在上線將會暫停運行):
CREATE INDEX foo ON dbo.bar(blat) WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 10 MINUTES);
如果運行時間太長,你可以在另一個會話使用ALTER INDEX來暫停(哪怕這個索引還不存在):
ALTER INDEX foo ON dbo.bar PAUSE;
在當前版本當恢復時不能像重建那樣減少并行度。如果你嘗試減少DOP:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 2);
你會得到:
Msg 10666, Level 16, State 1, Line 3 Cannot resume index build as required DOP 4 (DOP operation was started with) is not available. Please ensure sufficient DOP is available or abort existing index operation and try again. The statement has been terminated.
事實上,當你這么做時,至少在當前版本,只會觸發一個沒有選項的恢復,會得到相同的錯誤消息。我猜恢復嘗試記錄在某處并被重用。你需要指定正確或更高的DOP以便繼續:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 4);
很明顯,當恢復一個暫停的索引創建時你可以增加DOP,你只是不能減少。
另一個額外的好處是,當使用新的數據庫范圍配置ELEVATE_ONLINE和ELEVATE_RESUMABLE時,默認可以對數據庫執行在線和可恢復索引操作。
聚集列存儲索引在線創建、重建(Online create / rebuild for Clustered Columnstore Indexes)
除了可恢復的在線索引創建,你也可以在線創建或重建聚集列存儲索引(當然這也是可恢復的)。巨大改變是你不再需要維護窗口來執行索引維護,一個更具說服力的案例:將行存儲轉換為列存儲:
CREATE TABLE dbo.splunge ( id int NOT NULL ); GO CREATE UNIQUE CLUSTERED INDEX PK_Splunge ON dbo.splunge(id); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (DROP_EXISTING = ON, ONLINE = ON);
警告:從傳統的聚集索引轉換為聚集列存儲索引,只有在你已存在的聚集索引是以特定的方式創建時才可以在線操作。如果它是顯式聚集索引約束或者內聯創建索引:
CREATE TABLE dbo.splunge ( id int NOT NULL CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED (id) ); GO -- or after the fact -- ALTER TABLE dbo.splunge ADD CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED(id);
將會報錯:
Msg 1907, Level 16 Cannot recreate index 'PK_Splunge'. The new index definition does not match the constraint being enforced by the existing index.
為了轉換為聚集列存儲索引,你得先刪除該約束,但是你仍然能執行在線操作:
ALTER TABLE dbo.splunge DROP CONSTRAINT PK_Splunge WITH (ONLINE = ON); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (ONLINE = ON);
在大表上,它可能要比主鍵創建為唯一聚集索引花的時間更長。我不確定是否為預期行為,或者是當前CTP版本的限制。
輔助副本到主副本連接重定向(Secondary to Primary Replica Connection Redirection)
該特性允許你不用監聽器配置重定向,因此即便輔助副本在連接串中顯式命名,你可以切換連接到主副本。當你的群集拓撲不支持監聽器,或者當你使用無群集AG,或者在多子網場景下有一個復雜的重定向架構,你也可以使用該特性。例如,這將阻止嘗試對一個只讀副本寫操作(失敗)的連接。
開發
圖增強(Graph enhancements)
圖關系現在對node或edge表支持使用MATCH謂詞的MERGE語句;現在一條語句可以更新一個存在的edge或插入一個新的edge。一個新edge約束允許控制一個edge可以連接那個node。
UTF-8
SQL Server 2012添加了對UTF-16的支持,通過將排序規則命名為_sc后綴來增補字符,像Latin1_General_100_CI_AI_SC,對于使用Unicode列(nchar/nvarchar)。在SQL Server 2017,可以以UTF-8格式導入和導出數據,通過BCP和BULK INSERT來處理這些列。
在SQL Server 2019,有新的排序規則在SQL Server內本地支持存儲為UTF-8數據。因此,你可以適當的使用新的以_SC_UTF8后綴的排序規則創建char或varchar列存儲UTF-8數據,像Latin1_General_100_CI_AI_SC_UTF8。這可以幫助提高擴展應用和其他數據庫平臺和系統的兼容性,不用花費性能去存儲nvarchar。
發現的一個小彩蛋
在我的記憶中,SQL Server用戶總是抱怨模糊的錯誤信息:
Msg 8152 String or binary data would be truncated.
在當前的CTP版本中,我發現了之前沒有的有趣錯誤信息:
Msg 2628 String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'.
我不認為這里還有什么需要說明的;這是一個偉大的姍姍來遲的改進,將讓很多人非常高興。然而,該功能在CTP 2.0不可用;我只是給你窺探下將來的增強,你可能還沒有發現。Brent Ozar在當前CTP版本中列出了所有新的消息,在他的博文中準備了一些有用的評注:sys.messages解密。
總結
SQL Server 2019提供了大量的增強來提升你鐘愛的關系數據庫平臺,還有大量的改變我還沒有提及的。持久內存支持,機器學習服務群集,Linux上的復制和分布式事務,Kubernetes,Oracle/Teradata/MongoDB的連接器,同步AG副本最多可到5個支持Java(類似于Python/R的實現),最后一點,新的嘗試“Big Data Cluster”。這些新特性你需要填寫EAP表單獲得。
Bob Ward即將出版的新書,Pro SQL Server on Linux – Including Container-Based Deployment with Docker and Kubernetes,會給你一些新線索。Brent Ozar的博文談到了對用戶自定義標量函數的即將到來的修復。
但即便是在第一個公共CTP版,這些特性都只是針對每個人的,我鼓勵你自己做實驗,讓我知道你覺得怎樣。
接下來
閱讀更多關于SQL Server 2019的資源:
SQL Server 2019官方文檔
SQL Server Blog中更多關于SQL Server 2019的信息
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





