溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
PV是page view的縮寫,即頁面瀏覽量,通常是衡量一個網絡新聞頻道或網站甚至一條網絡新聞的主要指標。網頁瀏覽數是評價網站流量最常用的指標之一,簡稱為PV
UV是unique visitor的簡寫,是指通過互聯網訪問、瀏覽這個網頁的自然人。
通過以上的概念,可以清晰的看出pv是比較好設計的,網站的每一次被訪問,pv都會增加,但是uv就不一定會增加了,uv本質上記錄的是按照某個標準劃分的自然人,這個標準其實我們可以自己去定義,比如:可以定義同一個IP的訪問者為同一個UV,這也是最常見的uv定義之一,另外還有根據cookie定義等等。無論是pv還是uv,都需要一個時間段來加以描述,平時我們所說的pv,uv數量指的都是24小時之內(一個自然日)的數據。
pv相比較uv來說,技術上比較容易一些,今天咱們就來說一說uv的統計,為什么說uv的統計相對來說比較難呢,因為uv涉及到同一個標準下的自然人的去重,尤其是一個uv千萬級別的網站,設計一個好的uv統計系統也許并非想象的那么容易。
那我們就來設計一個以一個自然日為時間段的uv統計系統,一個自然人(uv)的定義為同一個來源IP(當然你也可以自定義其他標準),數據量級別假設為每日千萬uv的量級。
注意:今天我們討論的重點是獲取到自然人定義的信息之后如何設計uv統計系統,并非是如何獲取自然人的定義。uv系統的設計并非想象的那么簡單,因為uv可能隨著網站的營銷策略會出現瞬間大流量,比如網站舉辦了一個秒殺活動。
服務端編程有一句名言曰:沒有一個表解決不了的功能,如果有那就兩個表三個表。一個uv統計系統確實可以基于數據庫來實現,而且也不復雜,uv統計的記錄表可以類似如下(不要太糾結以下表設計是否合理):
| 字段 | 類型 | 描述 |
|---|---|---|
| IP | varchar(30) | 客戶端來源ip |
| DayID | int | 時間的簡寫,例如 20190629 |
| 其他字段 | int | 其他字段描述 |
當一個請求到達服務器,服務端每次需要查詢一次數據庫是否有當前IP和當前時間的訪問記錄,如果有,則說明是同一個uv,如果沒有,則說明是新的uv記錄,插入數據庫。當然以上兩步也可以寫到一個sql語句中:
if exists( select 1 from table where ip='ip' and dayid=dayid )
Begin
return 0
End
else
Begin
insert into table .......
End所有基于數據庫的解決方案,在數據量大的情況下幾乎都更容易出現瓶頸。面對每天千萬級別的uv統計,基于數據庫的這種方案也許并不是最優的。
面對每一個系統的設計,我們都應該沉下心來思考具體的業務。至于uv統計這個業務有幾個特點:
每次請求都需要判斷是否已經存在相同的uv記錄
持久化uv數據不能影響正常的業務
基于數據庫的方案中,在大數據量的情況下,性能的瓶頸引發原因之一就是:判斷是否已經存在相同記錄,所以要優化這個系統,肯定首先是要優化這個步驟。根據菜菜以前的文章,是否可以想到解決這個問題的數據結構,對,就是哈希表。哈希表根據key來查找value的時間復雜度為O(1)常數級別,可以完美的解決查找相同記錄的操作瓶頸。
也許在uv數據量比較小的時候,哈希表也許是個不錯的選擇,但是面對千萬級別的uv數據量,哈希表的哈希沖突和擴容,以及哈希表占用的內存也許并不是好的選擇了。假設哈希表的每個key和value 占用10字節,1千萬的uv數據大約占用 100M,對于現代計算機來說,100M其實不算大,但是有沒有更好的方案呢?
基于哈希表的方案,在千萬級別數據量的情況下,只能算是勉強應付,如果是10億的數據量呢?那有沒有更好的辦法搞定10億級數據量的uv統計呢?這里拋開持久化數據,因為持久化設計到數據庫的分表分庫等優化策略了,咱們以后再談。有沒有更好的辦法去快速判斷在10億級別的uv中某條記錄是否存在呢?
為了盡量縮小使用的內存,我們可以這樣設計,可以預先分配bit類型的數組,數組的大小是統計的最大數據量的一個倍數,這個倍數可以自定義調整。現在假設系統的uv最大數據量為1千萬,系統可以預先分配一個長度為5千萬的bit數組,bit占用的內存最小,只占用一位。按照一個哈希沖突比較小的哈希函數計算每一個數據的哈希值,并設置bit數組相應哈希值位置的值為1。由于哈希函數都有沖突,有可能不同的數據會出現相同的哈希值,出現誤判,但是我們可以用多個不同的哈希函數來計算同一個數據,來產生不同的哈希值,同時把這多個哈希值的數組位置都設置為1,從而大大減少了誤判率,剛才新建的數組為最大數據量的一個倍數也是為了減小沖突的一種方式(容量越大,沖突越小)。當一個1千萬的uv數據量級,5千萬的bit數組占用內存才幾十M而已,比哈希表要小很多,在10億級別下內存占用差距將會更大。
以下為代碼示例:
class BloomFilter
{
BitArray container = null;
public BloomFilter(int length)
{
container = new BitArray(length);
}
public void Set(string key)
{
var h2 = Hash2(key);
var h3 = Hash3(key);
var h4 = Hash4(key);
var h5 = Hash5(key);
container[h2] = true;
container[h3] = true;
container[h4] = true;
container[h5] = true;
}
public bool Get(string key)
{
var h2 = Hash2(key);
var h3 = Hash3(key);
var h4 = Hash4(key);
var h5 = Hash5(key);
return container[h2] && container[h3] && container[h4] && container[h5];
}
//模擬哈希函數1
int Hash2(string key)
{
int hash = 5381;
int i;
int count;
char[] bitarray = key.ToCharArray();
count = bitarray.Length;
while (count > 0)
{
hash += (hash << 5) + (bitarray[bitarray.Length - count]);
count--;
}
return (hash & 0x7FFFFFFF) % container.Length;
}
int Hash3(string key)
{
int seed = 131; // 31 131 1313 13131 131313 etc..
int hash = 0;
int count;
char[] bitarray = (key+"key2").ToCharArray();
count = bitarray.Length;
while (count > 0)
{
hash = hash * seed + (bitarray[bitarray.Length - count]);
count--;
}
return (hash & 0x7FFFFFFF)% container.Length;
}
int Hash4(string key)
{
int hash = 0;
int i;
int count;
char[] bitarray = (key + "keykey3").ToCharArray();
count = bitarray.Length;
for (i = 0; i < count; i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ (bitarray[i]) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (bitarray[i]) ^ (hash >> 5)));
}
count--;
}
return (hash & 0x7FFFFFFF) % container.Length;
}
int Hash5(string key)
{
int hash = 5381;
int i;
int count;
char[] bitarray = (key + "keykeyke4").ToCharArray();
count = bitarray.Length;
while (count > 0)
{
hash += (hash << 5) + (bitarray[bitarray.Length - count]);
count--;
}
return (hash & 0x7FFFFFFF) % container.Length;
}
}測試程序為:
BloomFilter bf = new BloomFilter(200000000);
int exsitNumber = 0;
int noExsitNumber = 0;
for (int i=0;i < 10000000; i++)
{
string key = $"ip_{i}";
var isExsit= bf.Get(key);
if (isExsit)
{
exsitNumber += 1;
}
else
{
bf.Set(key);
noExsitNumber += 1;
}
}
Console.WriteLine($"判斷存在的數據量:{exsitNumber}");
Console.WriteLine($"判斷不存在的數據量:{noExsitNumber}");測試結果:
判斷存在的數據量:7017
判斷不存在的數據量:×××983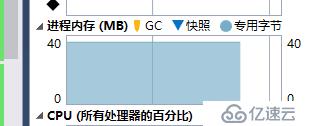
占用內存40M,誤判率不到 千分之1,在這個業務場景下在可接受范圍之內。在真正的業務當中,系統并不會在啟動之初就分配這么大的bit數組,而是隨著沖突增多慢慢擴容到一定容量的。
當判斷一個數據是否已經存在這個過程解決之后,下一個步驟就是把數據持久化到DB,如果數據量較大或者瞬間數據量較大,可以考慮使用mq或者讀寫IO比較大的NOSql來代替直接插入關系型數據庫。
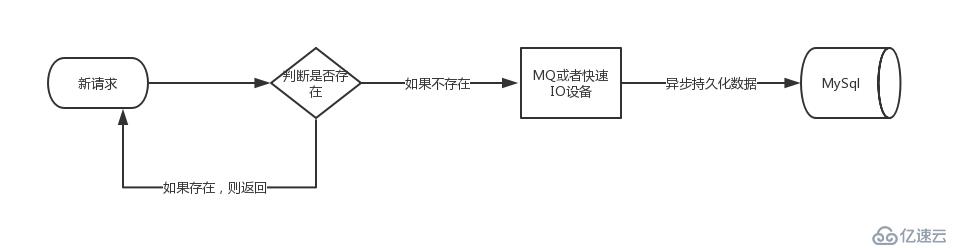
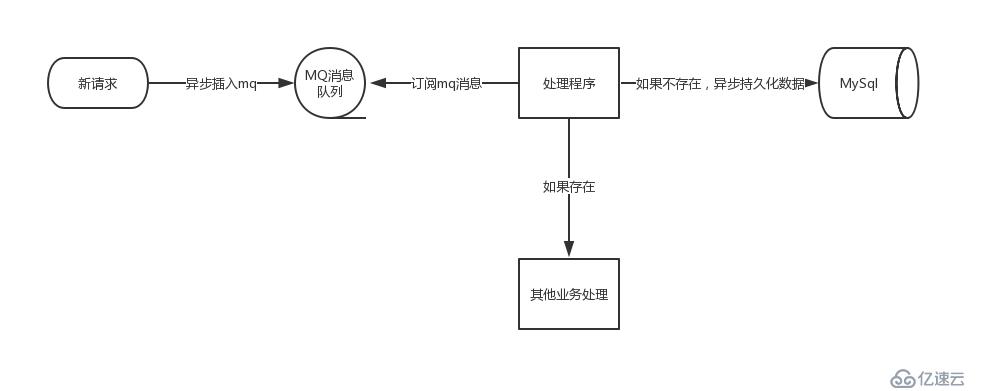
思路一轉,整個的uv流程其實也都可以異步化,而且也推薦這么做。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





