溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“怎么使用Python實現遺傳算法”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“怎么使用Python實現遺傳算法”文章吧。
(1)初始化:設置進化代數計數器 t=0、設置最大進化代數 T、交叉概率、變異概率、隨機生成 M 個個體作為初始種群 P
(2)個體評價:計算種群 P 中各個個體的適應度
(3)選擇運算:將選擇算子作用于群體。以個體適應度為基礎,選擇最優個體直接遺傳到下一代或通過配對交叉產生新的個體再遺傳到下一代
(4)交叉運算:在交叉概率的控制下,對群體中的個體兩兩進行交叉
(5)變異運算:在變異概率的控制下,對群體中的個體進行變異,即對某一個體的基因進行隨機調整
(6) 經過選擇、交叉、變異運算之后得到下一代群體 P1。
重復以上(1)-(6),直到遺傳代數為 T,以進化過程中所得到的具有最優適應度個體作為最優解輸出,終止計算。
旅行推銷員問題(Travelling Salesman Problem, TSP):有 n 個城市,一個推銷員要從其中某一個城市出發,唯一走遍所有的城市,再回到他出發的城市,求最短的路線。
應用遺傳算法求解 TSP 問題時需要進行一些約定,基因是一組城市序列,適應度是按照這個基因的城市順序的距離和分之一。
import random
import math
import matplotlib.pyplot as plt
# 讀取數據
f=open("test.txt")
data=f.readlines()
# 將cities初始化為字典,防止下面被當成列表
cities={}
for line in data:
#原始數據以\n換行,將其替換掉
line=line.replace("\n","")
#最后一行以EOF為標志,如果讀到就證明讀完了,退出循環
if(line=="EOF"):
break
#空格分割城市編號和城市的坐標
city=line.split(" ")
map(int,city)
#將城市數據添加到cities中
cities[eval(city[0])]=[eval(city[1]),eval(city[2])]
# 計算適應度,也就是距離分之一,這里用偽歐氏距離
def calcfit(gene):
sum=0
#最后要回到初始城市所以從-1,也就是最后一個城市繞一圈到最后一個城市
for i in range(-1,len(gene)-1):
nowcity=gene[i]
nextcity=gene[i+1]
nowloc=cities[nowcity]
nextloc=cities[nextcity]
sum+=math.sqrt(((nowloc[0]-nextloc[0])**2+(nowloc[1]-nextloc[1])**2)/10)
return 1/sum
# 每個個體的類,方便根據基因計算適應度
class Person:
def __init__(self,gene):
self.gene=gene
self.fit=calcfit(gene)
class Group:
def __init__(self):
self.GroupSize=100 #種群規模
self.GeneSize=48 #基因數量,也就是城市數量
self.initGroup()
self.upDate()
#初始化種群,隨機生成若干個體
def initGroup(self):
self.group=[]
i=0
while(i<self.GroupSize):
i+=1
#gene如果在for以外生成只會shuffle一次
gene=[i+1 for i in range(self.GeneSize)]
random.shuffle(gene)
tmpPerson=Person(gene)
self.group.append(tmpPerson)
#獲取種群中適應度最高的個體
def getBest(self):
bestFit=self.group[0].fit
best=self.group[0]
for person in self.group:
if(person.fit>bestFit):
bestFit=person.fit
best=person
return best
#計算種群中所有個體的平均距離
def getAvg(self):
sum=0
for p in self.group:
sum+=1/p.fit
return sum/len(self.group)
#根據適應度,使用輪盤賭返回一個個體,用于遺傳交叉
def getOne(self):
#section的簡稱,區間
sec=[0]
sumsec=0
for person in self.group:
sumsec+=person.fit
sec.append(sumsec)
p=random.random()*sumsec
for i in range(len(sec)):
if(p>sec[i] and p<sec[i+1]):
#這里注意區間是比個體多一個0的
return self.group[i]
#更新種群相關信息
def upDate(self):
self.best=self.getBest()
# 遺傳算法的類,定義了遺傳、交叉、變異等操作
class GA:
def __init__(self):
self.group=Group()
self.pCross=0.35 #交叉率
self.pChange=0.1 #變異率
self.Gen=1 #代數
#變異操作
def change(self,gene):
#把列表隨機的一段取出然后再隨機插入某個位置
#length是取出基因的長度,postake是取出的位置,posins是插入的位置
geneLenght=len(gene)
index1 = random.randint(0, geneLenght - 1)
index2 = random.randint(0, geneLenght - 1)
newGene = gene[:] # 產生一個新的基因序列,以免變異的時候影響父種群
newGene[index1], newGene[index2] = newGene[index2], newGene[index1]
return newGene
#交叉操作
def cross(self,p1,p2):
geneLenght=len(p1.gene)
index1 = random.randint(0, geneLenght - 1)
index2 = random.randint(index1, geneLenght - 1)
tempGene = p2.gene[index1:index2] # 交叉的基因片段
newGene = []
p1len = 0
for g in p1.gene:
if p1len == index1:
newGene.extend(tempGene) # 插入基因片段
p1len += 1
if g not in tempGene:
newGene.append(g)
p1len += 1
return newGene
#獲取下一代
def nextGen(self):
self.Gen+=1
#nextGen代表下一代的所有基因
nextGen=[]
#將最優秀的基因直接傳遞給下一代
nextGen.append(self.group.getBest().gene[:])
while(len(nextGen)<self.group.GroupSize):
pChange=random.random()
pCross=random.random()
p1=self.group.getOne()
if(pCross<self.pCross):
p2=self.group.getOne()
newGene=self.cross(p1,p2)
else:
newGene=p1.gene[:]
if(pChange<self.pChange):
newGene=self.change(newGene)
nextGen.append(newGene)
self.group.group=[]
for gene in nextGen:
self.group.group.append(Person(gene))
self.group.upDate()
#打印當前種群的最優個體信息
def showBest(self):
print("第{}代\t當前最優{}\t當前平均{}\t".format(self.Gen,1/self.group.getBest().fit,self.group.getAvg()))
#n代表代數,遺傳算法的入口
def run(self,n):
Gen=[] #代數
dist=[] #每一代的最優距離
avgDist=[] #每一代的平均距離
#上面三個列表是為了畫圖
i=1
while(i<n):
self.nextGen()
self.showBest()
i+=1
Gen.append(i)
dist.append(1/self.group.getBest().fit)
avgDist.append(self.group.getAvg())
#繪制進化曲線
plt.plot(Gen,dist,'-r')
plt.plot(Gen,avgDist,'-b')
plt.show()
ga=GA()
ga.run(3000)
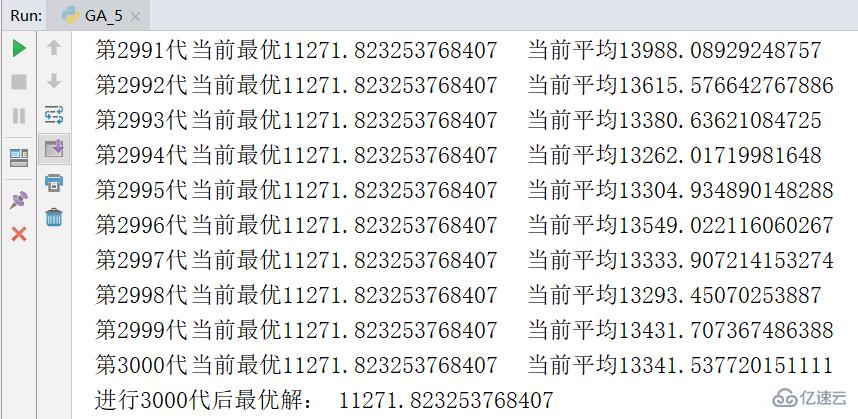
print("進行3000代后最優解:",1/ga.group.getBest().fit)下圖是進行一次實驗的結果截圖,求出的最優解是 11271
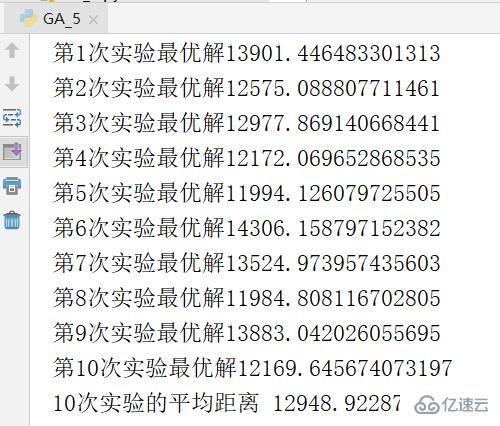
為避免實驗的偶然性,進行 10 次重復實驗,并求平均值,結果如下。
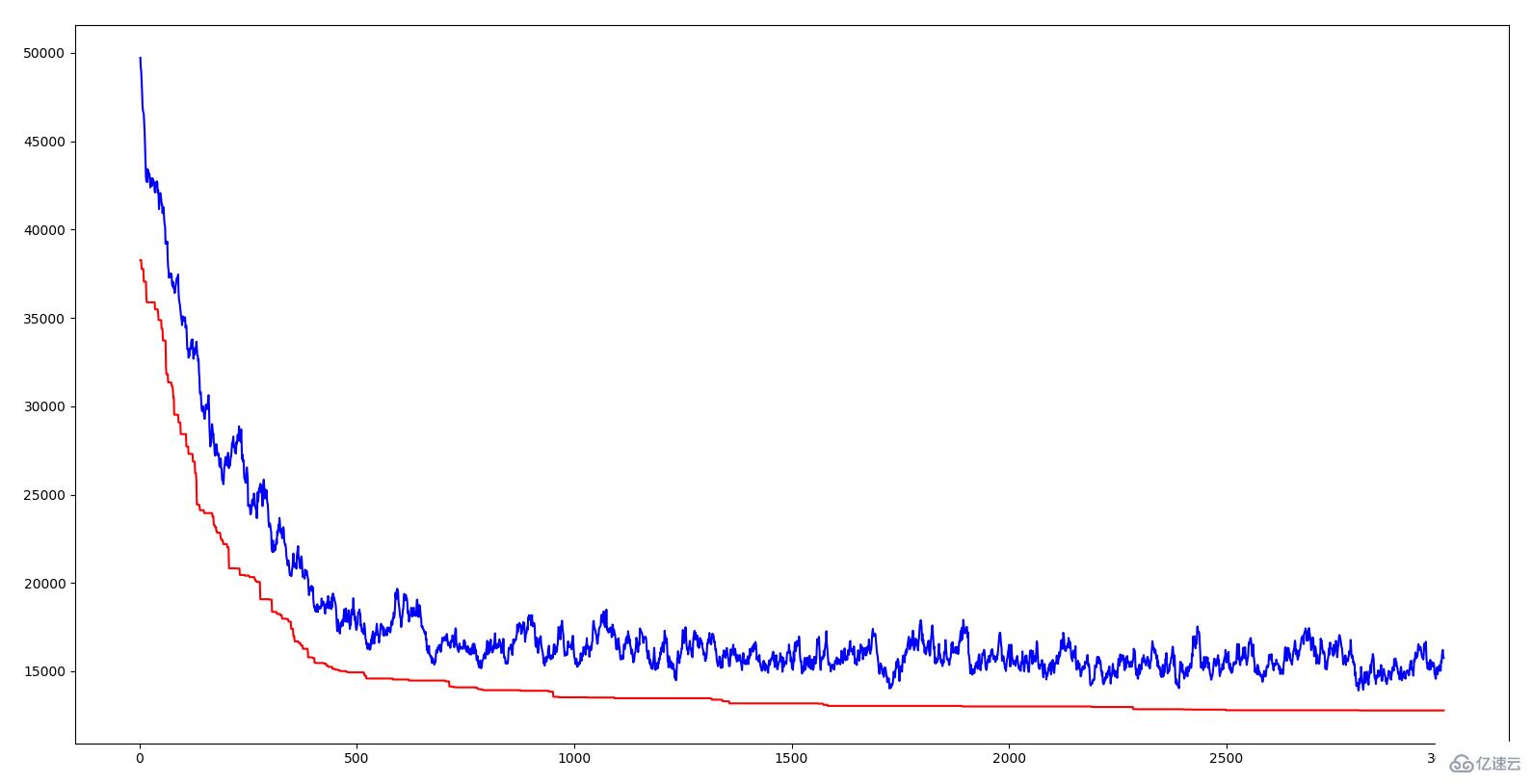
上圖橫坐標是代數,縱坐標是距離,紅色曲線是每一代的最優個體的距離,藍色曲線是每一代的平均距離。可以看出兩條線都呈下降趨勢,也就是說都在進化。平均距離下降說明由于優良基因的出現(也就是某一段城市序列),使得這種優良的性狀很快傳播到整個群體。就像自然界中的優勝劣汰一樣,具有適應環境的基因才能生存下來,相應的,生存下來的都是具有優良基因的。算法中引入交叉率和變異率的意義就在于既要保證當前優良基因,又要試圖產生更優良的基因。如果所有個體都交叉,那么有些優良的基因片段可能會丟失;如果都不交叉,那么兩個優秀的基因片段無法組合為更優秀的基因;如果沒有變異,那就無法產生更適應環境的個體。不得不感嘆自然的智慧是如此強大。
上面說到的基因片段就是 TSP 中的一小段城市序列,當某一段序列的距離和相對較小時,就說明這段序列是這幾個城市的相對較好的遍歷順序。遺傳算法通過將這些優秀的片段組合起來實現了 TSP 解的不斷優化。而組合的方法正是借鑒自然的智慧,遺傳、變異、適者生存。
所謂優勝劣汰也就是優良的基因保留,不適應環境的基因淘汰。在上述 GA 算法中,我使用的是輪盤賭,也就是在遺傳的步驟中(無論是否交叉),根據每個個體的適應度來挑選。這樣就能達到適應度高得個體有更多的后代,也就達到了優勝劣汰的目的。
在具體的實現過程中,我犯了個錯誤,起初在遺傳步驟篩選個體時,我每選出一個個體就將這個個體從群體中刪除。現在想想,這種做法十分愚蠢,盡管當時我已經實現了輪盤賭,但如果選出個體就刪除,那么就會導致每個個體都會平等地生育后代,所謂的輪盤賭也不過是能讓適應度高的先進行遺傳。這種做法完全背離了“優勝劣汰”的初衷。正確的做法是選完個體進行遺傳后再重新放回群體,這樣才能保證適應度高的個體會進行多次遺傳,產生更多后代,將優良的基因更廣泛的播撒,同時不適應的個體會產生少量后代或者直接被淘汰。
所謂正向進行也就是下一代的最優個體一定比上一代更適應或者同等適應環境。我采用的方法是最優個體直接進入下一代,不參與交叉變異等操作。這樣能夠防止因這些操作而“污染”了當前最優秀的基因而導致反向進化的出現。
我在實現過程中還出現了另一點問題,是傳引用還是傳值所導致的。對個體的基因進行交叉和變異時用的是一個列表,Python 中傳列表時傳的實際上是一個引用,這樣就導致個體進行交叉和變異后會改變個體本身的基因。導致的結果就是進化非常緩慢,并且伴隨反向進化。
選定一個個體的片段放入另一個體,并將不重復的基因的依次放入其他位置。
在實現這一步時,因為學生物時對真實染色體行為的固有認識,“同源染色體交叉互換同源區段”,導致我錯誤實現該功能。我只將兩個個體的相同位置的片段互換來完成交叉,顯然這樣的做法是錯誤的,這會導致城市的重復出現。
后續測試過程中發現要改參數,更新個體信息時很麻煩,于是全部改為 OOP,然后方便多了。對于這種模擬真實世界的問題,OOP 有很大的靈活性和簡便性。
在測試過程中發現偶爾會出現局部最優解,在很長時間內不會繼續進化,而此時的解又離最優解較遠。哪怕是后續調整后,盡管離最優解近了,但依然是“局部最優”,因為還沒有達到最優。
算法在起初會收斂得很快,而越往后就會越來越慢,甚至根本不動。因為到后期,所有個體都有著相對來說差不多的優秀基因,這時的交叉對于進化的作用就很弱了,進化的主要動力就成了變異,而變異就是一種暴力算法了。運氣好的話能很快變異出更好的個體,運氣不好就得一直等。
防止局部最優解的解決方法是增大種群規模,這樣就會有更多的個體變異,就會有更大可能性產生進化的個體。而增大種群規模的弊端是每一代的計算時間會變長,也就是說這兩者是相互抑制的。巨大的種群規模雖然最終能避免局部最優解,但是每一代的時間很長,需要很長時間才能求出最優解;而較小的種群規模雖然每一代計算時間快,但在若干代后就會陷入局部最優。
猜想一種可能的優化方法,在進化初期用較小的種群規模,以此來加快進化速度,當適應度達到某一閾值后,增加種群規模和變異率來避免局部最優解的出現。用這種動態調整的方法來權衡每一代計算效率和整體計算效率之間的平衡。
以上就是關于“怎么使用Python實現遺傳算法”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





