溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
? 由Facebook開源用于解決海量結構化日志的數據統計。是基于Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張表,并提供類SQL查詢功能。本質上其實就是將HQL/SQL轉化為MapReduce或者spark任務執行,然后返回結果。有以下幾個本質:
1)Hive處理的數據存儲在HDFS。默認在
在/ user/hive/warehouse/<databaseName>.db/<tableName>/ 下創建對應文件
2)Hive分析數據底層的實現是MapReduce或者spark等分布式計算引擎
3)執行程序運行在Yarn上
所以由此可以得出:hive是使用SQL類似的語言接口而已,其他特征和mysql之類的數據庫完全是兩碼事
優點:
1)操作接口采用類SQL語法,提供快速開發的能力(簡單、容易上手)
2)避免了去寫MapReduce,減少開發人員的學習成本。
3)Hive的執行延遲比較高,因此Hive常用于數據分析,對實時性要求不高的場合;
4)Hive優勢在于處理大數據,對于處理小數據沒有優勢,因為Hive的執行延遲比較高。
5)Hive支持用戶自定義函數,用戶可以根據自己的需求來實現自己的函數。
缺點:
1)Hive的HQL表達能力有限
(1)迭代式算法無法表達
(2)數據挖掘方面不擅長
2)Hive的效率比較低
(1)Hive自動生成的MapReduce作業,通常情況下不夠智能化
(2)Hive調優比較困難,粒度較粗
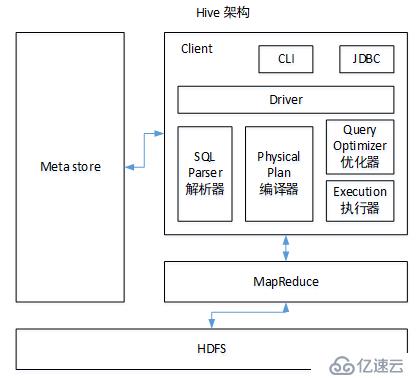
? 圖1.1 hive架構
? 如圖中所示,Hive通過給用戶提供的一系列交互接口,接收到用戶的指令(SQL),使用自己的Driver,結合元數據(MetaStore),將這些指令翻譯成MapReduce(或者spark),提交到Hadoop中執行,最后,將執行返回的結果輸出到用戶交互接口。
1)用戶接口:Client
CLI(hive shell)、JDBC/ODBC(java訪問hive)、WEBUI(瀏覽器訪問hive)
2)元數據:Metastore
元數據包括:表名、表所屬的數據庫(默認是default)、表的擁有者、列/分區字段、表的類型(是否是外部表)、表的數據所在目錄等;
默認存儲在自帶的derby數據庫中,但是性能不好,推薦使用MySQL存儲Metastore
表中的數據是存儲在hdfs上的,只有表元數據才存儲在mysql中
3)Hadoop
使用HDFS進行存儲,使用MapReduce進行計算。
4)驅動器:Driver
(1)解析器(SQL Parser):將SQL字符串轉換成抽象語法樹AST,這一步一般都用第三方工具庫完成,比如antlr;對AST進行語法分析,比如表是否存在、字段是否存在、SQL語義是否有誤。
(2)編譯器(Physical Plan):將AST編譯生成邏輯執行計劃。
(3)優化器(Query Optimizer):對邏輯執行計劃進行優化。
(4)執行器(Execution):把邏輯執行計劃轉換成可以運行的物理計劃。對于Hive來說,就是MR/Spark。
| 項目 | 信息 |
|---|---|
| 主機 | bigdata121(192.168.50.121) |
| hadoop | 2.8.4(偽分布式搭建,一個datanode節點) |
| hive | 1.2.1 |
| mysql | 5.7 |
mysql,hadoop的部署不重復說明,看之前的文章。
解壓程序到/opt/modules,并重命名
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/modules/
mv /opt/modules/apache-hive-1.2.1-bin /opt/modules/hive-1.2.1-bin修改環境配置文件hive-env.sh
cd /opt/modules/hive-1.2.1-bin/conf
mv hive-env.sh.template hive-env.sh
添加如下配置:
(a)配置HADOOP_HOME路徑,hadoop家目錄
export HADOOP_HOME=/opt/modules/hadoop-2.8.4
(b)配置HIVE_CONF_DIR路徑。hive配置信息的目錄
export HIVE_CONF_DIR=/opt/modules/hive-1.2.1-bin/conf修改日志輸出配置 hive-log4j.properties
cd /opt/modules/hive-1.2.1-bin/conf
mv hive-log4j.properties.template hive-log4j.properties
修改為 hive.log.dir=/opt/module/hive-1.2.1-bin/logs配置hive環境變量:
vim /etc/profile.d/hive.sh
添加以下內容:
#!/bin/bash
export HIVE_HOME=/opt/modules/hive-1.2.1-bin
export PATH=$PATH:${HIVE_HOME}/bin
啟用環境變量
source /etc/profile.d/hive.sh這樣配置好后,就可以使用 hive 命令啟動hive了。默認元數據存儲在自帶的detry數據庫中
修改配置文件 conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata121:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore,jdbc連接字符串,并指定存儲元數據的庫名為 metastore,名字可以自定義</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore,連接驅動類</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database,mysql用戶</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>wjt86912572</value>
<description>password to use against metastore databasem,mysql密碼</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>指定default數據庫的在hdfs中存儲路徑</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>顯示表頭</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>顯示當前所在數據庫的名字</description>
</property>
</configuration>接著自己下載 mysql-connector-java-5.1.27.jar(版本可自行選擇),就是一個jdbc的jar包而已,然后放到 /opt/modules/hive-1.2.1-bin/lib 下。
接著,初始化元數據的數據庫在mysql中的數據,并遷移detry的數據到mysql中
schematool -dbType mysql -initSchema
這個命令在 /opt/modules/hive-1.2.1-bin/bin 下最后出現類似下面的字眼,表示初始化完成
schemeTool completed如果出現下面的問題:
Metastore connection URL: jdbc:mysql://bigdata121:3306/metastore?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 1.2.0
Initialization script hive-schema-1.2.0.mysql.sql
Error: Duplicate entry '1' for key 'PRIMARY' (state=23000,code=1062)
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!
*** schemaTool failed ***解決方法:
到mysql手動刪除剛才創建的數據庫 drop database metastore,然后再執行一次上面的初始化命令即可初始化完成后,就可以啟動hive了。
默認是存儲在 /user/hive/warehouse/下,每個庫有自己獨立的目錄,以 databaseName.db 命名,庫目錄下則是 每個表,每個表以表名命名目錄,目錄下存儲表數據。
? 默認情況下,hive都是直接根據hive-site.xml中配置的元數據庫的連接信息直接連接mysql的,而且同時只能一個hive客戶端連接元數據庫(怕有事務問題)。而metaserver是一個元數據庫server,它直接連接mysql,其他hive客戶端通過metaserver來間接連接mysql,讀取元數據信息。此時允許多個hive客戶端連接,且不需要指定連接MySQL的地址、用戶名密碼等信息。當然作為hive client,可以在配置文件中指定連接mysql的用戶信息,但是一般需要創建多個mysql用戶,用于給不同的hive client連接mysql,比較繁瑣。一般用在公司內部
? 一般在生產環境中,都是在一臺主機上配置了一個metaServer,然后在其他多臺主機上配置hive client。而metaServer所在主機權限要求高,不允許其他人任意訪問,而hive client的主機則是可以給低權限的人使用。一定程度上保護了元數據庫mysql的隱秘性。
| 主機 | 功能 |
|---|---|
| bigdata121(192.168.50.121) | hive metastore,mysql |
| bigdata122(192.168.50.122) | hive client |
配置:
1>bigdata121:
vim conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata121:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore,jdbc連接字符串,并指定存儲元數據的庫名為 metastore,名字可以自定義</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore,連接驅動類</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database,mysql用戶</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>wjt86912572</value>
<description>password to use against metastore databasem,mysql密碼</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>指定default數據庫的在hdfs中存儲路徑</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>顯示表頭</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>顯示當前所在數據庫的名字</description>
</property>
<!-- 指定zk集群的地址以及端口,用于訪問hbase中的hmaster-->
<property>
<name>hive.zookeeper.quorum</name>
<value>bigdata121,bigdata122,bigdata123</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<!--=========這里就是metastore server 的配置-->
<!--指定metastoreserver的服務端地址-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata121:9083</value>
</property>
</configuration>配置完成后,啟動metastore server:
hive --service metastore &
netstat -tnlp | grep 9083 看對應端口起來沒2> bigdata122:
vim conf/hive-site.xml
</configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>指定default數據庫的在hdfs中存儲路徑 </description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>顯示表頭</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>顯示當前所在數據庫的名字</description>
</property>
<!-- 指定zk集群的地址以及端口,用于訪問hbase中的hmaster-->
<property>
<name>hive.zookeeper.quorum</name>
<value>bigdata121,bigdata122,bigdata123</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<!--指定metastoreserver的連接URL,用于hiveclient連接元數據庫-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata121:9083</value>
</property>
</configuration>
hive client的配置就比較簡單了,不需要再配置mysql的連接信息了,直接配置hive在hdfs的數據目錄,以及hive metastore server的連接地址就可以了配置完成后,直接hive啟動client就可以連接metastore,然后使用hive了。
不需要啟動hiveserver,因為本身hive命令就是一個hiveserver
? 默認情況下,hive只允許hive client連接hive,因為這種情況hive不需要啟動server服務,每個hive client本質上都是在自己本地啟動了一個hive server,然后連接metastore server,讀取hdfs的數據目錄,這樣就可以使用hive服務了。
? 如果需要通過jdbc這樣的方式連接hive,那么就需要將hive以后臺服務的形式啟動了,需要提供對應的地址以及端口給jdbc連接。要注意,這個hiveserver和前面的metastore server沒有啥關系,兩個是獨立的進程。而且hive server啟動之后,內部也會有一個內置的metastore server,這個才是自己用的,外部無法使用。所以這兩者是不同使用場景下的產物,注意區分。
在bigdata121(192.168.50.121) 上配置hive server
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata121:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore,jdbc連接字符串,并指定存儲元數據的庫名為 metastore,名字可以自定義</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore,連接驅動類</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database,mysql用戶</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>wjt86912572</value>
<description>password to use against metastore databasem,mysql密碼</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>指定default數據庫的在hdfs中存儲路徑</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>顯示表頭</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>顯示當前所在數據庫的名字</description>
</property>
<!-- 指定zk集群的地址以及端口,用于訪問hbase中的hmaster-->
<property>
<name>hive.zookeeper.quorum</name>
<value>bigdata121,bigdata122,bigdata123</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
// metastore這里沒有用,
<!--指定metastoreserver的服務端地址-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata121:9083</value>
</property>
<!--指定hiveserver的服務端地址,端口-->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>bigdata121</value>
<!--更改為自己的主機名字-->
</property>
<property>
<name>hive.server2.long.polling.timeout</name>
<value>5000</value>
</property>
</configuration>啟動hiveserver:
hive --service hiveserver2 &
n | grep 10000 查看端口起來沒接著再bigdata122上測試下jdbc,在hive的bin下有個命令:
bin/beeline
[root@bigdata122 hive-1.2.1-bin]# bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://bigdata121:10000 這里就是測試jdbc連接hive server了
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/modules/hbase-1.3.1/lib/phoenix-4.14.2-HBase-1.3-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/modules/hadoop-2.8.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Connecting to jdbc:hive2://bigdata121:10000
Enter username for jdbc:hive2://bigdata121:10000:
Enter password for jdbc:hive2://bigdata121:10000:
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://bigdata121:10000> 這里顯示已經成功連接
0: jdbc:hive2://bigdata121:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| test |
+----------------+--+hive -options
直接輸出 hive 命令即可進入hive操作命令行
常用options:
--database databaseName: 指定進入某個庫
-e SQL:不進入hive,直接執行sql命令,結果在命令行返回
-f xxx.sql:執行文件中的sql,結果直接返回進入hive之后常用的操作命令:
exit/quit:退出hive
dfs xxx :在hive中對hdfs進行操作
! shellCommand:在hive中直接執行shell命令
~/.hivehistory:這是記錄hive歷史命令的文件(1)可以在 hive-site.xml 中配置參數
(2)在啟動hive時通過 -hiveconf param=value,參數只對本次啟動有效
(3)在hive中通過 set param=value; 配置,可以通過 set param查看參數配置的value
上述三種設定方式的優先級依次遞增。即配置文件<命令行參數<參數聲明。注意某些系統級的參數,例如log4j相關的設定,必須用前兩種方式設定,因為那些參數的讀取在會話建立以前已經完成了。| hive數據類型 | java數據類型 | 長度 | 例子 |
|---|---|---|---|
| BOOLEAN | boolean | 布爾類型,true或者false | TRUE FALSE |
| TINYINT | byte | 1byte有符號整數 | 20 |
| SMALINT | short | 2byte有符號整數 | 20 |
| INT | int | 4byte有符號整數 | 20 |
| BIGINT | long | 8byte有符號整數 | 20 |
| FLOAT | float | 單精度浮點數 | 3.14159 |
| DOUBLE | double | 雙精度浮點數 | 3.14159 |
| STRING | string | 字符系列。可以指定字符集。可以使用單引號或者雙引號。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 時間類型 | ||
| BINARY | 字節數組 |
| 數據類型 | 描述 | 語法實例 |
|---|---|---|
| STRUCT | 和c語言中的struct類似,都可以通過“點”符號訪問元素內容。例如,如果某個列的數據類型是STRUCT{first STRING, last<br/>STRING},那么第1個元素可以通過字段.first來引用。 | struct() |
| MAP | MAP是一組鍵-值對元組集合,使用數組表示法可以訪問數據。例如,如果某個列的數據類型是MAP,其中鍵->值對是’first’->’John’和’last’->’Doe’,那么可以通過字段名[‘last’]獲取最后一個元素 | map() |
| ARRAY | 數組是一組具有相同類型和名稱的變量的集合。這些變量稱為數組的元素,每個數組元素都有一個編號,編號從零開始。例如,數組值為[‘John’, ‘Doe’],那么第2個元素可以通過數組名[1]進行引用。 | Array() |
其中map和struct有點相似,但其實struct中不存在key的概念,但是類似key,就相當于struct內部本身就定義了一個個的屬性的名稱,我們填充的只是這些已有屬性對應的value而已。所以key對于struct來說是已存在的。而map就很好理解了,key和value都是任意的,都是,兩個都是數據,填充數據時需要同時輸入key和value。
使用例子:
假設某表有一行數據如下(轉化為json格式顯示):
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //鍵值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //結構Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}原始數據如下:
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
不同字段的數據用“,”分隔,同一字段內的多個值用“_”分隔,KV之間用“:”分隔創建測試表(后面會講用法,先看看):
create table test(
name string,
friends array<string>,
children map<string, int>, map就是定義KV的類型即可
address struct<street:string, city:string> 結構體是在定義時就指定有哪些key,然后填充value
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
字段解釋:
row format delimited fields terminated by ',' -- 列分隔符
collection items terminated by '_' --MAP STRUCT 和 ARRAY 的分隔符(數據分割符號)
map keys terminated by ':' -- MAP中的key與value的分隔符
lines terminated by '\n'; -- 行分隔符導入數據:
hive (default)> load data local inpath '/opt/module/datas/test.txt' into table test;查詢數據:
hive (default)> select friends[1],children['xiao song'],address.city from test where name="songsong";
OK
_c0 _c1 city
lili 18 beijing
Time taken: 0.076 seconds, Fetched: 1 row(s)Hive的原子數據類型是可以進行隱式轉換的,類似于Java的類型轉換,例如某表達式使用INT類型,TINYINT會自動轉換為INT類型,但是Hive不會進行反向轉化,例如,某表達式使用TINYINT類型,INT不會自動轉換為TINYINT類型,它會返回錯誤,除非使用CAST操作。
1)隱式類型轉換規則如下。
(1)任何整數類型都可以隱式地轉換為一個范圍更廣的類型,如TINYINT可以轉換成INT,INT可以轉換成BIGINT。
(2)所有整數類型、FLOAT和STRING類型都可以隱式地轉換成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以轉換為FLOAT。
(4)BOOLEAN類型不可以轉換為任何其它的類型。
2)可以使用CAST操作顯示進行數據類型轉換,例如CAST('1' AS INT)將把字符串'1' 轉換成整數1;如果強制類型轉換失敗,如執行CAST('X' AS INT),表達式返回空值 NULL。
下面開始講HQL的使用
create database [if not exists] DBNAME [location PATH];
if not exists:庫存在就不創建,不存在就創建
location PATH:指定庫在hdfs中的存儲路徑 用戶可以使用ALTER DATABASE命令為某個數據庫的DBPROPERTIES設置鍵-值對屬性值,來描述這個數據庫的屬性信息。數據庫的其他元數據信息都是不可更改的,包括數據庫名和數據庫所在的目錄位置。\
alter database DBNAME set dbproperties('param'='value');
如:修改創建時間
alter database db_hive set dbproperties('createtime'='20180830');查看數據庫基本信息:show databases
查看詳細信息:desc database DBNAME
查看數據庫更詳細的信息:desc database extended DBNAMEdrop database [if exists] DBNAME [cascade]
if exists:最好用判斷庫是否存在,不然容易報錯。
cascade:強制刪除非空的庫,默認只能刪除空的庫CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[LIKE DBNAME]
字段解釋:
(1)EXTERNAL:創建一個外部表,默認創建的是內部表。后面有講兩者的區別
(2)COMMENT:為表和列添加注釋,后面有說
(3)PARTITIONED BY創建分區表,后面有說
(4)CLUSTERED BY創建分桶表,后面有說
(5)SORTED BY不常用:mr內部排序,后面有說
(6)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATE D BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
這些定義的輸出數據的格式,分別依次是 字段分隔符、值分隔符、KV分隔符、行分隔符
(7)STORED AS指定存儲文件類型
大體上分為行存儲和列式存儲,后面有講,默認是textfile,即行存儲文本格式
(8)LOCATION :指定表在HDFS上的存儲位置。指定數據加載路徑,將文件放到該路徑下,無需load即可自動加載數據。如果是自己獨立創建分區目錄,則需要手動load
(9)LIKE:允許用戶復制現有的表結構,但是不復制數據
例子:
create table if not exists student2(
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student2';查看表基本信息:desc TABLENAME
查看詳細信息:desc formatted TABLENAME內部表和外部表的區別:
外部表:在使用drop刪除外部表時,只會刪除表結構,不會刪除數據
內部表:也稱為管理表,在使用drop刪除外部表時,表結構和數據都會刪除
一般來說,外部表用來存儲原始收集過來的數據,不允許輕易刪除,所以使用外部表來保存很適合。后面基于外部表數據分析,需要存儲一些中間結果表時,這時候用內部表很適合,可以隨時刪除表結構和數據。查看表的類型
desc formatted TABLEName;
.....
Table Type: EXTERNAL_TABLE(外部表)/ MANAGED_TABLE(內部表)
.....分區表其實就將一個表的數據劃分為幾個分區,每個分區在表的存儲目錄下獨立創建一個分區目錄,目錄命名為:“分區key=value”的形式,如:“month=201902”,目錄下存儲該文件的數據文件。并且查詢時可通過where語句來查詢指定分區的數據。一定程度上減少了一次性讀取數據的壓力。比如按天分區,每天的數據單獨存儲。也便于管理。
(1)創建分區表
create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (month string)
row format delimited fields terminated by '\t';
其中partitioned by (month string) 就是定義分區的字段名稱以及類型。注意這個字段并不是數據本身的字段,而是人為定義的。而且使用select查看表數據時,會顯示該字段。(2)加載數據到指定分區
load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201809');
必須以month=value的形式指定,否則報錯,會在表目錄下創建目錄名為 month=201809 ,然后將數據文件保存到該目錄下
load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201807');
如果分區已存在,則會將新的數據文件放到同一分區目錄下 (3)查看分區表數據
select * from dept_partition where month='201809';
_u3.deptno _u3.dname _u3.loc _u3.month
10 ACCOUNTING NEW YORK 201809
可以看到month是作為字段顯示出來的(4)增加分區
創建單個分區:
hive (default)> alter table dept_partition add partition(month='201806') ;
同時創建多個分區:
hive (default)> alter table dept_partition add partition(month='201805') partition(month='201804');
多個分區之間用空格分隔開(5)刪除分區
刪除單個分區:
hive (default)> alter table dept_partition drop partition (month='201804');
同時刪除多個分區:
hive (default)> alter table dept_partition drop partition (month='201805'), partition (month='201806');
多個分區之間用逗號分隔開(6)查看分區表有多少分區
hive>show partitions dept_partition;(7)查看分區表結構
hive>desc formatted dept_partition;
desc dept_partition 查看簡單的信息
.......
# Partition Information
# col_name data_type comment
month string
........(8)二級分區表
創建二級分區表:
create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t';
其實就是定義了兩個分區字段
加載數據到二級分區:
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition2 partition(month='201809', day='13');
查看數據:
hive (default)> select * from dept_partition2 where month='201809' and day='13';(9)分區表的存儲結構
會在表目錄下,創建 month=xxx 作為名字的目錄,二級分區類似(10)手動創建分區目錄并上傳數據的處理方式
手動創建分區目錄并上傳數據,是沒辦法直接通過select查看到數據的。處理方式如下
方式1:msck repair table tb_name 修復表
方式2:手動通過 alter table tb add parition(xxxx)添加分區
方式3:手動使用load加載數據到指定分區修改表名:
ALTER TABLE table_name RENAME TO new_table_name
更新列:更新單個字段
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
如: alter table dept_partition change column deptdesc desc int;
增加列:
alter table dept_partition add columns(deptdesc string);
替換列:注意這里是替換整個表的所有字段
alter table dept_partition replace columns(deptno string, dname string, loc string);drop table TB_NAMEhive>load data [local] inpath '/opt/module/datas/student.txt' [overwrite] into table student [partition (partcol1=val1,…)];
local:表示從本地加載數據到hive表;否則從HDFS加載數據到hive表。通過hdfs加載數據到表中時,會將文件剪切到表所在的路徑下。無論是外部表還是內部表
overwrite:表示覆蓋表中已有數據,否則表示追加,如果沒有overwrite的話,同名的文件加載進去時候,會重命名為 tableName_copy_1
partition:表示上傳到指定分區創建一張分區表方便用實例講解:
hive (default)> create table student2(id int, name string) partitioned by (month string) row format delimited fields terminated by '\t';
基本插入: insert into table student partition(month='201809') values(1,'wangwu');
單表查詢插入:
insert overwrite table student2 partition(month='201808')
select id, name from student where month='201809';
多表查詢插入:
from student
insert overwrite table student2 partition(month='201807')
select id, name where month='201809'
insert overwrite table student2 partition(month='201806')
select id, name where month='201809';create table if not exists student3
as select id, name from student;
一般用在結果表中,查詢完畢后保存結果到另外一張表create table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student5';
接著直接將數據上傳到上面指定的目錄下,就可直接select查詢到數據,無需再次手動load。如果沒有指定location,則默認表目錄為 /user/hive/warehouse/xxxx/下,且需要手動load數據這里只能導入使用export導出的數據,下面有講export
import table student2 partition(month='201809') from '/user/hive/warehouse/export/student';insert overwrite [local] directory'/opt/module/datas/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
local:表示導出到本地文件系統,否則導出到hdfs
導出時可以指定字段的分隔符、行分隔符等因為hive的數據文件就是文本文件,可以直接通過hdfs導出
hive (default)> dfs -get /user/hive/warehouse/student/month=201809/000000_0 /opt/module/datas/export/student3.txt;export table default.student to '/user/hive/warehouse/export/student';truncate table TB_NAMESELECT [ALL | DISTINCT] select_expr, elect_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]下面實例中涉及到幾個表:
員工表emp:
empno neame job mgr hiredate comm deptno
員工號 員工名 職位 領導 雇傭日期 薪資 部門號
部門表dept:
deptno dname loc
部門號 部門名 位置
位置信息表location:
loc loc_nmae
位置標號 位置名select 字段名 from table_name
字段名可以使用:字段名 as 別名 的方式來給字段定義別名
(1)對字段進行算術操作
例子:select sal +1 from emp;
(2)常用函數
1)求總行數(count)
hive (default)> select count(*) cnt from emp;
這里可以寫成count(1),比count(*)效率高
2)求工資的最大值(max)
hive (default)> select max(sal) max_sal from emp;
3)求工資的最小值(min)
hive (default)> select min(sal) min_sal from emp;
4)求工資的總和(sum)
hive (default)> select sum(sal) sum_sal from emp;
5)求工資的平均值(avg)
hive (default)> select avg(sal) avg_sal from emp;
(3)limit N
限制返回前N行where 判斷條件
判斷條件:
(1)比較運算符:常用的大于小于等,between and、in、is null用法和mysql類似
(2)like B:B是簡單的通配符字符串,
% 代表零個或多個字符(任意個字符)。
_ 代表一個字符
RLIKE B:這是使用標準的正則表達式
(3)邏輯運算符:AND OR NOTGROUP BY語句通常會和聚合函數一起使用,按照一個或者多個列隊結果進行分組,然后對每個組執行聚合操作。
案例實操:
(1)計算emp表每個部門的平均工資.以部門號分組
hive (default)> select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
(2)計算emp每個部門中每個崗位的最高薪水。以部門號分組
hive (default)> select t.deptno, t.job, max(t.sal) max_sal from emp t group by t.deptno, t.job;
注意:group by時要注意,前面select的字段,都要出現在group by里,例如
select id,name from a group id,name; 不可以寫成 select id,name from a group id;having和where用法一樣,區別如下:
(1)where針對表中的列發揮作用,查詢數據;having針對查詢結果中的列發揮作用,篩選數據。
(2)where后面不能寫分組函數,而having后面可以使用分組函數。
(3)having只用于group by分組統計語句。
例子:
求每個部門的平均薪水大于2000的部門
hive (default)> select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;hive僅僅支持等值連接,不支持非等值連接。注意join的on語句中,不支持使用 or 進行多條件聯合
select xx from A 別名1 join B 別名2 on 等值判斷
例子:
根據員工表和部門表的部門編號進行連接
select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno;JOIN操作符左邊表中符合WHERE子句的所有記錄將會被返回.
以左表為準,右表中的行沒有匹配到左表的,就直接去掉,匹配到的就顯示,如果右表有多行匹配左表的同一行,那么該行就會顯示多次。如果左表的行在右表中沒有匹配,右表的數據就會顯示為null
select xx from A 別名1 left join B 別名2 on 等值判斷
例子:
select e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno = d.deptno;和左連接,只不過將后面的表作為左表了。還是以左表為準進行連接
select xx from A 別名1 right join B 別名2 on 等值判斷
例子:
select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;顯示兩表的所有記錄,不匹配的就對應顯示為null
select xx from A 別名1 full join B 別名2 on 等值判斷
例子:
select e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno = d.deptno;連接 n個表,至少需要n-1個連接條件。例如:連接三個表,至少需要兩個連接條件。
例子:
SELECT e.ename, d.deptno, l. loc_name
FROM emp e
JOIN dept d
ON d.deptno = e.deptno
JOIN location l
ON d.loc = l.loc;
大多數情況下,Hive會對每對JOIN連接對象啟動一個MapReduce任務。本例中會首先啟動一個MapReduce job對表e和表d進行連接操作,然后會再啟動一個MapReduce job將第一個MapReduce job的輸出和表l;進行連接操作。
注意:為什么不是表d和表l先進行連接操作呢?這是因為Hive總是按照從左到右的順序執行的。Order By:全局排序,本質就是單獨啟動一個MapReduce用于全局排序
1)使用 ORDER BY 子句排序
ASC(ascend): 升序(默認)
DESC(descend): 降序
2)ORDER BY 子句在SELECT語句的結尾。
3)案例實操
(1)查詢員工信息按工資升序排列
hive (default)> select * from emp order by sal;
(2)查詢員工信息按工資降序排列
hive (default)> select * from emp order by sal desc;按照員工薪水的2倍排序
select ename, sal*2 twosal from emp order by twosal;按照部門和工資升序排序
hive (default)> select ename, deptno, sal from emp order by deptno, sal ;這個語句是用在MapReduce中每個分區的區內排序。最終每個reduce獨自輸出自己的排序結果,不會進行所有reduce的再一次排序
1)設置reduce個數
hive (default)> set mapreduce.job.reduces=3;
2)查看設置reduce個數
hive (default)> set mapreduce.job.reduces;
3)根據部門編號降序查看員工信息
hive (default)> select * from emp sort by empno desc;Distribute By:類似MR中partition,進行分區,即指定分區的字段是哪個,這里的分區和上面的partition的分區不是一個意思,要注意,這里指的是程序中的分區,上面指的是存儲的分區。結合sort by使用。
注意:Hive要求DISTRIBUTE BY語句要寫在SORT BY語句之前。
對于distribute by進行測試,一定要分配多reduce進行處理,否則無法看到distribute by的效果。
(1)先按照部門編號分區,再按照員工編號降序排序。
hive (default)> set mapreduce.job.reduces=3;
hive (default)> insert overwrite local directory '/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
這里寫到文件中,因為分區了,所以會產生多個文件(每個reduce一個文件),這樣便于查看分區的結果當distribute by和sorts by字段相同時,可以使用cluster by方式。
cluster by除了具有distribute by的功能外還兼具sort by的功能。但是排序只能是倒序排序,不能指定排序規則為ASC或者DESC。即實現指定字段分區,并對該字段排序
1)以下兩種寫法等價
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;
注意:按照部門編號分區,不一定就是固定死的數值,可以是20號和30號部門分到一個分區里面去。? 分區針對的是數據的存儲路徑;分桶針對的是數據文件。分桶之后,會將原先的數據文件直接分隔成多個桶文件,每個桶一個文件。分區只是將數據文件本身放到不同的分區目錄而已,不會對數據文件進行分割。
? 分區提供一個隔離數據和優化查詢的便利方式。不過,并非所有的數據集都可形成合理的分區,特別是之前所提到過的要確定合適的劃分大小這個疑慮。而分桶其實就是實現將一個大的數據文件根據分區字段自動分成幾個分區,這就是分桶的作用
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
字段解釋:
clustered by(id) :分桶的字段名
into 4 buckets:分桶個數
原始數據為:student.txt
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
使用分桶需要打開相應參數設置:
hive (default)> set hive.enforce.bucketing=true;
hive (default)> set mapreduce.job.reduces=-1;
接著另外創建一張同樣的表(沒有分桶),并導入數據:
create table stu2(id int, name string) row format delimited fields terminated by '\t';
load data local inpath '/opt/module/datas/student.txt' into table stu2;
接著通過子查詢的方式導入數據到分桶表(分桶表只能通過這種方式導入數據):
insert overwrite table stu_buck
select id, name from stu2;
查看分桶數據:
hive (default)> select * from stu_buck;
OK
stu_buck.id stu_buck.name
1016 ss16
1012 ss12
1008 ss8
1004 ss4
1009 ss9
1005 ss5
1001 ss1
1013 ss13
1010 ss10
1002 ss2
1006 ss6
1014 ss14
1003 ss3
1011 ss11
1007 ss7
1015 ss15
可以看到一般情況下,應該是按id有序顯示的,但是這里明顯不是,這就是分桶的影響了
查看分桶表的信息:
desc formatted stu_buck;對于非常大的數據集,有時用戶需要使用的是一個具有代表性的查詢結果而不是全部結果。Hive可以通過對表進行抽樣來滿足這個需求。
查詢表stu_buck中的數據。
hive (default)> select * from stu_buck tablesample(bucket 1 out of 4 on id);
注:tablesample是抽樣語句,語法:TABLESAMPLE(BUCKET x OUT OF y) 。
y必須是table總bucket數的倍數或者因子。hive根據y的大小,決定抽樣的比例。例如,table總共分了4份,當y=2時,抽取(4/2=)2個bucket的數據,當y=8時,抽取(4/8=)1/2個bucket的數據。
(個人理解)y表示的是抽樣的間隔的bucket的個數,比如2,表示中間空一個bucket,然后再抽。如果y大于bucket的個數,那么就會在第一個開始抽樣的bucket中繼續進行剩下的間隔性抽樣。如bucket數為4,y=12,那么最后肯定只有第一個開始抽的bucket會被抽樣,在這個bucket中會抽取 4/12=1/3 個數據。
x表示從哪個bucket開始抽取。例如,table總bucket數為4,tablesample(bucket 4 out of 4),表示總共抽取(4/4=)1個bucket的數據,抽取第4個bucket的數據。
注意:x的值必須小于等于y的值,否則
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck1)查看系統自帶的函數
hive> show functions;
2)顯示自帶的函數的用法
hive> desc function upper;
3)詳細顯示自帶的函數的用法
hive> desc function extended upper;如果自帶的函數滿足不了需求,可以自定義函數,稱為UDF--user defined function
根據用戶自定義函數類別分為以下三種:
(1)UDF(User-Defined-Function)
一進一出
(2)UDAF(User-Defined Aggregation Function)
聚集函數,多進一出
類似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一進多出
如lateral view explore()自定義函數的步驟:
(1)繼承org.apache.hadoop.hive.ql.UDF
(2)需要實現evaluate函數;evaluate函數支持重載;
(3)在hive的命令行窗口創建函數
a)添加jar
add jar linux_jar_path
b)創建function,
create [temporary] function [dbname.]function_name AS
class_name;
后面就可以使用 function_name 來調用函數
(4)在hive的命令行窗口刪除函數
Drop [temporary] function [if exists] [dbname.]function_name;當hive底層使用MapReduce時,使用壓縮功能需要hadoop本身開啟相應的配置,以及相應的壓縮格式的jar包依賴。關于這內容不重復說,看之前的“hadoop-壓縮”中的配置。下面講的是hive中的配置。
開啟map輸出階段壓縮可以減少job中map和Reduce task間數據傳輸量。具體配置如下:
1)開啟hive中間傳輸數據壓縮功能
hive (default)>set hive.exec.compress.intermediate=true;
2)開啟mapreduce中map輸出壓縮功能
hive (default)>set mapreduce.map.output.compress=true;
3)設置mapreduce中map輸出數據的壓縮方式,這里使用snappy
hive (default)>set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
4)執行查詢語句
hive (default)> select count(ename) name from emp;當Hive將輸出寫入到表中時,輸出內容同樣可以進行壓縮。屬性hive.exec.compress.output控制著這個功能。用戶可能需要保持默認設置文件中的默認值false,這樣默認的輸出就是非壓縮的純文本文件了。用戶可以通過在查詢語句或執行腳本中設置這個值為true,來開啟輸出結果壓縮功能。
1)開啟hive最終輸出數據壓縮功能
hive (default)>set hive.exec.compress.output=true;
2)開啟mapreduce最終輸出數據壓縮
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
3)設置mapreduce最終數據輸出壓縮方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
4)設置mapreduce最終數據輸出壓縮為塊壓縮
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5)測試一下輸出結果是否是壓縮文件,如果開啟壓縮的話,輸出的文件就是壓縮格式的
hive (default)> insert overwrite local directory '/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;hive主要分為行存儲和列存儲兩大類,主要格式有:
行存儲:TEXTFILE(文本格式) 、SEQUENCEFILE(二進制格式)
列存儲:ORC(Optimized Row Columnar,默認開啟壓縮,且采用zlib壓縮)、PARQUET,這兩種格式的存儲原理可自行學習,這里不詳細說明
行存儲的特點: 查詢滿足條件的一整行數據的時候,列存儲則需要去每個聚集的字段找到對應的每個列的值,行存儲只需要找到其中一個值,其余的值都在相鄰地方,所以此時行存儲查詢的速度更快。一行的數據都是連續存儲的。
列存儲的特點: 因為每個字段的數據聚集存儲,在查詢只需要少數幾個字段的時候,能大大減少讀取的數據量;每個字段的數據類型一定是相同的,列式存儲可以針對性的設計更好的設計壓縮算法。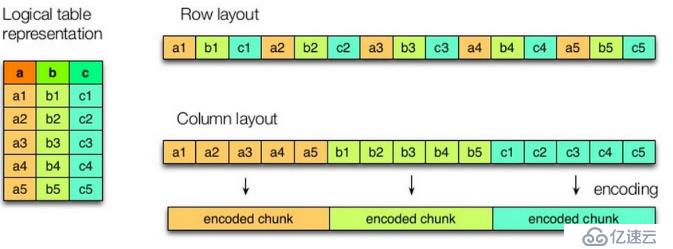
? 圖8.1 hive之列和行存儲
這是行和列存儲的架構圖,可以明顯看到區別
使用 stored as xxx 關鍵字指定存儲格式
如:
create table log_text (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as textfile ; 這里就指定為textfile格式,也是默認的存儲格式
由于默認情況下,列存儲都會采用壓縮方式存儲,而行存儲則不會。所以一般占用空間排名為:
從小到大排序 ORC > Parquet > textFile創建表指定存儲格式以及壓縮方式:
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc tblproperties ("orc.compress"="SNAPPY");
其中tblproperties是用來指定orc 的工作參數的,里面是有key=value的形式來指定參數。orc.compress 是指定orc使用的壓縮格式,這里指定是用SNAPPY? hive在生產環境中一般用于存儲結構化數據。比如一般情況下,會從生產數據庫中(比如mysql)中定時讀取數據寫入到hive,然后其他程序再從hive中讀取數據進行分析處理。所以hive是充當數據倉庫的作用
? mysql和hive都支持int類型,但是兩者的可解析范圍是不同的,mysql中的int類型課表示的數字范圍大于hive中的int,這就導致一個問題,那就是當mysql中的int的值大于這個界限時,就無法在hive中正常解析,通常也就會導入失敗。
? 所以為了避免這種情況,建議導入hive中的表的所有字段都設置為string類型,這樣可以避免這些問題。當需要將字段類型轉為實際類型時,在使用時再進行轉換即可
當然這點其實在spark sql中也適用,畢竟它們都并不完全兼容標準的sql
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





