溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Python怎么實現數據清洗”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Python怎么實現數據清洗”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
這里數據清洗需要用到的庫是pandas庫,下載方式還是在終端運行 : pip install pandas.
首先我們需要對數據進行讀取
import pandas as pd
data = pd.read_csv(r'E:\PYthon\用戶價值分析 RFM模型\data.csv')
pd.set_option('display.max_columns', 888) # 大于總列數
pd.set_option('display.width', 1000)
print(data.head())
print(data.info())第3行是對數據進行讀取,pandas庫里面有讀取函數調用即可,csv格式是讀取寫入速度最快的。
第4,5行是為了讀取的實話顯示全部的列,是因為很多列的話pycharm會把中間一些列隱藏掉,所以我們這為了他不隱藏就加這兩行代碼。
第6行是顯示表頭,我們可以看到有什么字段,列名
第7行是顯示表的基本信息,每一列有多少數據,字段是什么類型的數據。非空的數據有多少,所以我們第一步就可以看得到基本那一列有空值了。
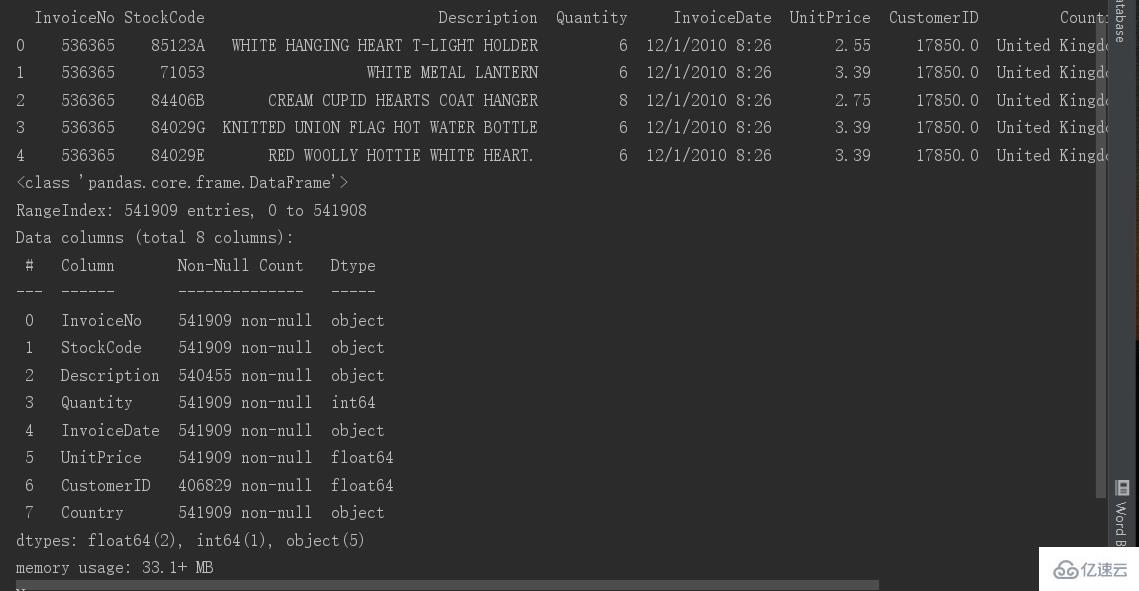
data.info()后我們可以看到大部分數據都有541909行,所以我們大致猜到是Description ,CustomerID 列漏結果了
# 空值處理 print(data.isnull().sum()) # 空值中和,查看每一列的空值 # 空值刪除 data.drop(columns=['Description'], inplace=True) print(data.info()) data.isnull()判斷是否為空。data.isnumll().sum()計算空值數量。
第5行進行空值刪除,這里先刪除Description列的空值,inplace=True意思是對數據進行修改,如果沒有inplace=True,則不對data進行修改,打印數據還是和之前一樣,或者重新定義一個變量進行賦值。
由于這一列空值數據比較少,這一列數據對我們數據分析沒有那么重要,所以我們選擇刪除這一整列。
我們這個表是對客戶進行篩選的,所以以CustomerID為準,強制刪除其他列
# CustomerID有空值 # 刪除所有列的空值 data.dropna(inplace=True) # print(data.info()) print(data.isnull().sum()) # 由于CustomerID為必須字段,所以強制刪除其他列,以CustomerID為準
這里我們先對其他字段進行類型轉換
類型轉換
# 轉換為日期類型
data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate'])
# CustomerID 轉換為整型
data['CustomerID'] = data['CustomerID'].astype('int')
print(data.info())以上我們處理了空值,接下來我們處理異常值。
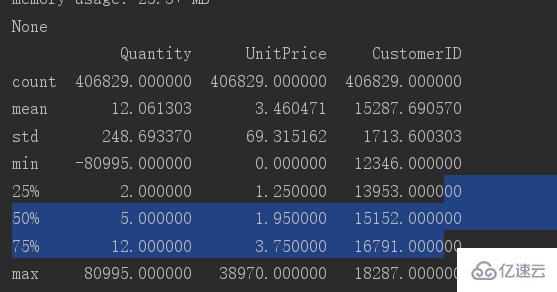
查看表的基本數據分布可以使用describe
print(data.describe())
可以看到數據Quantity 列中最小值為-80995.這列明顯有異常值,所以需要對這一列進行異常值篩選。
只需要大于0的值。
data = data[data['Quantity'] > 0] print(data)
打印一下就只有397924行了。
# 查看重復值 print(data[data.duplicated()])
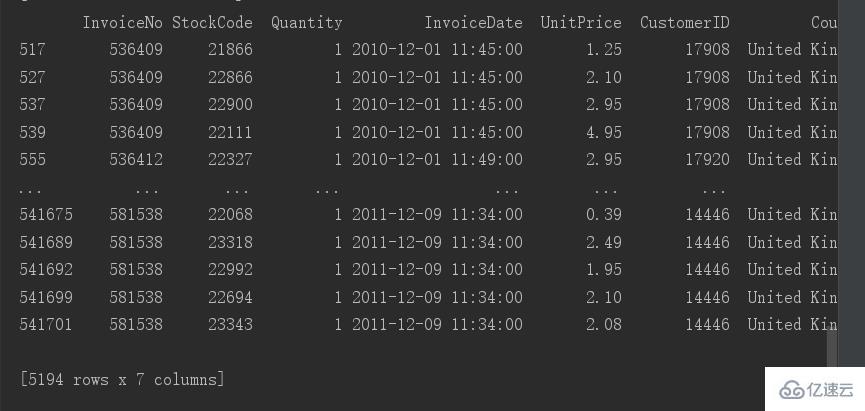
有5194行重復值,這里的重復值是完全重復的,所以是沒用的數據我們可以進行刪除。
# 刪除重復值 data.drop_duplicates(inplace=True) print(data.info())
刪除后對原來的表進行保存,再去查看一下表的基本信息
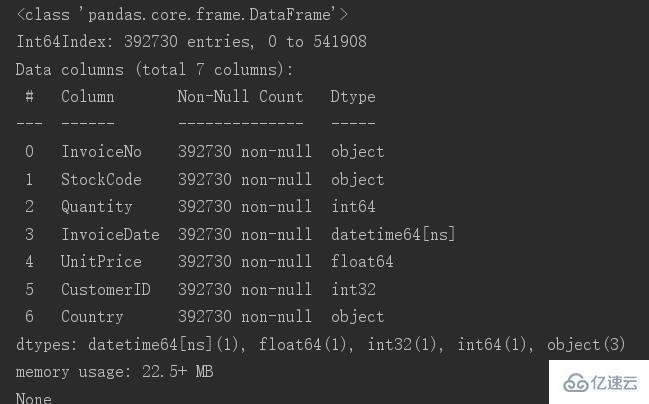
現在還剩下392730條數據。數據到這一步就完成了數據清洗。
讀到這里,這篇“Python怎么實現數據清洗”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





