溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了MySQL中存儲的數據查詢的時候怎么區分大小寫的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇MySQL中存儲的數據查詢的時候怎么區分大小寫文章都會有所收獲,下面我們一起來看看吧。
今天在將 Hive 表同步到 MySQL 之后,其中有一列是唯一列,但是在 MySQL 中查詢的時候 count 與 distinct count 查詢出來的數值是不一樣的,這么來看的話是有重復的數據(按理說不應該的,因為在 Hive 中,這兩個數值是一樣的),那么將重復的數據查出來看了一下,發現是大小寫的問題,然后查了一下,發現 MySQL 數據庫默認情況下,字符串字段的所有相關運算是大小寫"不敏感"的。
這一點與其它流行的數據庫都不相同。
MySQL 允許在查詢的時候指定以大小寫敏感方式,需要使用關鍵字 BINARY,查詢如下:
SELECT * FROM student WHERE BINARY name = 'ZhangSan'; --或者 SELECT * FROM student WHERE name = BINARY 'ZhangSan';
很多時候當發現 MySQL 數據庫存在上述問題時,系統已經運行了一段時間,如果采用方法二或方法三的代價可能會很大。
使用此方法最大的好處便是可以快速實現功能。
但是這個方法也存在很大的限制:如此可能因為無法使用索引導致查詢性能下降。
原因很好理解,因為此時針對查詢字段的索引也是按照大小寫不敏感方式建立的。
除非數據量不大,或者在你的應用中不在乎這點性能上的損失,那么只能選擇方法二或方法三了。
在創建表時指定具體的字段大小寫敏感,示例如下:
CREATE TABLE student ( ... name VARCHAR(64) BINARY NOT NULL, ... )
關鍵字 BINARY 指定 name 字段大小寫敏感。
如此在查詢時就算不使用 BINARY 關鍵字,查詢語句也是大小寫敏感的。
在此基礎上創建的 name 相關的索引也是大小寫敏感的,也就能夠使用索引來提高性能。
MySQL 允許在大多數字符串類型上使用 BINARY 關鍵字,用于指明所有針對該字段的運算是大小寫敏感的,更多信息請參見 MySQL 官方文檔。
這種方法使得設計者可以精確地控制每個字段是否大小寫敏感。不過在很多系統的設計中,期望大部分甚至所有的字段統一大小寫敏感。MySQL 也提供了解決方案,這就要用到方法三。
在 MySQL 中執行 show create table <tablename> 指令,可以看到一張表的建表語句,example 如下:
CREATE TABLE `table1` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `field1` text COLLATE utf8_general_ci NOT NULL COMMENT '字段1', `field2` varchar(128) COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '字段2', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8_unicode_ci;
大部分字段我們都能看懂,但是今天要看的是 COLLATE 關鍵字。這個值后面對應的 utf8_general_ci 是什么意思呢?下面我們就來了解一下。
使用 Navicat 開發的可能會比較眼熟,因為其中的選項中已經給出了答案:
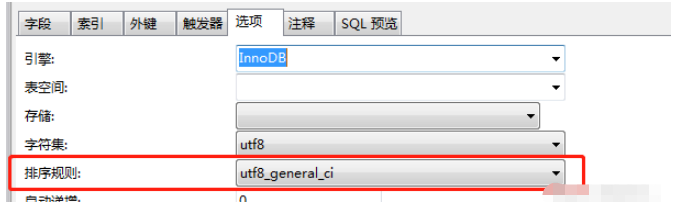
所謂 utf8_general_ci,其實是用來排序的規則。對于 MySQL 中那些字符類型的列,如VARCHAR,CHAR,TEXT 類型的列,都需要有一個 COLLATE 類型來告知 MySQL 如何對該列進行排序和比較。簡而言之,COLLATE 會影響到 ORDER BY 語句的順序,會影響到 WHERE 條件中大于小于號篩選出來的結果,會影響 DISTINCT、GROUP BY、HAVING 語句的查詢結果。另外,MySQL 建索引的時候,如果索引列是字符類型,也會影響索引創建,只不過這種影響我們感知不到。總之,凡是涉及到字符類型比較或排序的地方,都會和 COLLATE 有關。
涉及字符串的各種運算其核心必然涉及到采用何種字符排序規則(COLLATE,也有翻譯為"核對")。本質上 MySQL 是通過 COLLATE 取值決定字符串運算是否大小寫敏感。
utf8_general_ci 是一個具體的 COLLATE 取值。每個具體的 COLLATE 都對應唯一的字符集,可以看出該 COLLATE 對應字符集為 utf8。而與大小寫敏感問題相關的是其后綴 _ci,MySQL 官方文檔對其的解釋是 Case Ignore 的縮寫,即大小寫不敏感。由于 MySQL 將 utf8_general_ci 指定作為字符集 utf8 的默認 COLLATE,這也就導致文章開頭所說的現象。與此同時,MySQL 也提供了其它的 COLLATE 取值選項,utf8_bin 就是大小寫敏感的。事實上所有大小寫敏感的 COLLATE 都以 _bin或 _cs 為后綴,前者是 Binary 的縮寫,后者是 Case Sensitive 的縮寫。
COLLATE 通常是和數據編碼(CHARSET)相關的,一般來說每種 CHARSET 都有多種它所支持的 COLLATE,并且每種 CHARSET 都指定一種 COLLATE 為默認值。例如 Latin1 編碼的默認 COLLATE 為 latin1_swedish_ci,GBK 編碼的默認 COLLATE 為 gbk_chinese_ci,utf8mb4 編碼的默認值為 utf8mb4_general_ci。
這里順便講個題外話,MySQL 中有 utf8 和 utf8mb4 兩種編碼,在 MySQL 中請大家忘記 utf8,永遠使用 utf8mb4。這是 MySQL 的一個遺留問題,MySQL 中的 utf8 最多只能支持 3bytes 長度的字符編碼,對于一些需要占據 4bytes 的文字,MySQL 的 utf8 就不支持了,要使用 utf8mb4 才行。
很多 COLLATE 都帶有 _ci 字樣,這是 Case Insensitive 的縮寫,即大小寫無關,也就是說 "A" 和 "a" 在排序和比較的時候是一視同仁的。selection * from table1 where field1="a" 同樣可以把 field1 為 "A" 的值選出來。與此同時,對于那些 _cs 后綴的 COLLATE,則是 Case Sensitive,即大小寫敏感的。
在 MySQL 中使用 show collation 指令可以查看到 MySQL 所支持的所有 COLLATE。以 utf8mb4 為例,該編碼所支持的所有 COLLATE 如下圖所示。
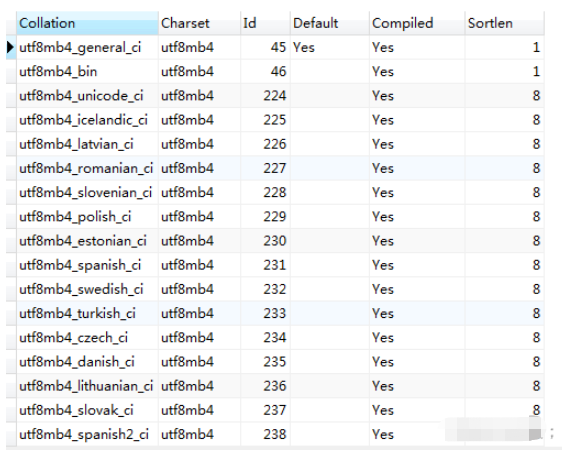
圖中我們能看到很多國家的語言自己的排序規則。在國內比較常用的是 utf8mb4_general_ci(默認)、utf8mb4_unicode_ci、utf8mb4_bin 這三個。我們來探究一下這三個的區別:
首先 utf8mb4_bin 的比較方法其實就是直接將所有字符看作二進制串,然后從最高位往最低位比對。所以很顯然它是區分大小寫的。
而 utf8mb4_unicode_ci 和 utf8mb4_general_ci 對于中文和英文來說,其實是沒有任何區別的。對于我們開發的國內使用的系統來說,隨便選哪個都行。只是對于某些西方國家的字母來說,utf8mb4_unicode_ci 會比 utf8mb4_general_ci 更符合他們的語言習慣一些,general 是 MySQL 一個比較老的標準了。例如,德語字母 "ß",在 utf8mb4_unicode_ci 中是等價于 "ss" 兩個字母的(這是符合德國人習慣的做法),而在 utf8mb4_general_ci 中,它卻和字母 "s" 等價。不過,這兩種編碼的那些微小的區別,對于正常的開發來說,很難感知到。本身我們也很少直接用文字字段去排序,退一步說,即使這個字母排錯了一兩個,真的能給系統帶來災難性后果么?從網上找的各種帖子討論來說,更多人推薦使用 utf8mb4_unicode_ci,但是對于使用了默認值的系統,也并沒有非常排斥,并不認為有什么大問題。結論:推薦使用 utf8mb4_unicode_ci,對于已經用了 utf8mb4_general_ci 的系統,也沒有必要花時間改造。
另外需要注意的一點是,從 MySQL 8.0 開始,MySQL 默認的 CHARSET 已經不再是 Latin1 了,改為了 utf8mb4 (參考鏈接),并且默認的 COLLATE 也改為了 utf8mb4_0900_ai_ci。utf8mb4_0900_ai_ci 大體上就是 unicode 的進一步細分,0900 指代 unicode 比較算法的編號( Unicode Collation Algorithm version),ai 表示 accent insensitive(發音無關),例如 e,è, é, ê 和 ë 是一視同仁的。相關參考鏈接1,相關參考鏈接2
MySQL 數據庫允許在庫、表 和 列 三個級別上指定 Collation。當同時指定時,優先關系是:列 > 表 > 庫。
設置 COLLATE 可以在實例級別、庫級別、表級別、列級別、以及 SQL 指定。當同時指定時,優先關系是:SQL 指定 > 列 > 表 > 庫 > 實例級別。
實例級別的 COLLATE 設置就是 MySQL 配置文件或啟動指令中的 collation_connection 系統變量。
庫級別設置 COLLATE 的語句如下:
CREATE DATABASE <db_name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
如果庫級別沒有設置 CHARSET 和 COLLATE,則庫級別默認的 CHARSET 和 COLLATE 使用實例級別的設置。在 MySQL 8.0 以下版本中,你如果什么都不修改,默認的 CHARSET 是 Latin1,默認的 COLLATE 是 latin1_swedish_ci。從 MySQL 8.0 開始,默認的 CHARSET 已經改為了 utf8mb4,默認的 COLLATE 改為了 utf8mb4_0900_ai_ci。
表級別的 COLLATE 設置,則是在 CREATE TABLE 的時候加上相關設置語句,例如:
CREATE TABLE table_name ( …… ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT = '表注釋';
如果表級別沒有設置 CHARSET 和 COLLATE,則表級別會繼承庫級別的 CHARSET 與 COLLATE。
列級別的設置,則在 CREATE TABLE 中聲明列的時候指定,例如
CREATE TABLE ( `field1` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '字段1', …… ) ……
如果列級別沒有設置 CHARSET 和 COLATE,則列級別會繼承表級別的 CHARSET 與 COLLATE。
最后,你也可以在寫 SQL 查詢的時候顯示聲明 COLLATE 來覆蓋任何庫表列的 COLLATE 設置,不太常用,了解即可:
SELECT DISTINCT field1 COLLATE utf8mb4_general_ci FROM table1; SELECT field1, field2 FROM table1 ORDER BY field1 COLLATE utf8mb4_unicode_ci;
如果全都顯示設置了,那么優先級順序是 SQL 語句 > 列級別設置 > 表級別設置 > 庫級別設置 > 實例級別設置。
也就是說列上所指定的 COLLATE可以覆蓋表上指定的 COLLATE,表上指定的 COLLATE 可以覆蓋庫級別的 COLLATE。如果沒有指定,則繼承下一級的設置。
即列上面沒有指定 COLLATE,則該列的 COLLATE 和表上設置的一樣。
以上就是關于 MySQL 的 COLLATE 相關知識。不過,在系統設計中,我們還是要盡量避免讓系統嚴重依賴中文字段的排序結果,在 MySQL 的查詢中也應該盡量避免使用中文做查詢條件。
關于“MySQL中存儲的數據查詢的時候怎么區分大小寫”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“MySQL中存儲的數據查詢的時候怎么區分大小寫”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





