溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
? Async I/O 是阿里巴巴貢獻給社區的一個呼聲非常高的特性,于1.2版本引入。主要目的是為了解決數據流與外部系統交互時的通信延遲(比如等待外部系統的響應)成為了系統瓶頸的問題。對于實時處理,當需要使用外部存儲數據的時候,需要小心對待,不能讓與外部系統之間的交互延遲對流處理的整個工作進度起決定性的影響。
? 例如,在mapfunction等算子里訪問外部存儲,實際上該交互過程是同步的:比如請求a發送到數據庫,那么mapfunction會一直等待響應。在很多案例中,這個等待過程是非常浪費函數時間的。與數據庫異步交互,意味著單個函數實例可以并發處理很多請求,同時并發接收響應。那么,等待的時候由于也會發送其它請求和接收其它響應,被重復使用而節省了時間。至少,等待時間在多個請求上被攤銷。這就使得很多使用案例具有更高的吞吐量。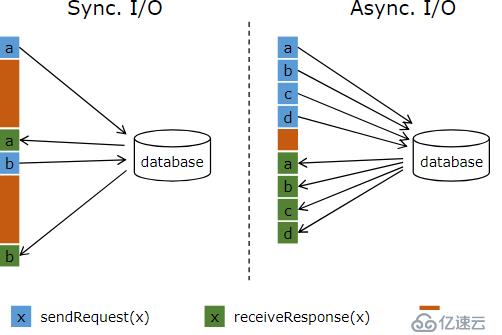
? 圖1.1 flink--異步IO
注意:通過增加MapFunction的到一個較大的并行度也是可以改善吞吐量的,但是這就意味著更高的資源開銷:更多的MapFunction實例意味著更多的task,線程,flink內部網絡連接,數據庫的鏈接,緩存,更多內部狀態開銷。
使用flink的異步IO時,需要所連接的數據庫支持異步客戶端。幸運的是很多流行的數據庫支持這樣的客戶端。假如沒有異步客戶端,也可以創建多個同步客戶端,放到線程池里,使用線程池來完成異步功能。當然,該種方式相對于異步客戶端更低效。
? flink異步IO的API支持用戶在data stream中使用異步請求客戶端。API自身處理與數據流的整合,消息順序,時間時間,容錯等。
假如有目標數據庫的異步客戶端,使用異步IO,需要實現一下三步:
1、實現AsyncFunction或者RichAsyncFunction,該函數實現了請求異步分發的功能。
2、一個callback回調,該函數取回操作的結果,然后傳遞給ResultFuture。
3、對DataStream使用異步IO操作。
可以看看AsyncFunction這個接口的源碼
public interface AsyncFunction<IN, OUT> extends Function, Serializable {
void asyncInvoke(IN var1, ResultFuture<OUT> var2) throws Exception;
default void timeout(IN input, ResultFuture<OUT> resultFuture) throws Exception {
resultFuture.completeExceptionally(new TimeoutException("Async function call has timed out."));
}
}主要需要實現兩個方法:
void asyncInvoke(IN var1, ResultFuture<OUT> var2):
這是真正實現外部操作邏輯的方法,var1是輸入的參數,var2則是返回結果的集合
default void timeout(IN input, ResultFuture<OUT> resultFuture)
這是當異步請求超時的時候,會調用這個方法。參數的用途和上面一樣而RichAsyncFunction由于繼承了RichAsyncFunction類,所以還提供了open和close這兩個方法,一般我們的用法是,open方法中創建連接外部存儲的client連接(比如連接mysql的jdbc連接),close 用于關閉client連接,至于asyncInvoke和timeout兩個方法的用法和上面一樣,這里不重復。一般我們常用的是RichAsyncFunction。
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
/** The database specific client that can issue concurrent requests with callbacks */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// issue the asynchronous request, receive a future for result
final Future<String> result = client.query(key);
// set the callback to be executed once the request by the client is complete
// the callback simply forwards the result to the result future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// Normally handled explicitly.
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// create the original stream
DataStream<String> stream = ...;
// 將異步IO類應用于數據流
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);要注意的是,最后需要將查詢到的數據放入 resultFuture 中,即通過resultFuture.complete來將結果傳遞給框架。第一次調用 ResultFuture.complete的時候 ResultFuture就會完成。所有后續的complete調用都會被忽略。
參數有4個,in、asyncObject、timeout、timeUnit、capacity
in:輸入的數據流
asyncObject:異步IO操作類對象
timeout:
異步IO請求被視為失敗的超時時間,超過該時間異步請求就算失敗。該參數主要是為了剔除死掉或者失敗的請求。
timeUnit:時間的單位,例如TimeUnit.MICROSECONDS,表示毫秒
capacity:
該參數定義了同時最多有多少個異步請求在處理。即使異步IO的方式會導致更高的吞吐量,但是對于實時應用來說該操作也是一個瓶頸。限制并發請求數,算子不會積壓過多的未處理請求,但是一旦超過容量的顯示會觸發背壓。當一個異步IO請求多次超時,默認情況下會拋出一個異常,然后重啟job。如果想處理超時,可以覆蓋AsyncFunction.timeout方法。
AsyncFunction發起的并發請求完成的順序是不可預期的。為了控制結果發送的順序,flink提供了兩種模式:
1). Unordered
結果記錄在異步請求結束后立刻發送。流中的數據在經過該異步IO操作后順序就和以前不一樣了,也就是請求的順序和請求結果的順序的不能保證一致。當使用處理時間作為基礎時間特性的時候,該方式具有極低的延遲和極低的負載。調用方式AsyncDataStream.unorderedWait(...)
2). Ordered
該種方式流的順序會被保留。結果記錄發送的順序和異步請求被觸發的順序一樣,該順序就是原來流中事件的順序。為了實現該目標,操作算子會在該結果記錄之前的記錄為發送之前緩存該記錄。這往往會引入額外的延遲和一些Checkpoint負載,因為相比于無序模式結果記錄會保存在Checkpoint狀態內部較長的時間。調用方式AsyncDataStream.orderedWait(...)
當使用事件時間的時候,異步IO操作也會正確的處理watermark機制。這就意味著兩種order模式的具體操作如下:
1). Unordered
watermark不會超過記錄,意味著watermark建立了一個order邊界。記錄僅會在兩個watermark之間無序發射。當前watermark之后的記錄僅會在當前watermark發送之后發送。watermark也僅會在該watermark之前的所有記錄發射完成之后發送。這就意味著在存在watermark的情況下,無序模式引入了一些與有序模式相同的延遲和管理開銷。開銷的大小取決于watermark的頻率。也就是watermark之間是有序的,但是同一個watermark內部的請求是無序的
2). Ordered
watermark的順序就如記錄的順序一樣被保存。與處理時間相比,開銷沒有顯著變化。請記住,注入時間 Ingestion Time是基于源處理時間自動生成的watermark事件時間的特殊情況。
異步IO操作提供了僅一次處理的容錯擔保。它會將在傳出的異步IO請求保存于Checkpoint,然后故障恢復的時候從Checkpoint中恢復這些請求。
1、maven的pom依賴
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>SparkDemo</groupId>
<artifactId>SparkDemoTest</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.1.0</spark.version>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.7.3</hadoop.version>
<scala.binary.version>2.11</scala.binary.version>
<flink.version>1.6.1</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.9.0</version>
</dependency>
<!--因為spark和es默認依賴的netty版本不一致,前者使用3.x版本,后者使用4.1.32版本
所以導致es使用的是3.x版本,有些方法不兼容,這里直接使用使用新版本,否則報錯-->
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.32.Final</version>
</dependency>
<!--flink-->
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.1</version>
<!--<scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.11</artifactId>
<version>1.6.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.22</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--mysql異步客戶端-->
<!-- https://mvnrepository.com/artifact/io.vertx/vertx-core -->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>3.7.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-jdbc-client</artifactId>
<version>3.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.vertx/vertx-web -->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web</artifactId>
<version>3.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.2</version>
</dependency>
</dependencies>
<!--下面這是maven打包scala的插件,一定要,否則直接忽略scala代碼-->
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>2、源代碼
目標mysql表的格式為:
id name
1 king
2 tao
3 ming
需要根據name查詢到id代碼:
package flinktest;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import io.vertx.core.Vertx;
import io.vertx.core.VertxOptions;
import io.vertx.core.json.JsonObject;
import io.vertx.ext.jdbc.JDBCClient;
import io.vertx.ext.sql.ResultSet;
import io.vertx.ext.sql.SQLClient;
import io.vertx.ext.sql.SQLConnection;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* flink 異步IO demo:使用異步IO和mysql交互
* 因為普通的jdbc客戶端不支持異步方式,所以這里引入vertx
* 的異步jdbc client(異步IO要求客戶端支持異步操作)
*
* 實現目標:根據數據源,使用異步IO從mysql查詢對應的數據, 然后打印出來
*/
public class AsyncToMysql {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
List<String> sourceList = new ArrayList<>();
//構建數據源查詢條件,后面用來作為sql查詢中where的查詢值
sourceList.add("king");
sourceList.add("tao");
DataStreamSource<String> source = env.fromCollection(sourceList);
//調用異步IO處理類
DataStream<JsonObject> result = AsyncDataStream.unorderedWait(
source,
new MysqlAsyncFunc(),
10, //這里超時時長如果在本地idea跑的話不要設置得太短,因為本地執行延遲比較大
TimeUnit.SECONDS,
20).setParallelism(1);
result.print();
try {
env.execute("TEST async");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 繼承 RichAsyncFunction類,編寫自定義的異步IO處理類
*/
private static class MysqlAsyncFunc extends RichAsyncFunction<String, JsonObject> {
private transient SQLClient mysqlClient;
private Cache<String, String> cache;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//構建mysql查詢緩存,這里使用Caffeine這個高性能緩存庫
cache = Caffeine
.newBuilder()
.maximumSize(1025)
.expireAfterAccess(10, TimeUnit.MINUTES) //設置緩存過期時間
.build();
//構建mysql jdbc連接
JsonObject mysqlClientConfig = new JsonObject();
//設置jdbc連接參數
mysqlClientConfig.put("url", "jdbc:mysql://192.168.50.121:3306/test?useSSL=false&serverTimezone=UTC&useUnicode=true")
.put("driver_class", "com.mysql.cj.jdbc.Driver")
.put("max_pool_size", 20)
.put("user", "root")
.put("password", "xxxxx");
//設置vertx的工作參數,比如線程池大小
VertxOptions vo = new VertxOptions();
vo.setEventLoopPoolSize(10);
vo.setWorkerPoolSize(20);
Vertx vertx = Vertx.vertx(vo);
mysqlClient = JDBCClient.createNonShared(vertx, mysqlClientConfig);
if (mysqlClient != null) {
System.out.println("連接mysql成功!!!");
}
}
//清理環境
@Override
public void close() throws Exception {
super.close();
//關閉mysql連接,清除緩存
if (mysqlClient != null) {
mysqlClient.close();
}
if (cache != null) {
cache.cleanUp();
}
}
@Override
public void asyncInvoke(String input, ResultFuture<JsonObject> resultFuture) throws Exception {
System.out.println("key is:" + input);
String key = input;
//先從緩存中查找,找到就直接返回
String cacheIfPresent = cache.getIfPresent(key);
JsonObject output = new JsonObject();
if (cacheIfPresent != null) {
output.put("name", key);
output.put("id-name", cacheIfPresent);
resultFuture.complete(Collections.singleton(output));
//return;
}
System.out.println("開始查詢");
mysqlClient.getConnection(conn -> {
if (conn.failed()) {
resultFuture.completeExceptionally(conn.cause());
//return;
}
final SQLConnection sqlConnection = conn.result();
//拼接查詢語句
String querySql = "select id,name from customer where name='" + key + "'";
System.out.println("執行的sql為:" + querySql);
//執行查詢,并獲取結果
sqlConnection.query(querySql, res -> {
if (res.failed()) {
resultFuture.completeExceptionally(null);
System.out.println("執行失敗");
//return;
}
if (res.succeeded()) {
System.out.println("執行成功,獲取結果");
ResultSet result = res.result();
List<JsonObject> rows = result.getRows();
System.out.println("結果個數:" + String.valueOf(rows.size()));
if (rows.size() <= 0) {
resultFuture.complete(null);
//return;
}
//結果返回,并更新到緩存中
for (JsonObject row : rows) {
String name = row.getString("name");
String id = row.getInteger("id").toString();
String desc = id + "-" + name;
System.out.println("結果:" + desc);
output.put("name", key);
output.put("id-name", desc);
cache.put(key, desc);
resultFuture.complete(Collections.singleton(output));
}
} else {
//執行失敗,返回空
resultFuture.complete(null);
}
});
//連接關閉
sqlConnection.close(done -> {
if (done.failed()) {
throw new RuntimeException(done.cause());
}
});
});
}
}
}
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





