溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我們都知道HashMap是線程不安全的,在多線程環境中不建議使用,但是其線程不安全主要體現在什么地方呢,本文將對該問題進行解密。
1.jdk1.7中的HashMap
在jdk1.8中對HashMap做了很多優化,這里先分析在jdk1.7中的問題,相信大家都知道在jdk1.7多線程環境下HashMap容易出現死循環,這里我們先用代碼來模擬出現死循環的情況:
public static void main(String[] args) {
HashMapThread thread0 = new HashMapThread();
HashMapThread thread1 = new HashMapThread();
HashMapThread thread2 = new HashMapThread();
HashMapThread thread3 = new HashMapThread();
HashMapThread thread4 = new HashMapThread();
thread0.start();
thread1.start();
thread2.start();
thread3.start();
thread4.start();
}
}
class HashMapThread extends Thread {
private static AtomicInteger ai = new AtomicInteger();
private static Map<integer, integer="" >map = new HashMap<>();
@Override
public void run() {
while (ai.get() < 1000000) {
map.put(ai.get(), ai.get());
ai.incrementAndGet();
}
}
}</integer,> 上述代碼比較簡單,就是開多個線程不斷進行put操作,并且HashMap與AtomicInteger都是全局共享的。
在多運行幾次該代碼后,出現如下死循環情形:
其中有幾次還會出現數組越界的情況:
這里我們著重分析為什么會出現死循環的情況,通過jps和jstack命名查看死循環情況,結果如下: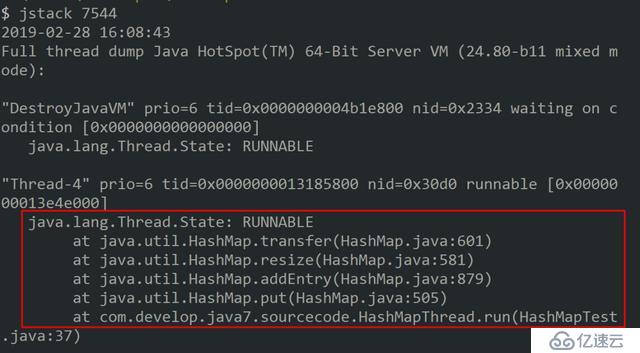
從堆棧信息中可以看到出現死循環的位置,通過該信息可明確知道死循環發生在HashMap的擴容函數中,根源在transfer函數中,jdk1.7中HashMap的transfer函數如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<k,v >e : table) {
while(null != e) {
Entry<k,v >next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}</k,v></k,v> 都說知道 HashMap 線程不安全,那它為啥就不安全?
Java領域佼佼者 2020-02-20 14:40
我們都知道HashMap是線程不安全的,在多線程環境中不建議使用,但是其線程不安全主要體現在什么地方呢,本文將對該問題進行解密。
1.jdk1.7中的HashMap
在jdk1.8中對HashMap做了很多優化,這里先分析在jdk1.7中的問題,相信大家都知道在jdk1.7多線程環境下HashMap容易出現死循環,這里我們先用代碼來模擬出現死循環的情況:
public static void main(String[] args) {
HashMapThread thread0 = new HashMapThread();
HashMapThread thread1 = new HashMapThread();
HashMapThread thread2 = new HashMapThread();
HashMapThread thread3 = new HashMapThread();
HashMapThread thread4 = new HashMapThread();
thread0.start();
thread1.start();
thread2.start();
thread3.start();
thread4.start();
}
}
class HashMapThread extends Thread {
private static AtomicInteger ai = new AtomicInteger();
private static Map<integer, integer="" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important;">map = new HashMap<>();
@Override
public void run() {
while (ai.get() < 1000000) {
map.put(ai.get(), ai.get());
ai.incrementAndGet();
}
}
}</integer,>
上述代碼比較簡單,就是開多個線程不斷進行put操作,并且HashMap與AtomicInteger都是全局共享的。
在多運行幾次該代碼后,出現如下死循環情形:
其中有幾次還會出現數組越界的情況:
這里我們著重分析為什么會出現死循環的情況,通過jps和jstack命名查看死循環情況,結果如下:
從堆棧信息中可以看到出現死循環的位置,通過該信息可明確知道死循環發生在HashMap的擴容函數中,根源在transfer函數中,jdk1.7中HashMap的transfer函數如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<k,v style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important;">e : table) {
while(null != e) {
Entry<k,v style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important;">next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}</k,v></k,v>
總結下該函數的主要作用:
在對table進行擴容到newTable后,需要將原來數據轉移到newTable中,注意10-12行代碼,這里可以看出在轉移元素的過程中,使用的是頭插法,也就是鏈表的順序會翻轉,這里也是形成死循環的關鍵點。
下面進行詳細分析。
1.1 擴容造成死循環分析過程
前提條件,這里假設:
hash算法為簡單的用key mod鏈表的大小。最開始hash表size=2,key=3,7,5,則都在table[1]中。然后進行resize,使size變成4。
未resize前的數據結構如下: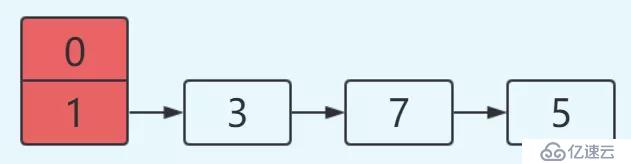
如果在單線程環境下,最后的結果如下: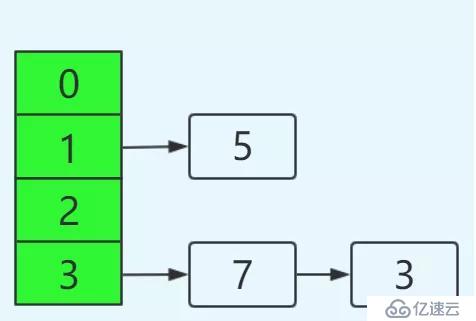
這里的轉移過程,不再進行詳述,只要理解transfer函數在做什么,其轉移過程以及如何對鏈表進行反轉應該不難。
然后在多線程環境下,假設有兩個線程A和B都在進行put操作。線程A在執行到transfer函數中第11行代碼處掛起,因為該函數在這里分析的地位非常重要,因此再次貼出來。
此時線程A中運行結果如下: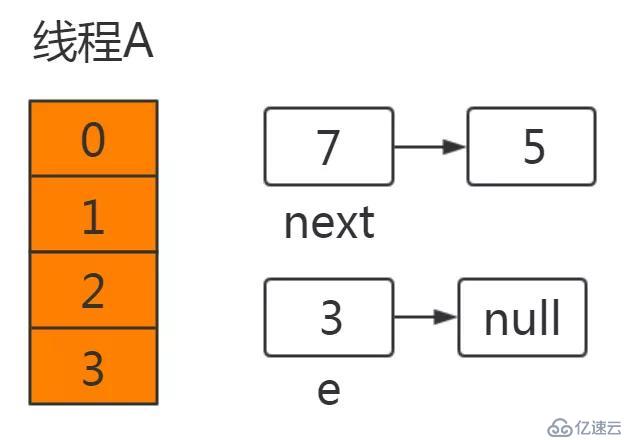
線程A掛起后,此時線程B正常執行,并完成resize操作,結果如下:
這里需要特別注意的點:由于線程B已經執行完畢,根據Java內存模型,現在newTable和table中的Entry都是主存中最新值:****7.next=3,3.next=null。
此時切換到線程A上,在線程A掛起時內存中值如下:e=3,next=7,newTable[3]=null,代碼執行過程如下:
newTable[3]=e ----> newTable[3]=3
e=next ----> e=7此時結果如下: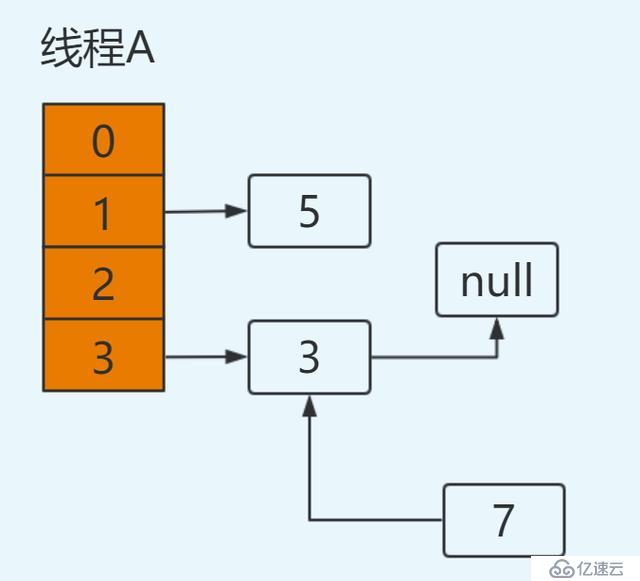
繼續循環:
e=7
next=e.next ----> next=3【從主存中取值】
e.next=newTable[3] ----> e.next=3【從主存中取值】
newTable[3]=e ----> newTable[3]=7
e=next ----> e=3結果如下: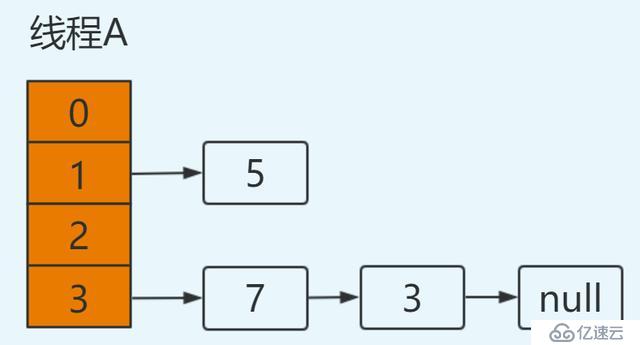
再次進行循環:
e=3
next=e.next ----> next=null
e.next=newTable[3] ----> e.next=7 即:3.next=7
newTable[3]=e ----> newTable[3]=3
e=next ----> e=null注意此次循環:e.next=7,而在上次循環中7.next=3,出現環形鏈表,并且此時e=null循環結束。
結果如下: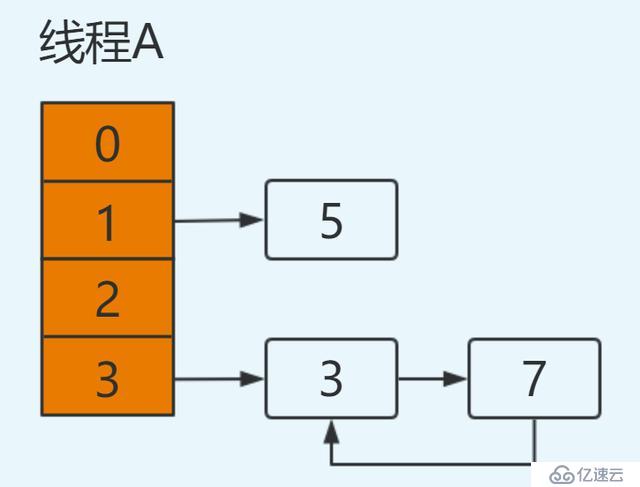
在后續操作中只要涉及輪詢hashmap的數據結構,就會在這里發生死循環,造成悲劇。
1.2 擴容造成數據丟失分析過程
遵照上述分析過程,初始時:
線程A和線程B進行put操作,同樣線程A掛起:
此時線程A的運行結果如下: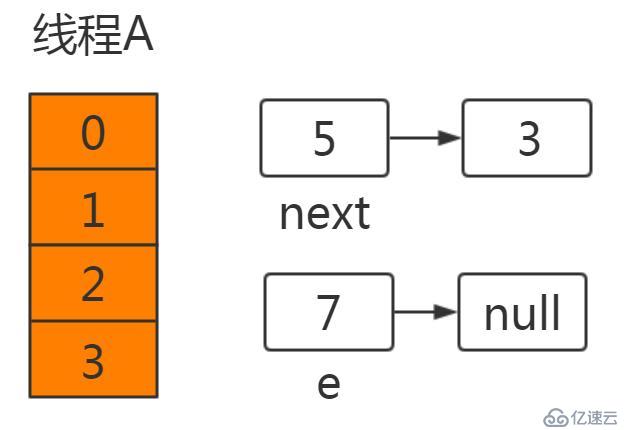
此時線程B已獲得CPU時間片,并完成resize操作: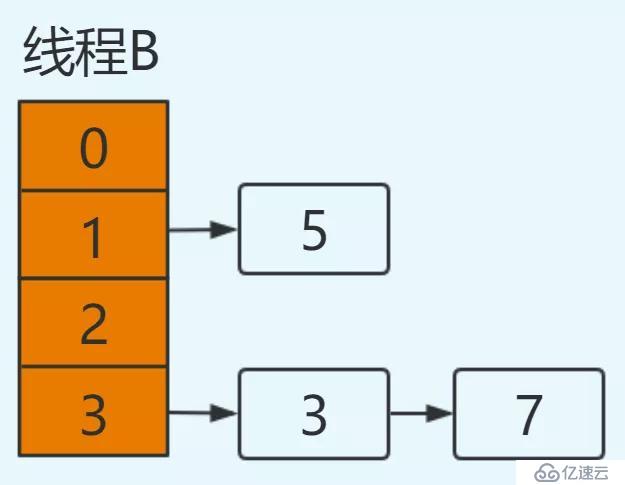
同樣注意由于線程B執行完成,newTable和table都為最新值:5.next=null。
此時切換到線程A,在線程A掛起時:e=7,next=5,newTable[3]=null。
執行newtable[i]=e,就將7放在了table[3]的位置,此時next=5。接著進行下一次循環:
e=5
next=e.next ----> next=null,從主存中取值
e.next=newTable[1] ----> e.next=5,從主存中取值
newTable[1]=e ----> newTable[1]=5
e=next ----> e=null將5放置在table[1]位置,此時e=null循環結束,3元素丟失,并形成環形鏈表。并在后續操作hashmap時造成死循環。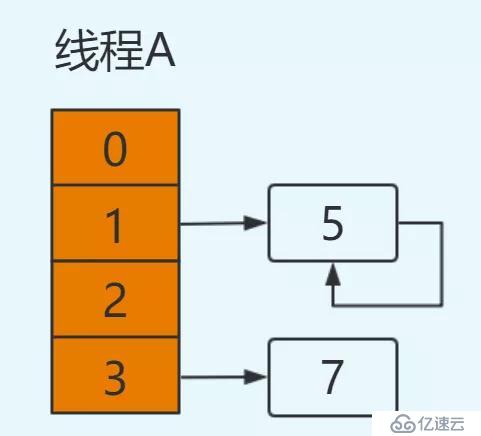
2.jdk1.8中HashMap
在jdk1.8中對HashMap進行了優化,在發生hash碰撞,不再采用頭插法方式,而是直接插入鏈表尾部,因此不會出現環形鏈表的情況,但是在多線程的情況下仍然不安全,這里我們看jdk1.8中HashMap的put操作源碼:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<k,v >[] tab; Node<k,v >p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 如果沒有hash碰撞則直接插入元素
tab[i] = newNode(hash, key, value, null);
else {
Node<k,v >e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<k,v >)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}</k,v></k,v></k,v></k,v> 這是jdk1.8中HashMap中put操作的主函數, 注意第6行代碼,如果沒有hash碰撞則會直接插入元素。如果線程A和線程B同時進行put操作,剛好這兩條不同的數據hash值一樣,并且該位置數據為null,所以這線程A、B都會進入第6行代碼中。
假設一種情況,線程A進入后還未進行數據插入時掛起,而線程B正常執行,從而正常插入數據,然后線程A獲取CPU時間片,此時線程A不用再進行hash判斷了,問題出現:線程A會把線程B插入的數據給覆蓋,發生線程不安全。
總結
首先HashMap是線程不安全的,其主要體現:
在jdk1.7中,在多線程環境下,擴容時會造成環形鏈或數據丟失。在jdk1.8中,在多線程環境下,會發生數據覆蓋的情況。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





