溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python中如何使用Jieba進行詞頻統計與關鍵詞提取”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Python中如何使用Jieba進行詞頻統計與關鍵詞提取”文章能幫助大家解決問題。
1.導入jieba庫并定義文本
import jieba text = "Python是一種高級編程語言,廣泛應用于人工智能、數據分析、Web開發等領域。"
2.對文本進行分詞
words = jieba.cut(text)
這一步會將文本分成若干個詞語,并返回一個生成器對象words,可以使用for循環遍歷所有的詞語。
3. 統計詞頻
word_count = {}
for word in words:
if len(word) > 1:
word_count[word] = word_count.get(word, 0) + 1這一步通過遍歷所有的詞語,統計每個詞語出現的次數,并保存到一個字典word_count中。在統計詞頻時,可以通過去除停用詞等方式進行優化,這里只是簡單地過濾了長度小于2的詞語。
4. 結果輸出
for word, count in word_count.items(): print(word, count)

為了更準確地統計詞頻,我們可以在詞頻統計中加入停用詞,以去除一些常見但無實際意義的詞語。具體步驟如下:
定義停用詞列表
import jieba # 停用詞列表 stopwords = ['是', '一種', '等']
對文本進行分詞,并過濾停用詞
text = "Python是一種高級編程語言,廣泛應用于人工智能、數據分析、Web開發等領域。" words = jieba.cut(text) words_filtered = [word for word in words if word not in stopwords and len(word) > 1]
統計詞頻并輸出結果
word_count = {}
for word in words_filtered:
word_count[word] = word_count.get(word, 0) + 1
for word, count in word_count.items():
print(word, count)加入停用詞后,輸出的結果是:

可以看到,被停用的一種這個詞并沒有顯示出來。
與對詞語進行單純計數的詞頻統計不同,jieba提取關鍵字的原理是基于TF-IDF(Term Frequency-Inverse Document Frequency)算法。TF-IDF算法是一種常用的文本特征提取方法,可以衡量一個詞語在文本中的重要程度。
具體來說,TF-IDF算法包含兩個部分:
Term Frequency(詞頻):指一個詞在文本中出現的次數,通常用一個簡單的統計值表示,例如詞頻、二元詞頻等。詞頻反映了一個詞在文本中的重要程度,但是忽略了這個詞在整個語料庫中的普遍程度。
Inverse Document Frequency(逆文檔頻率):指一個詞在所有文檔中出現的頻率的倒數,用于衡量一個詞的普遍程度。逆文檔頻率越大,表示一個詞越普遍,重要程度越低;逆文檔頻率越小,表示一個詞越獨特,重要程度越高。
TF-IDF算法通過綜合考慮詞頻和逆文檔頻率,計算出每個詞在文本中的重要程度,從而提取關鍵字。在jieba中,關鍵字提取的具體實現包括以下步驟:
對文本進行分詞,得到分詞結果。
統計每個詞在文本中出現的次數,計算出詞頻。
統計每個詞在所有文檔中出現的次數,計算出逆文檔頻率。
綜合考慮詞頻和逆文檔頻率,計算出每個詞在文本中的TF-IDF值。
對TF-IDF值進行排序,選取得分最高的若干個詞作為關鍵字。
舉個例子:
F(Term Frequency)指的是某個單詞在一篇文檔中出現的頻率。計算公式如下:
T F = ( 單詞在文檔中出現的次數 ) / ( 文檔中的總單詞數 )
例如,在一篇包含100個單詞的文檔中,某個單詞出現了10次,則該單詞的TF為
10 / 100 = 0.1
IDF(Inverse Document Frequency)指的是在文檔集合中出現某個單詞的文檔數的倒數。計算公式如下:
I D F = l o g ( 文檔集合中的文檔總數 / 包含該單詞的文檔數 )
例如,在一個包含1000篇文檔的文檔集合中,某個單詞在100篇文檔中出現過,則該單詞的IDF為 l o g ( 1000 / 100 ) = 1.0
TFIDF是將TF和IDF相乘得到的結果,計算公式如下:
T F I D F = T F ∗ I D F
需要注意的是,TF-IDF算法只考慮了詞語在文本中的出現情況,而忽略了詞語之間的關聯性。因此,在一些特定的應用場景中,需要使用其他的文本特征提取方法,例如詞向量、主題模型等。
import jieba.analyse # 待提取關鍵字的文本 text = "Python是一種高級編程語言,廣泛應用于人工智能、數據分析、Web開發等領域。" # 使用jieba提取關鍵字 keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True) # 輸出關鍵字和對應的權重 for keyword, weight in keywords: print(keyword, weight)
在這個示例中,我們首先導入了jieba.analyse模塊,然后定義了一個待提取關鍵字的文本text。接著,我們使用jieba.analyse.extract_tags()函數提取關鍵字,其中topK參數表示需要提取的關鍵字個數,withWeight參數表示是否返回關鍵字的權重值。最后,我們遍歷關鍵字列表,輸出每個關鍵字和對應的權重值。
這段函數的輸出結果為:
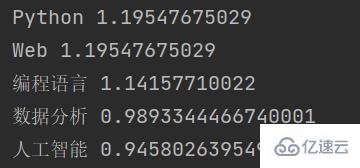
可以看到,jieba根據TF-IDF算法提取出了輸入文本中的若干個關鍵字,并返回了每個關鍵字的權重值。
關于“Python中如何使用Jieba進行詞頻統計與關鍵詞提取”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





