溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我們先看一下HashSet和TreeSet在整個集合框架中的位置。他們都實現了Set接口。他們之間的區別是HashSet不能保證元素的順序,TreeSet中的元素可以按照某個順序排列。他們的元素都不能重復。
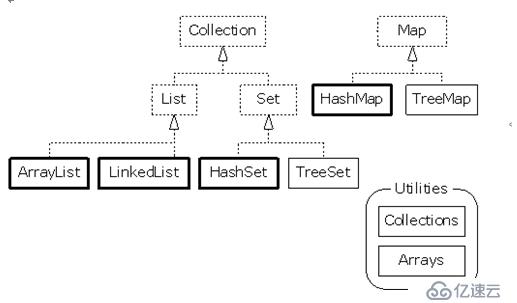
先來看一下HashSet:
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("張三");
set.add("李四");
set.add("王五");
System.out.println(set);
System.out.println(set.size());
System.out.println(set.contains("張三"));
}
打印輸出的順序是是: [李四, 張三, 王五]
可以看出和存進去的順序不一致。
我們先看一下 Set<String> set = new HashSet<String>();
這行代碼創建了一個HashSet,構造函數如下:
public HashSet() {
map = new HashMap<>();
}
可以看到實際上是創建了一個HashMap的對象。沒錯,HashSet底層就是一個HashMap.
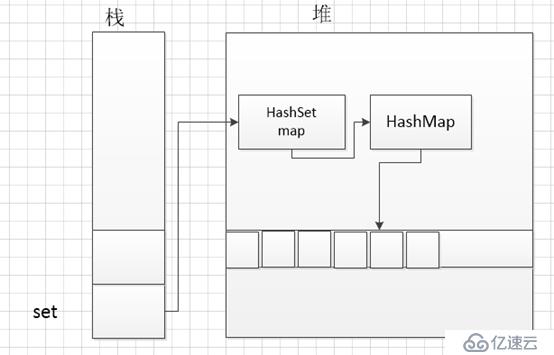
再來看一下這行代碼:set.add("張三");
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
非常的簡單,就是調用了一下HashMap的put方法對元素進行插入。
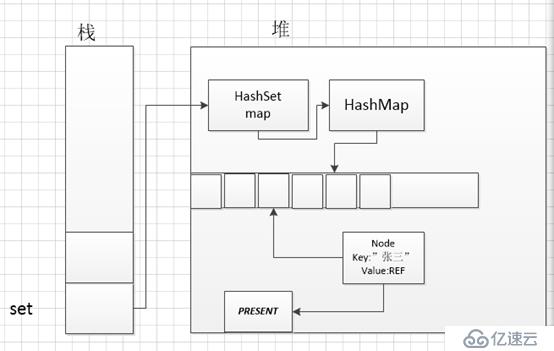
這里的PERSENT是什么呢?繼續順藤摸瓜:
private static final Object PRESENT = new Object();
原來就是一個普通的Object對象前面用static final修飾說明是不可變的。
繼續添加:set.add("李四");
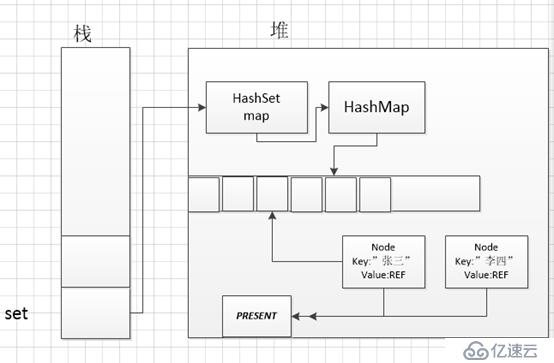
可以看出來HashMap的key分別為”張三”,”李四”,“王五”, 因為HashSet用不到value,他們的value都是一樣的指向同一個地方。繼續往下看:System.out.println(set.size());
public int size() {
return map.size();
}
也是調用的HashMap的size方法。
System.out.println(set.contains("張三"));
public boolean contains(Object o) {
return map.containsKey(o);
}
同樣調用的HashMap的contains方法。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





