溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
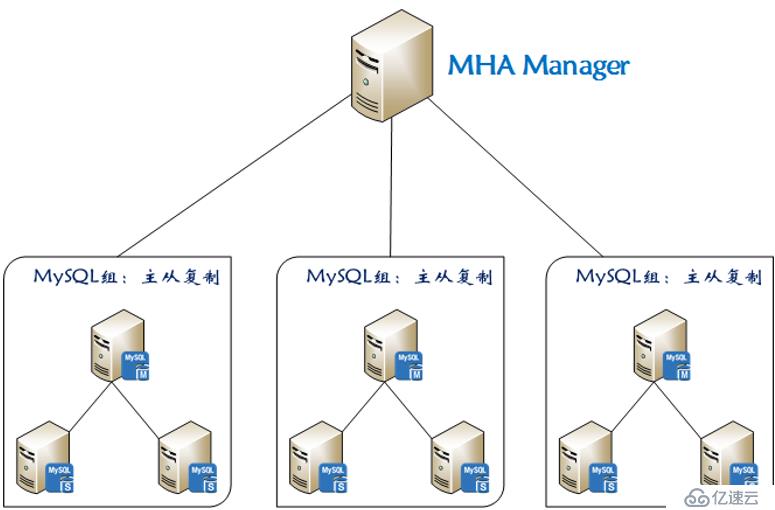
MHA(Master High Availability)目前在MySQL高可用方面是一個相對成熟的解決方案,它由日本DeNA公司youshimaton(現就職于Facebook公司)開發,是一套優秀的作為MySQL高可用性環境下故障切換和主從提升的高可用軟件。在MySQL故障切換過程中,MHA能做到在0~30秒之內自動完成數據庫的故障切換操作,并且在進行故障切換的過程中,MHA能在最大程度上保證數據的一致性,以達到真正意義上的高可用。 MHA里有兩個角色一個是MHA Node(數據節點)另一個是MHA Manager(管理節點)。
- MHA Manager可以單獨部署在一臺獨立的機器上管理多個master-slave集群,也可以部署在一臺slave節點上。
- MHA Node運行在每臺MySQL服務器上,MHA Manager會定時探測集群中的master節點,當master出現故障時,它可以自動將最新數據的slave提升為新的master,然后將所有其他的slave重新指向新的master。整個故障轉移過程對應用程序完全透明。
MHA自動故障切換過程中,MHA試圖從宕機的主服務器上保存二進制日志,最大程度的保證數據的不丟失,但這并不總是可行的。例如,如果主服務器硬件故障或無法通過ssh訪問,MHA沒法保存二進制日志,只進行故障轉移而丟失了最新的數據。使用MySQL 5.5的半同步復制,可以大大降低數據丟失的風險。MHA可以與半同步復制結合起來。如果只有一個slave已經收到了最新的二進制日志,MHA可以將最新的二進制日志應用于其他所有的slave服務器上,因此可以保證所有節點的數據一致性。
- 異步復制(Asynchronous replication) MySQL默認的復制即是異步的,主庫在執行完客戶端提交的事務后會立即將結果返給給客戶端,并不關心從庫是否已經接收并處理,這樣就會有一個問題,主如果crash掉了,此時主上已經提交的事務可能并沒有傳到從上,如果此時,強行將從提升為主,可能導致新主上的數據不完整。
- 全同步復制(Fully synchronous replication) 指當主庫執行完一個事務,所有的從庫都執行了該事務才返回給客戶端。因為需要等待所有從庫執行完該事務才能返回,所以全同步復制的性能必然會收到嚴重的影響。
- 半同步復制(Semisynchronous replication) 介于異步復制和全同步復制之間,主庫在執行完客戶端提交的事務后不是立刻返回給客戶端,而是等待至少一個從庫接收到并寫到relay log中才返回給客戶端。相對于異步復制,半同步復制提高了數據的安全性,同時它也造成了一定程度的延遲,這個延遲最少是一個TCP/IP往返的時間。所以,半同步復制最好在低延時的網絡中使用。
總結:
異步與半同步異同 默認情況下MySQL的復制是異步的,Master上所有的更新操作寫入Binlog之后并不確保所有的更新都被復制到Slave之上。異步操作雖然效率高,但是在Master/Slave出現問題的時候,存在很高數據不同步的風險,甚至可能丟失數據。 MySQL5.5引入半同步復制功能的目的是為了保證在master出問題的時候,至少有一臺Slave的數據是完整的。在超時的情況下也可以臨時轉入異步復制,保障業務的正常使用,直到一臺salve追趕上之后,繼續切換到半同步模式。
相較于其它HA軟件,MHA的目的在于維持MySQL Replication中Master庫的高可用性,其最大特點是可以修復多個Slave之間的差異日志,最終使所有Slave保持數據一致,然后從中選擇一個充當新的Master,并將其它Slave指向它。 從宕機崩潰的master保存二進制日志事件(binlogevents)。 識別含有最新更新的slave。應用差異的中繼日志(relay log)到其它slave。 應用從master保存的二進制日志事件(binlogevents)。 提升一個slave為新master。 使其它的slave連接新的master進行復制。
目前MHA主要支持一主多從的架構,要搭建MHA,要求一個復制集群中必須最少有三臺數據庫服務器,一主二從,即一臺充當master,一臺充當備用master,另外一臺充當從庫,因為至少需要三臺服務器。
| 主機 | 操作系統 | IP地址 |
|---|---|---|
| master1 | CentOS 7.3 | 192.168.1.1 |
| master2(備主) | CentOS 7.3 | 192.168.1.8 |
| slave1 | CentOS 7.3 | 192.168.1.9 |
| manager | CentOS 7.3 | 192.168.1.3 |
其中master對外提供寫服務,備選master2提供讀服務,slave也提供相關的讀服務,一旦master1宕機,將會把master2提升為新的master,slave指向新的master,manager作為管理服務器。
案例中關閉防火墻、selinux
# systemctl stop firewalld
# setenforce 0修改hosts文件,并傳到其他主機
[root@master1 ~]# vim /etc/hosts
192.168.1.1 master1
192.168.1.8 master2
192.168.1.9 slave1
192.168.1.3 manager
[root@master1 ~]# for i in master2 slave1 manager ; do scp /etc/hosts $i:/etc/hosts ; done配置NTP時間同步(master1):
[root@master1 ~]# vim /etc/chrony.conf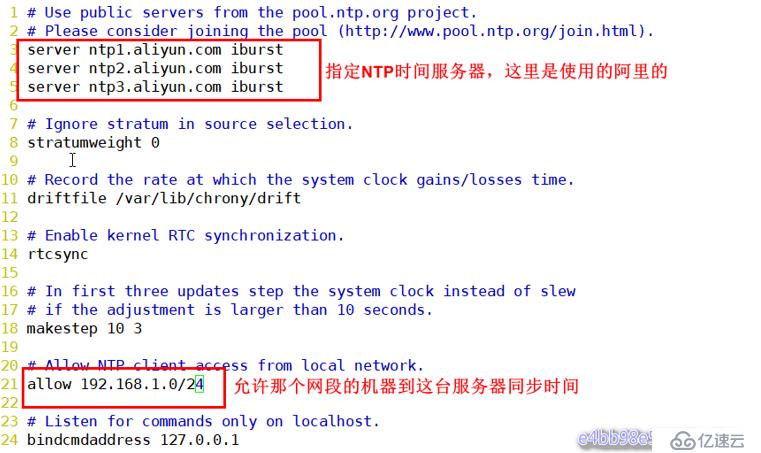
在其他服務器的配置文件中指向master1的IP地址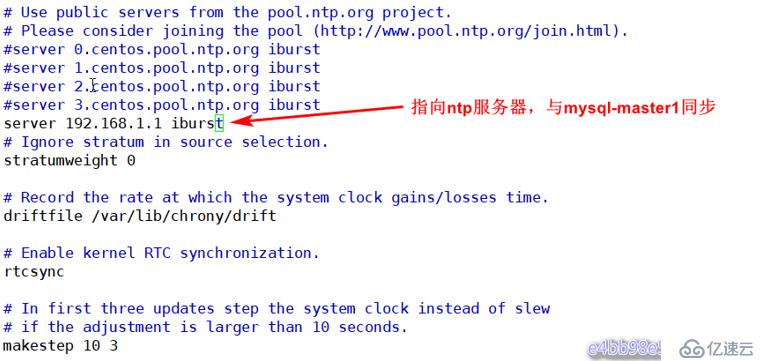
配置完成后,重新啟動chronyd服務,配置開機自啟
# systemctl restart chronyd
# systemctl enable chronyd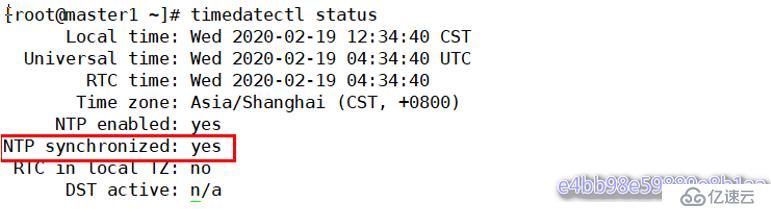
https://developer.aliyun.com/mirror/
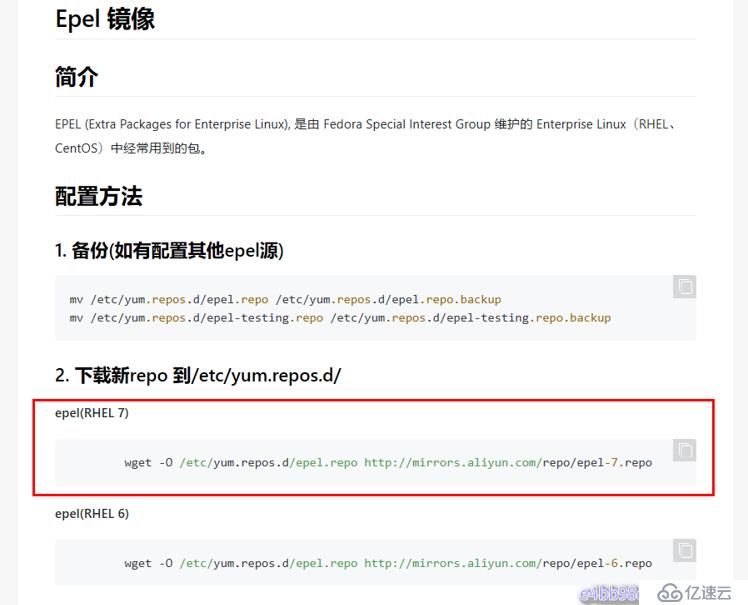
# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo# ssh-keygen -t rsa
# for host in master1 master2 slave1 manager ;do ssh-copy-id -i ~/.ssh/id_rsa.pub $host;done測試ssh無交互登錄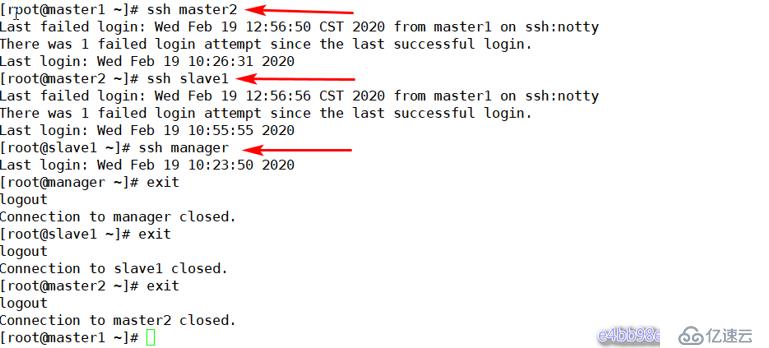
在其他主機上執行同樣的測試操作。
為了盡可能的減少主庫硬件損壞宕機造成的數據丟失,因此在配置MHA的同時建議配置成MySQL的半同步復制。
PS:mysql半同步插件是由谷歌提供,具體位置/usr/local/mysql/lib/plugin/下,一個是master用的semisync_master.so,一個是slave用的semisync_slave.so。
下面就來具體配置一下。 如果不清楚Plugin的目錄,用如下查找:
[root@master1 ~]# mysql -uroot -p123.com
mysql> show variables like '%plugin_dir%';
mysql> show variables like '%have_dynamic%';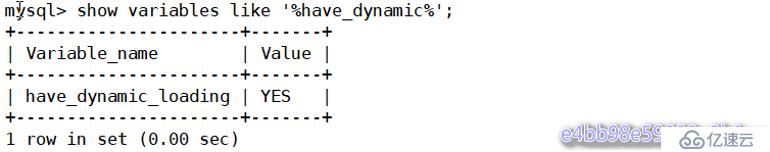
所有MySQL數據庫服務器,安裝半同步插件(semisync_master.so,semisync_slave.so)
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (0.01 sec)
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
Query OK, 0 rows affected (0.01 sec)
其他mysql主機采用同樣的方法安裝 檢查Plugin是否已正確安裝:
mysql> show plugins\G
或:
mysql> select * from information_schema.plugins\G;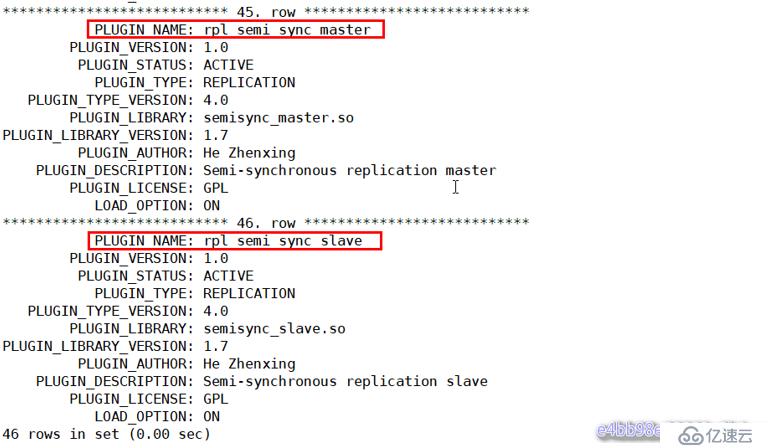
查看半同步相關信息
mysql> show variables like '%rpl_semi_sync%';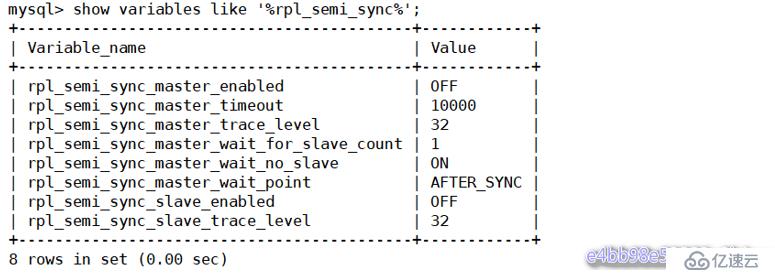
可以看到半同復制插件已經安裝,只是還沒有啟用,所以是off
PS:若主MYSQL服務器已經存在,只是后期才搭建從MYSQL服務器,在置配數據同步前應先將主MYSQL服務器的要同步的數據庫拷貝到從MYSQL服務器上(如先在主MYSQL上備份數據庫,再用備份在從MYSQL服務器上恢復)
在DB的配置文件中添加:
master1主機:
[root@master1 ~]# vim /etc/my.cnf
server-id=1
log-bin=mysql-bin //二進制日志
binlog_format=mixed //binlog日志格式,mysql默認采用statement,建議使用mixed
log-bin-index=mysql-bin.index
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000
rpl_semi_sync_slave_enabled=1
relay_log_purge=0
relay-log = relay-bin //中繼日志,存儲所有主庫TP過來的binlog事件
relay-log-index=slave-relay-bin.indexPS:
- rpl_semi_sync_master_enabled=1 //1表是啟用,0表示關閉
- rpl_semi_sync_master_timeout=10000:毫秒單位 ,該參數主服務器等待確認消息10秒后,不再等待,變為異步方式。
- relay_log_purge=0,禁止 SQL 線程在執行完一個 relay log 后自動將其刪除,對于MHA場景下,對于某些滯后從庫的恢復依賴于其他從庫的relay log,因此采取禁用自動刪除功能
master2主機:
[root@master2 ~]# vim /etc/my.cnf
server-id=2
log-bin=mysql-bin
binlog_format=mixed
log-bin-index=mysql-bin.index
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=10000
rpl_semi_sync_slave_enabled=1
relay_log_purge=0
relay-log = relay-bin
relay-log-index=slave-relay-bin.indexslave1主機:
[root@slave1 ~]# vim /etc/my.cnf
server-id=3
log-bin=mysql-bin
relay-log=relay-bin
relay-log-index=slave-relay-bin.index
read_only=1
rpl_semi_sync_slave_enabled=1重啟服務,查看半同步相關信息
# systemctl restart mysqld
[root@master1 ~]# mysql -uroot -p123.com
mysql> show variables like '%rpl_semi_sync%';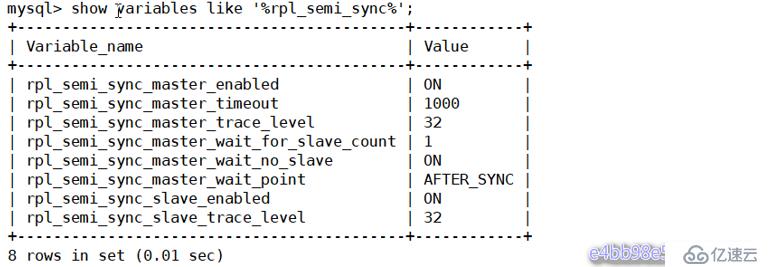
查看半同步狀態:
mysql> show status like '%rpl_semi_sync%';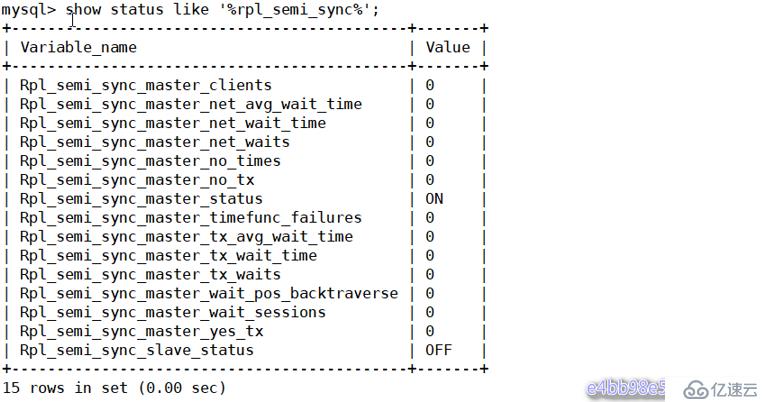
有幾個狀態參數值得關注的:
- rpl_semi_sync_master_status:顯示主服務是異步復制模式還是半同步復制模式
- rpl_semi_sync_master_clients :顯示有多少個從服務器配置為半同步復制模式
- rpl_semi_sync_master_yes_tx :顯示從服務器確認成功提交的數量
- rpl_semi_sync_master_no_tx :顯示從服務器確認不成功提交的數量
- rpl_semi_sync_master_tx_avg_wait_time :事務因開啟 semi_sync ,平均需要額外等待的時間
- rpl_semi_sync_master_net_avg_wait_time :事務進入等待隊列后,到網絡平均等待時間
在DB上創建授權用戶
master1:
創建用于主從復制的賬號(master1,master2都要創建):
mysql> grant replication slave on *.* to mharep@'192.168.1.%' identified by '123.com';
Query OK, 0 rows affected, 1 warning (1.01 sec)創建MHA管理賬號(三臺DB服務器)MHA會在配置文件里要求能遠程登錄到數據庫,所以要進行必要的賦權:
mysql> grant all privileges on *.* to manager@'192.168.1.%' identified by '123.com';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show master status;
master2主機:
[root@master2 ~]# mysql -uroot -p123.com
mysql> grant replication slave on *.* to mharep@'192.168.1.%' identified by '123.com'; //主從復制賬號
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> grant all privileges on *.* to manager@'192.168.1.%' identified by '123.com'; //MHA管理賬號
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> change master to master_host='192.168.1.1',master_port=3306,master_user='mharep',master_password='123.com',master_log_file='mysql-bin.000001',master_log_pos=742;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
mysql> start slave; //開啟主從同步
Query OK, 0 rows affected (0.01 sec)查看從的狀態,以下兩個值必須為yes,代表從服務器能正常連接主服務器
mysql> show slave status\G;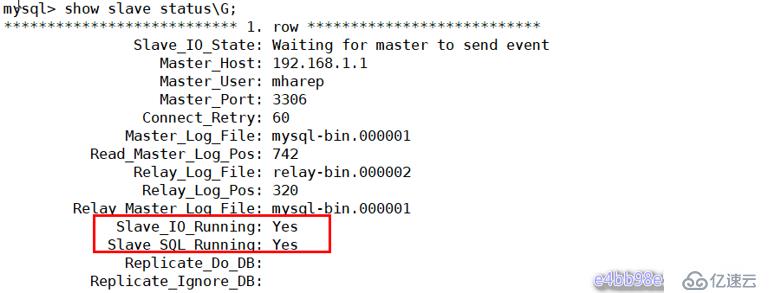
slave1主機:
[root@slave1 ~]# mysql -uroot -p123.com
mysql> grant all privileges on *.* to manager@'192.168.1.%' identified by '123.com'; //MHA管理賬號
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> change master to master_host='192.168.1.1',master_port=3306,master_user='mharep',master_password='123.com',master_log_file='mysql-bin.000001',master_log_pos=742;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)查看從的狀態,以下兩個值必須為yes,代表從服務器能正常連接主服務器
mysql> show slave status\G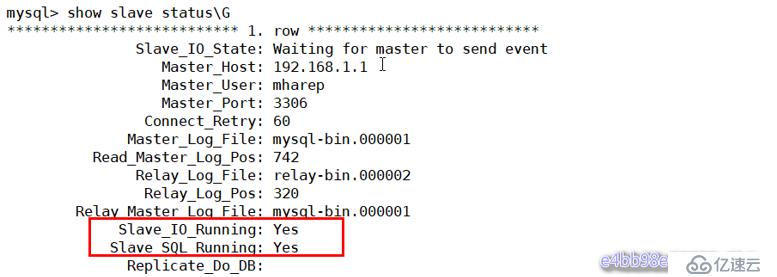
查看master服務器的半同步狀態:
mysql> show status like '%rpl_semi_sync%';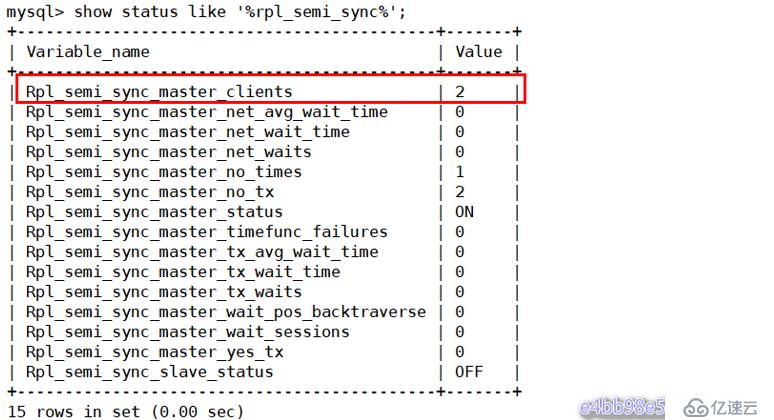
MHA包括manager節點和data節點,data節點包括原有的MySQL復制結構中的主機,至少3臺,即1主2從,當masterfailover后,還能保證主從結構;只需安裝node包。
- manager server:運行監控腳本,負責monitoring
- auto-failover:需要安裝node包和manager包
# yum -y install perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Config-IniFiles ncftp perl-Params-Validate perl-CPAN perl-Test-Mock-LWP.noarch perl-LWP-Authen-Negotiate.noarch perl-devel perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker更改當前cpan源,在案例中可能遇到沒有安裝的依賴庫,使用國內源安裝時快
[root@manager ~]# cpan 刪除之前的源:
cpan[1]> o conf urllist
cpan[2]> o conf urllist pop http://mirrors.nxthost.com/CPAN/
cpan[3]> o conf urllist pop http://mirrors.nic.cz/CPAN/
cpan[4]> o conf urllist pop http://cpan.panu.it/
cpan[5]> o conf urllist
添加國內源:
cpan[6]> o conf urllist push http://mirrors.aliyun.com/CPAN/
cpan[7]> o conf urllist push http://mirrors.163.com/cpan/
cpan[8]> o conf urllist 
提交保存退出
cpan[10]> o conf commit
cpan[11]> o conf urllist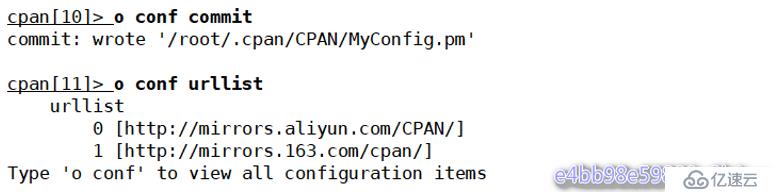
cpan[12]> exit軟件下載 https://github.com/yoshinorim
在所有數據庫節點上安裝mha4mysql-node-0.58.tar.gz(在管理節點需要node和manager都要安裝都安裝)
# wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58.tar.gzls
# tar zxf mha4mysql-node-0.58.tar.gz
# cd mha4mysql-node-0.58/
# perl Makefile.PL
*** Module::AutoInstall version 1.06
*** Checking for Perl dependencies...
[Core Features]
- DBI ...loaded. (1.627)
- DBD::mysql ...loaded. (4.023)
*** Module::AutoInstall configuration finished.
Checking if your kit is complete...
Looks good
Writing Makefile for mha4mysql::node
# make && make install在manager安裝mha4mysql-manager-0.58.tar.gz(node使用上面的方法安裝)
[root@manager ~]# cd /usr/local/src/
[root@manager src]# wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58.tar.gz
[root@manager src]# tar zxf mha4mysql-manager-0.58.tar.gz
[root@manager src]# cd mha4mysql-manager-0.58/
[root@manager mha4mysql-manager-0.58]# perl Makefile.PL
[root@manager mha4mysql-manager-0.58]# perl Makefile.PL
*** Module::AutoInstall version 1.06
*** Checking for Perl dependencies...
[Core Features]
- DBI ...loaded. (1.627)
- DBD::mysql ...loaded. (4.023)
- Time::HiRes ...loaded. (1.9725)
- Config::Tiny ...loaded. (2.14)
- Log::Dispatch ...loaded. (2.41)
- Parallel::ForkManager ...loaded. (1.18)
- MHA::NodeConst ...missing.
==> Auto-install the 1 mandatory module(s) from CPAN? [y] y
*** Dependencies will be installed the next time you type 'make'.
*** Module::AutoInstall configuration finished.
Checking if your kit is complete...
Looks good
Warning: prerequisite MHA::NodeConst 0 not found.
Writing Makefile for mha4mysql::manager
[root@manager mha4mysql-manager-0.58]# make && make install創建關于服務的相關目錄,復制腳本,配置文件(存放命令、配置文件、腳本…)
[root@manager mha4mysql-manager-0.58]# mkdir /etc/masterha
[root@manager mha4mysql-manager-0.58]# mkdir -p /masterha/app1
[root@manager mha4mysql-manager-0.58]# mkdir /scripts
[root@manager mha4mysql-manager-0.58]# cp samples/conf/* /etc/masterha/
[root@manager mha4mysql-manager-0.58]# cp samples/scripts/* /scripts/與絕大多數Linux應用程序類似,MHA的正確使用依賴于合理的配置文件。MHA的配置文件與mysql的my.cnf文件配置相似,采取的是param=value的方式來配置,配置文件位于管理節點,通常包括每一個mysql server的主機名,mysql用戶名,密碼,工作目錄等等。
編輯/etc/masterha/app1.conf,內容如下:
[root@manager mha4mysql-manager-0.58]# vim /etc/masterha/app1.cnf
[server default]
manager_workdir=/masterha/app1 //設置manager的工作目錄
manager_log=/masterha/app1/manager.log //設置manager的日志 user=manager
user=manager //設置監控用戶manager
password=123.com //監控用戶manager的密碼
ssh_user=root //ssh連接用戶
repl_user=mharep //主從復制用戶
repl_password=123.com //主從復制用戶密碼
ping_interval=1 //設置監控主庫,發送ping包的時間間隔,默認是3秒,嘗試三次沒有回應的時候自動進行railover
[server1]
hostname=192.168.1.1
port=3306
master_binlog_dir=/usr/local/mysql/data //設置master 保存binlog的位置,以便MHA可以找到master的日志,這里的也就是mysql的數據目錄
candidate_master=1 //設置為候選master,如果設置該參數以后,發生主從切換以后將會將此從庫提升為主庫
[server2]
hostname=192.168.1.8
port=3306
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
[server3]
hostname=192.168.1.9
port=3306
master_binlog_dir=/usr/local/mysql/data
no_master=1
[root@manager mha4mysql-manager-0.58]# >/etc/masterha/masterha_default.cnf //清空文件內容
SSH 有效性驗證:
[root@manager mha4mysql-manager-0.58]# masterha_check_ssh --global_conf=/etc/masterha/masterha_default.cnf --conf=/etc/masterha/app1.cnf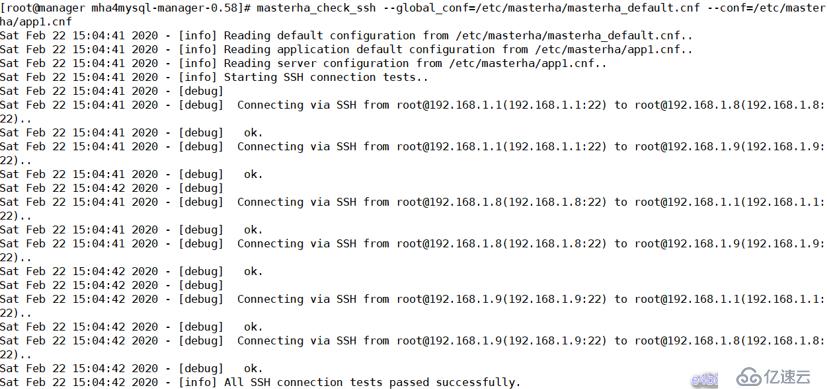
集群復制的有效性驗證: mysql必須都啟動
[root@manager mha4mysql-manager-0.58]# masterha_check_repl --global_conf=/etc/masterha/masterha_default.cnf --conf=/etc/masterha/app1.cnf
Sat Feb 22 15:05:26 2020 - [info] Reading default configuration from /etc/masterha/masterha_default.cnf..
Sat Feb 22 15:05:26 2020 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Sat Feb 22 15:05:26 2020 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Sat Feb 22 15:05:26 2020 - [info] MHA::MasterMonitor version 0.58.
Sat Feb 22 15:05:27 2020 - [info] GTID failover mode = 0
Sat Feb 22 15:05:27 2020 - [info] Dead Servers:
Sat Feb 22 15:05:27 2020 - [info] Alive Servers:
Sat Feb 22 15:05:27 2020 - [info] 192.168.1.1(192.168.1.1:3306)
Sat Feb 22 15:05:27 2020 - [info] 192.168.1.8(192.168.1.8:3306)
Sat Feb 22 15:05:27 2020 - [info] 192.168.1.9(192.168.1.9:3306)
Sat Feb 22 15:05:27 2020 - [info] Alive Slaves:
Sat Feb 22 15:05:27 2020 - [info] 192.168.1.8(192.168.1.8:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabled
Sat Feb 22 15:05:27 2020 - [info] Replicating from 192.168.1.1(192.168.1.1:3306)
Sat Feb 22 15:05:27 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Sat Feb 22 15:05:27 2020 - [info] 192.168.1.9(192.168.1.9:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabled
Sat Feb 22 15:05:27 2020 - [info] Replicating from 192.168.1.1(192.168.1.1:3306)
Sat Feb 22 15:05:27 2020 - [info] Not candidate for the new Master (no_master is set)
Sat Feb 22 15:05:27 2020 - [info] Current Alive Master: 192.168.1.1(192.168.1.1:3306)
Sat Feb 22 15:05:27 2020 - [info] Checking slave configurations..
Sat Feb 22 15:05:27 2020 - [info] read_only=1 is not set on slave 192.168.1.8(192.168.1.8:3306).
Sat Feb 22 15:05:27 2020 - [warning] relay_log_purge=0 is not set on slave 192.168.1.9(192.168.1.9:3306).
Sat Feb 22 15:05:27 2020 - [info] Checking replication filtering settings..
Sat Feb 22 15:05:27 2020 - [info] binlog_do_db= , binlog_ignore_db=
Sat Feb 22 15:05:27 2020 - [info] Replication filtering check ok.
Sat Feb 22 15:05:27 2020 - [info] GTID (with auto-pos) is not supported
Sat Feb 22 15:05:27 2020 - [info] Starting SSH connection tests..
Sat Feb 22 15:05:29 2020 - [info] All SSH connection tests passed successfully.
Sat Feb 22 15:05:29 2020 - [info] Checking MHA Node version..
Sat Feb 22 15:05:29 2020 - [info] Version check ok.
Sat Feb 22 15:05:29 2020 - [info] Checking SSH publickey authentication settings on the current master..
Sat Feb 22 15:05:29 2020 - [info] HealthCheck: SSH to 192.168.1.1 is reachable.
Sat Feb 22 15:05:29 2020 - [info] Master MHA Node version is 0.58.
Sat Feb 22 15:05:29 2020 - [info] Checking recovery script configurations on 192.168.1.1(192.168.1.1:3306)..
Sat Feb 22 15:05:29 2020 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/usr/local/mysql/data --output_file=/var/tmp/save_binary_logs_test --manager_version=0.58 --start_file=mysql-bin.000001
Sat Feb 22 15:05:29 2020 - [info] Connecting to root@192.168.1.1(192.168.1.1:22)..
Creating /var/tmp if not exists.. ok.
Checking output directory is accessible or not..
ok.
Binlog found at /usr/local/mysql/data, up to mysql-bin.000001
Sat Feb 22 15:05:29 2020 - [info] Binlog setting check done.
Sat Feb 22 15:05:29 2020 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers..
Sat Feb 22 15:05:29 2020 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='manager' --slave_host=192.168.1.8 --slave_ip=192.168.1.8 --slave_port=3306 --workdir=/var/tmp --target_version=5.7.28-log --manager_version=0.58 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx
Sat Feb 22 15:05:29 2020 - [info] Connecting to root@192.168.1.8(192.168.1.8:22)..
Checking slave recovery environment settings..
Opening /usr/local/mysql/data/relay-log.info ... ok.
Relay log found at /usr/local/mysql/data, up to relay-bin.000002
Temporary relay log file is /usr/local/mysql/data/relay-bin.000002
Checking if super_read_only is defined and turned on.. not present or turned off, ignoring.
Testing mysql connection and privileges..
mysql: [Warning] Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Sat Feb 22 15:05:29 2020 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='manager' --slave_host=192.168.1.9 --slave_ip=192.168.1.9 --slave_port=3306 --workdir=/var/tmp --target_version=5.7.28-log --manager_version=0.58 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx
Sat Feb 22 15:05:29 2020 - [info] Connecting to root@192.168.1.9(192.168.1.9:22)..
Checking slave recovery environment settings..
Opening /usr/local/mysql/data/relay-log.info ... ok.
Relay log found at /usr/local/mysql/data, up to relay-bin.000002
Temporary relay log file is /usr/local/mysql/data/relay-bin.000002
Checking if super_read_only is defined and turned on.. not present or turned off, ignoring.
Testing mysql connection and privileges..
mysql: [Warning] Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Sat Feb 22 15:05:30 2020 - [info] Slaves settings check done.
Sat Feb 22 15:05:30 2020 - [info]
192.168.1.1(192.168.1.1:3306) (current master)
+--192.168.1.8(192.168.1.8:3306)
+--192.168.1.9(192.168.1.9:3306)
Sat Feb 22 15:05:30 2020 - [info] Checking replication health on 192.168.1.8..
Sat Feb 22 15:05:30 2020 - [info] ok.
Sat Feb 22 15:05:30 2020 - [info] Checking replication health on 192.168.1.9..
Sat Feb 22 15:05:30 2020 - [info] ok.
Sat Feb 22 15:05:30 2020 - [warning] master_ip_failover_script is not defined.
Sat Feb 22 15:05:30 2020 - [warning] shutdown_script is not defined.
Sat Feb 22 15:05:30 2020 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.驗證成功的話會自動識別出所有服務器和主從狀況
PS:驗證成功的話會自動識別出所有服務器和主從狀況 在驗證時,若遇到這個錯誤:Can't exec "mysqlbinlog" ...... 解決方法是在所有服務器上執行:
*ln -s /usr/local/mysql/bin/ /usr/local/bin/**
啟動 manager
[root@manager ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/tmp/mha_manager.log &
[1] 12451PS:在應用Unix/Linux時,一般想讓某個程序在后臺運行,常會用 & 在程序結尾來讓程序自動運行。比如要運行mysql在后臺: /usr/local/mysql/bin/mysqld_safe –user=mysql &。可是有很多程序并不像mysqld一樣,這樣就需要nohup(后臺運行的進程,并不會隨著shell環境的關閉而殺死進程)命令
狀態檢查:
[root@manager ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:12451) is running(0:PING_OK), master:192.168.1.1(自動failover) master dead后,MHA當時已經開啟,候選Master庫(Slave)會自動failover為Master.
驗證方式:
先停掉 master1,因為之前的配置文件中,把master2作為了候選人,那么就到 slave1上查看 master 的 IP 是否變為了 master2的IP
[root@master1 mha4mysql-node-0.58]# systemctl stop mysqld[root@manager ~]# cat /masterha/app1/manager.log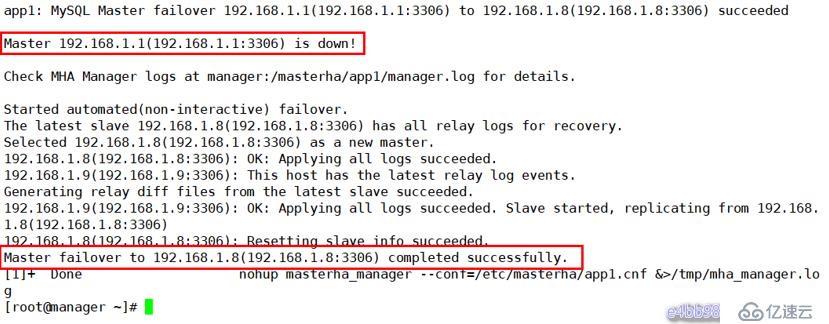
從日志信息中可以看到 master failover 已經成功了,并可以看出故障轉移的大體流程
登錄 slave1的Mysql,查看 slave 狀態
[root@slave1 mha4mysql-node-0.58]# mysql -uroot -p123.com
mysql> show slave status\G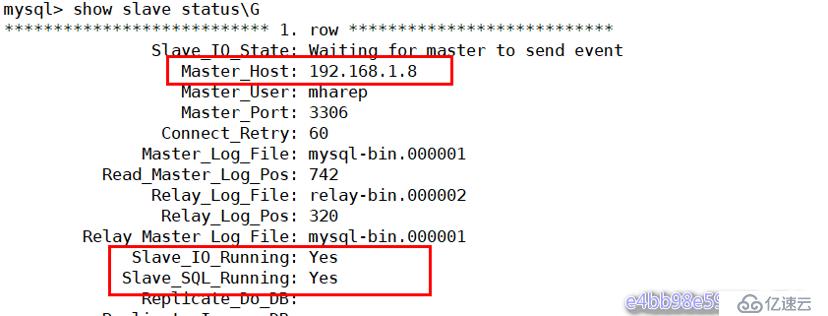
可以看到 master 的 IP 現在為 192.168.1.8, 已經切換到和192.168.1.8同步了,本來是和192.168.1.1同步的,說明 MHA 已經把master2提升為了新的 master,IO線程和SQL線程也正確運行,MHA搭建成功
發生主從切換后,MHAmanager服務會自動停掉,且在manager_workdir(/masterha/app1)目錄下面生成文件app1.failover.complete(若要啟動MHA,必須先確保無此文件) 如果有這個提示,那么刪除此文件
/ masterha/app1/app1.failover.complete [error]
[/usr/share/perl5/vendor_perl/MHA/MasterFailover.pm, ln298] Last failover was done at 2015/01/09 10:00:47.
Current time is too early to do failover again. If you want to do failover, manually remove /
masterha/app1/app1.failover.complete and run this script again.mysql> show master status;
[root@master1 ~]# systemctl start mysqld
[root@master1 ~]# mysql -uroot -p123.com
mysql> change master to master_host='192.168.1.8',master_port=3306,master_log_file='mysql-bin.000001',master_log_pos=742,master_user='mharep',master_password='123.com';
mysql> start slave;在manager檢查集群狀態:
[root@manager ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf 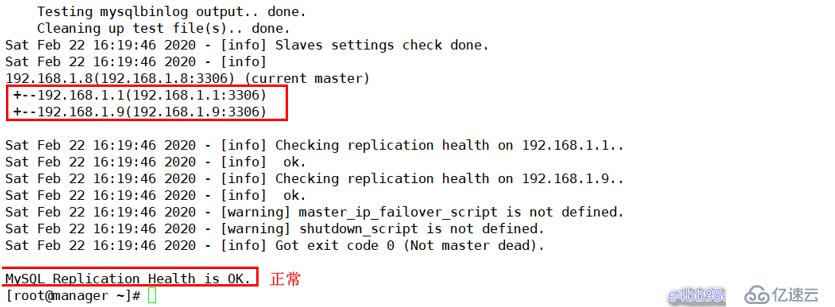
[root@manager ~]# masterha_stop --conf/etc/masterha/app1.cnf[root@manager ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/tmp/mha_manager.log &當有slave 節點宕掉時,默認是啟動不了的,加上 --ignore_fail_on_start 即使有節點宕掉也能啟動MHA,如下:
[root@manager ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_fail_on_start&>/tmp/mha_manager.log &[root@manager ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:13739) is running(0:PING_OK), master:192.168.1.8PS:如果正常,會顯示"PING_OK",否則會顯示"NOT_RUNNING",這代表MHA監控沒有開啟。
[root@manager ~]# tail -f /masterha/app1/manager.log重構:重構就是主服務器宕機了,切換到備主上,備主變成了主。
因此重構的一種方案:
原主庫修復成一個新的slave,主庫切換后,把原主庫修復成新從庫。然后重新執行以上5步。
原主庫數據文件完整的情況下,可通過以下方式找出最后執行的CHANGE MASTER命令:
[root@manager ~]# grep "CHANGE MASTER TO MASTER" /masterha/app1/manager.log | tail -1
Sat Feb 22 15:25:21 2020 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.1.8', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=742, MASTER_USER='mharep', MASTER_PASSWORD='xxx';定期刪除中繼日志 在配置主從復制中,slave上設置了參數relay_log_purge=0,所以slave節點需要定期刪除中繼日志,建議每個slave節點刪除中繼日志的時間錯開。
# crontab -e
0 5 * * * /usr/local/bin/purge_relay_logs - -user=root --password=123.com --port=3306 --disable_relay_log_purge >> /var/log/purge_relay.log 2>&1免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





