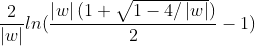溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python中常用的激活函數有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
激活函數 (Activation functions) 對于人工神經網絡模型去學習、理解非常復雜和非線性的函數來說具有十分重要的作用。它們將非線性特性引入到神經網絡中。在下圖中,輸入的 inputs 通過加權,求和后,還被作用了一個函數f,這個函數f就是激活函數。引入激活函數是為了增加神經網絡模型的非線性。沒有激活函數的每層都相當于矩陣相乘。就算你疊加了若干層之后,無非還是個矩陣相乘罷了。
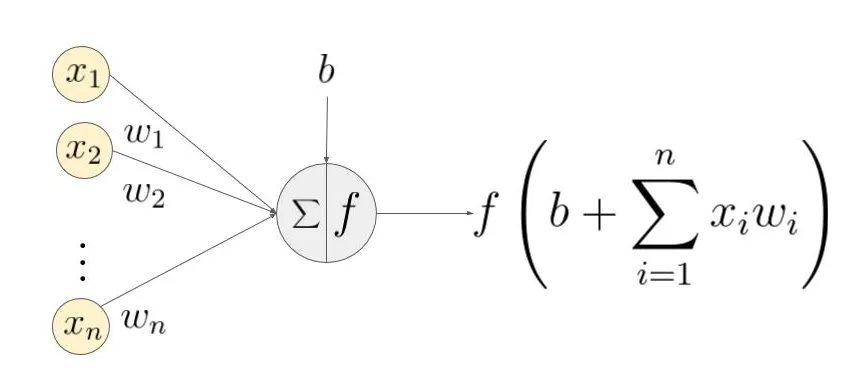
為什么使用激活函數?
如果不用激勵函數(其實相當于激勵函數是f(x) = x),在這種情況下你每一層節點的輸入都是上層輸出的線性函數,很容易驗證,無論你神經網絡有多少層,輸出都是輸入的線性組合,與沒有隱藏層效果相當,這種情況就是最原始的感知機(Perceptron)了,那么網絡的逼近能力就相當有限。正因為上面的原因,我們決定引入非線性函數作為激勵函數,這樣深層神經網絡表達能力就更加強大(不再是輸入的線性組合,而是幾乎可以逼近任意函數)。
激活函數有哪些性質?
非線性:當激活函數是非線性的,一個兩層的神經網絡就可以基本上逼近所有的函數。但如果激活函數是恒等激活函數的時候,即f(x) = x,就不滿足這個性質,而且如果MLP使用的是恒等激活函數,那么其實整個網絡跟單層神經網絡是等價的。
可微性:當優化方法是基于梯度的時候,就體現的該本質。
單調性:當激活函數是單調的時候,單層網絡能夠保證是凸函數。
輸出值的范圍:當激活函數輸出值是有限的時候,基于梯度的優化方法會更加穩定,因為特征的表示受有限權值的影響更顯著;當激活函數的輸出是無限的時候,模型的訓練更加高效,不過這種情況很小,一般需要更小的learning rate。
梯度消失與梯度爆炸
層數比較多的神經網絡模型在訓練的時候會出現梯度消失(gradient vanishing problem)和梯度爆炸(gradient exploding problem)問題。梯度消失問題和梯度爆炸問題一般會隨著網絡層數的增加變得越來越明顯。
例如,一個網絡含有三個隱藏層,梯度消失問題發生時,靠近輸出層的hidden layer 3的權值更新相對正常,但是靠近輸入層的hidden layer1的權值更新會變得很慢,導致靠近輸入層的隱藏層權值幾乎不變,仍接近于初始化的權值。這就導致hidden layer 1 相當于只是一個映射層,對所有的輸入做了一個函數映射,這時此深度神經網絡的學習就等價于只有后幾層的隱藏層網絡在學習。梯度爆炸的情況是:當初始的權值過大,靠近輸入層的hidden layer 1的權值變化比靠近輸出層的hidden layer 3的權值變化更快,就會引起梯度爆炸的問題。
梯度消失的根本原因
以下圖的反向傳播為例:
假設σ為sigmoid,C為代價函數。
下圖(1)式為該網絡的前向傳播公式。
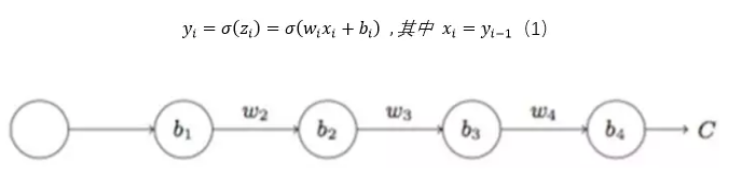
根據前向傳播公式,我們得出梯度更新公式:
其中由公式(1)得出
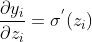
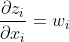
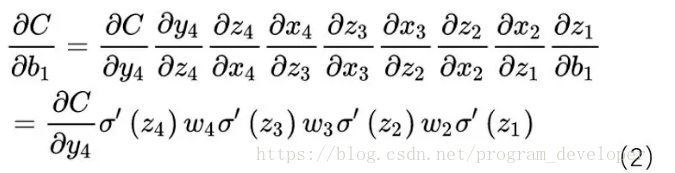
sigmoid函數的導數如下圖所示
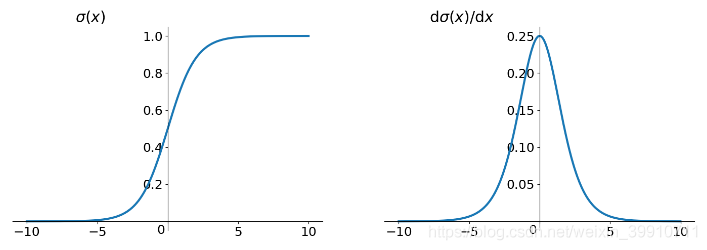
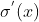
的最大值是

,而我們一般會使用標準方法來初始化網絡權重,即使用一個均值為0標準差為1的高斯分布。因此,初始化的網絡權值通常都小于1,從而有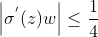 。對于2式的鏈式求導,層數越多,求導結果越小,前面的網絡層比后面的網絡層梯度變化更小,故權值變化緩慢,最終導致梯度消失的情況出現。
。對于2式的鏈式求導,層數越多,求導結果越小,前面的網絡層比后面的網絡層梯度變化更小,故權值變化緩慢,最終導致梯度消失的情況出現。
梯度爆炸的根本原因
當
,也就是w比較大的情況。則前面的網絡層比后面的網絡層梯度變化更快,引起了梯度爆炸的問題。
當激活函數為sigmoid時,梯度消失和梯度爆炸那個更容易發生?
梯度消失較容易發生
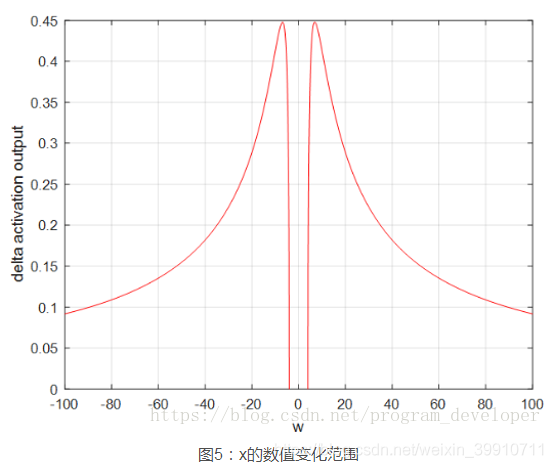
量化分析梯度爆炸時x的取值范圍:因導數最大為0.25,故|w|>4,才可能出現;按照可計算出x的數值變化范圍很窄,僅在公式3范圍內,才會出現梯度爆炸。畫圖如5所示,可見x的數值變化范圍很小;最大數值范圍也僅僅0.45,當|w|=6.9時出現。因此僅僅在此很窄的范圍內會出現梯度爆炸的問題。
如何解決梯度消失和梯度爆炸問題?
梯度消失和梯度爆炸問題都是因為網絡太深,網絡權值更新不穩定造成的,本質上是因為梯度反向傳播中的連乘效應。對于更普遍的梯度消失問題,可以考慮一下三種方案解決:
1. 用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函數。
2. 用Batch Normalization。
3. LSTM的結構設計也可以改善RNN中的梯度消失問題。
激活函數分為兩類,飽和激活函數和非飽和激活函數。
飽和激活函數包括sigmoid、tanh;非飽和激活函數包括ReLU、PReLU、Leaky ReLU、RReLU、ELU等。
那什么是飽和函數呢?

sigmoid和tanh是“飽和激活函數”,而ReLU及其變體則是“非飽和激活函數”。使用“非飽和激活函數”的優勢在于兩點:(1)"非飽和激活函數”能解決所謂的“梯度消失”問題。(2)它能加快收斂速度。
Sigmoid函數將一個實值輸入壓縮至[0,1]的范圍---------σ(x) = 1 / (1 + exp(−x))
tanh函數將一個實值輸入壓縮至 [-1, 1]的范圍---------tanh(x) = 2σ(2x) − 1
由于使用sigmoid激活函數會造成神經網絡的梯度消失和梯度爆炸問題,所以許多人提出了一些改進的激活函數,如:tanh、ReLU、Leaky ReLU、PReLU、RReLU、ELU、Maxout。
sigmoid的數學公式為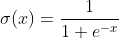
其導數公式為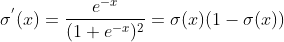
如下圖所示,左圖為sigmoid的函數圖,右圖為其導數圖.
特點:它能夠把輸入的連續實值變換為0和1之間的輸出,特別的,如果是非常大的負數,那么輸出就是0;如果是非常大的正數,輸出就是1。
在什么情況下適合使用 Sigmoid 激活函數?
Sigmoid 函數的輸出范圍是 0 到 1。由于輸出值限定在 0 到 1,因此它對每個神經元的輸出進行了歸一化;用于將預測概率作為輸出的模型。由于概率的取值范圍是 0 到 1,因此 Sigmoid 函數非常合適;梯度平滑,避免「跳躍」的輸出值;函數是可微的。這意味著可以找到任意兩個點的 sigmoid 曲線的斜率;明確的預測,即非常接近 1 或 0。
缺點:
容易出現梯度消失函數輸出并不是zero-centered(零均值)冪運算相對來講比較耗時1.梯度消失
優化神經網絡的方法是梯度回傳:先計算輸出層對應的 loss,然后將 loss 以導數的形式不斷向上一層網絡傳遞,修正相應的參數,達到降低loss的目的。 Sigmoid函數在深度網絡中常常會導致導數逐漸變為0,使得參數無法被更新,神經網絡無法被優化。原因在于兩點:
當σ(x)中的x較大或較小時,導數接近0,而后向傳遞的數學依據是微積分求導的鏈式法則,當前層的導數需要之前各層導數的乘積,幾個小數的相乘,結果會很接近0。Sigmoid導數的最大值是0.25,這意味著導數在每一層至少會被壓縮為原來的1/4,通過兩層后被變為1/16,…,通過10層后為1/1048576。請注意這里是“至少”,導數達到最大值這種情況還是很少見的。2.零均值
零均值是不可取的,因為這會導致后一層的神經元將得到上一層輸出的非0均值的信號作為輸入。 Sigmoid函數的輸出值恒大于0,這會導致模型訓練的收斂速度變慢。舉例來講,對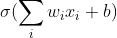 ,如果所有
,如果所有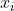 均為正數或負數,那么其對
均為正數或負數,那么其對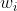 的導數總是正數或負數,這會導致如下圖紅色箭頭所示的階梯式更新,這顯然并非一個好的優化路徑。深度學習往往需要大量時間來處理大量數據,模型的收斂速度是尤為重要的。所以,總體上來講,訓練深度學習網絡盡量使用zero-centered數據 (可以經過數據預處理實現) 和zero-centered輸出。
的導數總是正數或負數,這會導致如下圖紅色箭頭所示的階梯式更新,這顯然并非一個好的優化路徑。深度學習往往需要大量時間來處理大量數據,模型的收斂速度是尤為重要的。所以,總體上來講,訓練深度學習網絡盡量使用zero-centered數據 (可以經過數據預處理實現) 和zero-centered輸出。
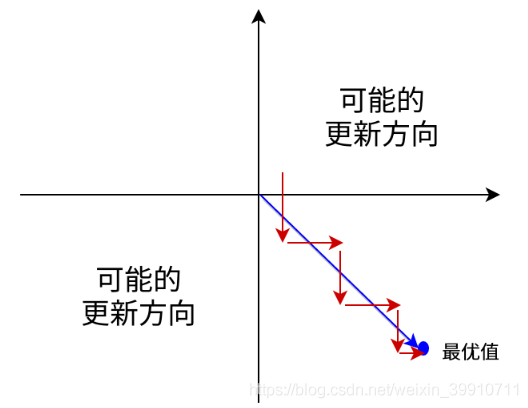
不是zero-centered產生的一個結果就是:如果數據進入神經元的時候是正的
,那么 w 計算出的梯度也會始終都是正的。當然了,如果你是按batch去訓練,那么那個batch可能得到不同的信號,所以這個問題還是可以緩解一下的。因此,非0均值這個問題雖然會產生一些不好的影響,不過跟上面提到的梯度消失問題相比還是要好很多的。
3.冪運算相對耗時
相對于前兩項,這其實并不是一個大問題,我們目前是具備相應計算能力的,但面對深度學習中龐大的計算量,最好是能省則省。之后我們會看到,在ReLU函數中,需要做的僅僅是一個thresholding,相對于冪運算來講會快很多。
tanh的數學公式為: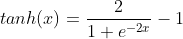
其導數為: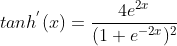
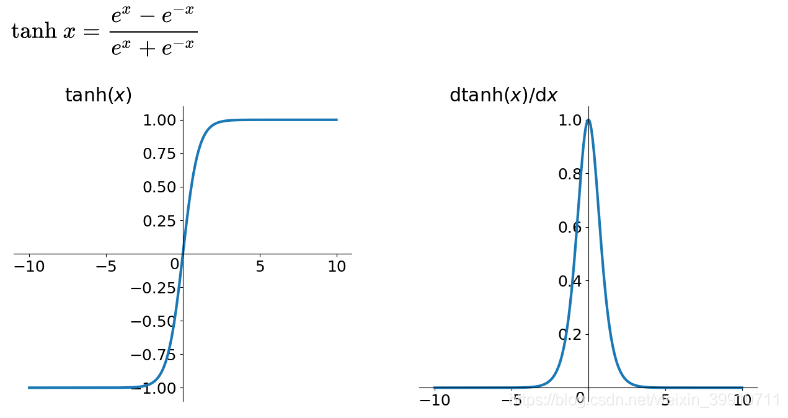
sigmoid與tanh的比較
首先,當輸入較大或較小時,輸出幾乎是平滑的并且梯度較小,這不利于權重更新。二者的區別在于輸出間隔,tanh 的輸出間隔為 1,并且整個函數以 0 為中心,比 sigmoid 函數更好;
在 tanh 圖中,負輸入將被強映射為負,而零輸入被映射為接近零。
注意:在一般的二元分類問題中,tanh 函數用于隱藏層,而 sigmoid 函數用于輸出層,但這并不是固定的,需要根據特定問題進行調整。
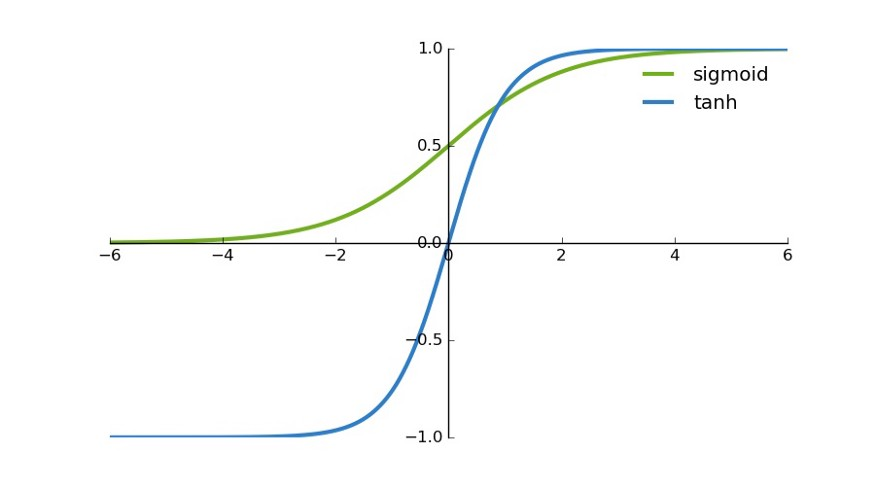
ReLU的數學表達式為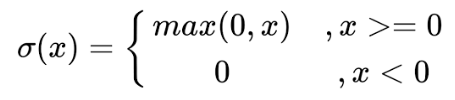
其導數公式為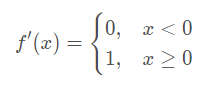
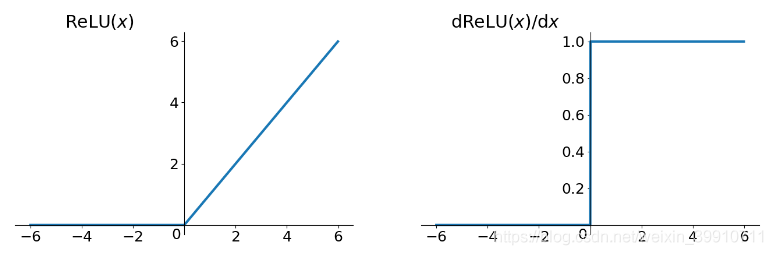
ReLU的優點:
解決了梯度消失問題 (在正區間),ReLU的非飽和性可以有效地解決梯度消失的問題, 提供相對寬的激活邊界。Sigmoid和Tanh激活函數均需要計算指數, 復雜度高, 而ReLU只需要一個閾值即可得到激活值。ReLU 函數中只存在線性關系,因此它的計算速度比 sigmoid 和 tanh 更快。計算速度非常快,只需要判斷輸入是否大于0。收斂速度遠快于sigmoid和tanhReLU使得一部分神經元的輸出為0,這樣就造成了網絡的稀疏性,并且減少了參數的互相依存關系,緩解了過擬合問題的發生
ReLU存在的問題
ReLU 函數的輸出為 0 或正數,不是zero-centered對參數初始化和學習率非常敏感;ReLU 函數的輸出均值大于0,偏移現象和神經元死亡會共同影響網絡的收斂性。存在神經元死亡,指的是某些神經元可能永遠不會被激活,導致相應的參數永遠不能被更新。這是由于函數導致負梯度在經過該ReLU單元時被置為0, 且在之后也不被任何數據激活, 即流經該神經元的梯度永遠為0, 不對任何數據產生響應。 當輸入為負時,ReLU 完全失效,在正向傳播過程中,這不是問題。有些區域很敏感,有些則不敏感。但是在反向傳播過程中,如果輸入負數,則梯度將完全為零,sigmoid 函數和 tanh 函數也具有相同的問題。有兩個主要原因可能導致這種情況產生: (1) 非常不幸的參數初始化,這種情況比較少見; (2) learning rate太高導致在訓練過程中參數更新太大,會導致超過一定比例的神經元不可逆死亡, 進而參數梯度無法更新, 整個訓練過程失敗。解決方法是可以采用Xavier初始化方法,以及避免將learning rate設置太大或使用adagrad等自動調節learning rate的算法。
怎樣理解ReLU(<0)時是非線性激活函數?
從圖像可看出具有如下特點:
單側抑制相對寬闊的興奮邊界稀疏激活性ReLU函數從圖像上看,是一個分段線性函數,把所有的負值都變為0,而正值不變,這樣就成為單側抑制。
因為有了這單側抑制,才使得神經網絡中的神經元也具有了稀疏激活性。
稀疏激活性:從信號方面來看,即神經元同時只對輸入信號的少部分選擇性響應,大量信號被刻意的屏蔽了,這樣可以提高學習的精度,更好更快地提取稀疏特征。當x<0時,ReLU硬飽和,當x>0時,則不存在飽和函數。ReLU能夠在在x>0時保持梯度不衰減,從而緩解梯度消失問題。
人們為了解決失效神經元,提出了將ReLU的前半段設為αx而非0。
Leaky ReLU的數學表達式為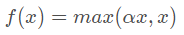
其導數公式為
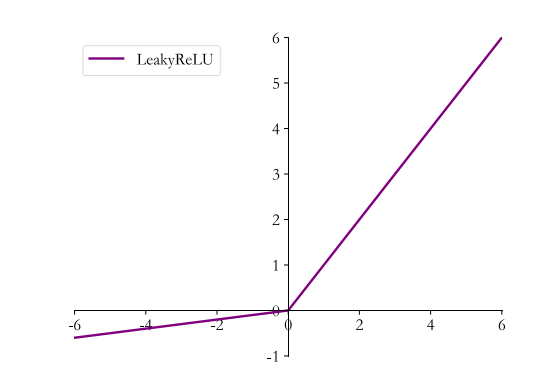
為什么 Leaky ReLU 比 ReLU 更好?
Leaky ReLU 通過把 x 的非常小的線性分量給予負輸入(αx)來調整負值的零梯度(zero gradients)問題;leak 有助于擴大 ReLU 函數的范圍,通常 a 的值為 0.01 左右;Leaky ReLU 的函數范圍是(負無窮到正無窮)。但另一方面, a值的選擇增加了問題難度, 需要較強的人工先驗或多次重復訓練以確定合適的參數值。
LeakyReLU與ReLU和PReLU之間區別
if α=0 ,則函數是ReLUif α>0 ,則函數是Leaky ReLUif α是可學習參數,則函數是PReLU(Parametric ReLU)
ELU 的提出也解決了 ReLU 的問題。與 ReLU 相比,ELU 有負值,這會使激活的平均值接近零。均值激活接近于零可以使學習更快,因為它們使梯度更接近自然梯度。

顯然,ELU 具有 ReLU 的所有優點,并且:
沒有 Dead ReLU 問題,輸出的平均值接近 0,以 0 為中心;ELU 通過減少偏置偏移的影響,使正常梯度更接近于單位自然梯度,從而使均值向零加速學習;ELU 在較小的輸入下會飽和至負值,從而減少前向傳播的變異和信息。一個小問題是它的計算強度更高。與 Leaky ReLU 類似,盡管理論上比 ReLU 要好,但目前在實踐中沒有充分的證據表明 ELU 總是比 ReLU 好。
Softmax 是用于多類分類問題的激活函數,在多類分類問題中,超過兩個類標簽則需要類成員關系。對于長度為 K 的任意實向量,Softmax 可以將其壓縮為長度為 K,值在(0,1)范 圍內,并且向量中元素的總和為 1 的實向量。
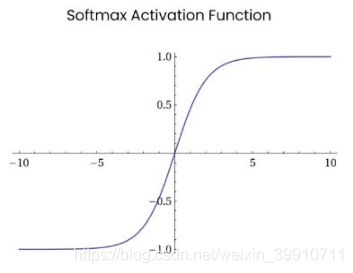
Softmax 與正常的 max 函數不同:max 函數僅輸出最大值,但 Softmax 確保較小的值具有較小的概率,并且不會直接丟棄。我們可以認為它是 argmax 函數的概率版本或「soft」版本。
Softmax 函數的分母結合了原始輸出值的所有因子,這意味著 Softmax 函數獲得的各種概率彼此相關。
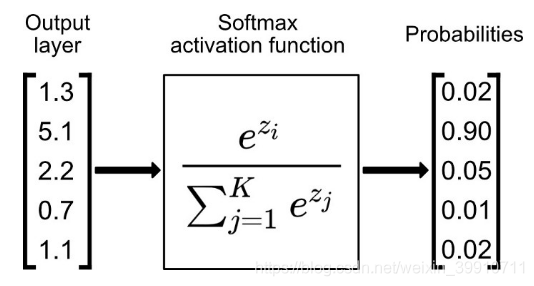
Softmax 激活函數的主要缺點是:
在零點不可微;負輸入的梯度為零,這意味著對于該區域的激活,權重不會在反向傳播期間更新,因此會產生永不激活的死亡神經元。
Swish的表達式為y = x * sigmoid (x)
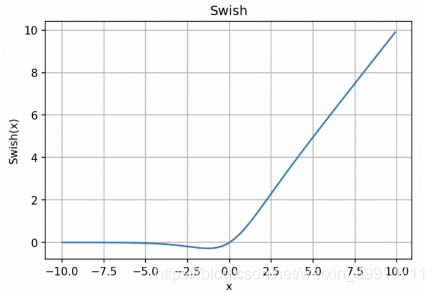
Swish 的設計受到了 LSTM 和高速網絡中 gating 的 sigmoid 函數使用的啟發。我們使用相同的 gating 值來簡化 gating 機制,這稱為 self-gating。
self-gating 的優點在于它只需要簡單的標量輸入,而普通的 gating 則需要多個標量輸入。這使得諸如 Swish 之類的 self-gated 激活函數能夠輕松替換以單個標量為輸入的激活函數(例如 ReLU),而無需更改隱藏容量或參數數量。
Swish 激活函數的主要優點如下:
「無界性」有助于防止慢速訓練期間,梯度逐漸接近 0 并導致飽和;(同時,有界性也是有優勢的,因為有界激活函數可以具有很強的正則化,并且較大的負輸入問題也能解決);導數恒 > 0;平滑度在優化和泛化中起了重要作用。
“Python中常用的激活函數有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。