溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“怎么用GAN訓練自己數據生成新的圖片”,內容詳細,步驟清晰,細節處理妥當,希望這篇“怎么用GAN訓練自己數據生成新的圖片”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
# MNIST dataset mnist = datasets.MNIST( root='./data/', train=True, transform=img_transform, download=True) # Data loader dataloader = torch.utils.data.DataLoader( dataset=mnist, batch_size=batch_size, shuffle=True)
可以看到,datasets.MNIST這個肯定不能用于我們自己的數據。我借鑒了原來做二分類的datasets.ImageFolder。
發現老是報錯:
RuntimeError: Found 0 files in subfolders of: E:\Projects\gan\battery\ng
Supported extensions are: .jpg,.jpeg,.png,.ppm,.bmp,.pgm,.tif,.tiff,.webp
后面單步調試,原來這個函數是需要文件夾下面有分類標簽的,根據子文件夾名生成分類標簽。
故放棄,只能自己寫了。
下面是參考網上的,寫了個讀取數據的函數:
import numpy as np
import torch
import os
import random
from PIL import Image
from torch.utils.data import Dataset
class myDataset(Dataset):
def __init__(self, data_dir, transform):
self.data_dir = data_dir
self.transform = transform
self.img_names = [name for name in list(filter(lambda x: x.endswith(".jpg"), os.listdir(self.data_dir)))]
def __getitem__(self, index):
path_img = os.path.join(self.data_dir, self.img_names[index])
img = Image.open(path_img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img
def __len__(self):
if len(self.img_names) == 0:
raise Exception("\ndata_dir:{} is a empty dir! Please checkout your path to images!".format(self.data_dir))
return len(self.img_names)解決了讀取數據之后,發現可以訓練了,因為參考鏈接的MINIST數據都是單通道的,我們大部分圖像都是3通道的,所以我將通道改為3后,發現判別器那塊老是報錯,標簽和數據不匹配。
RuntimeError: mat1 dim 1 must match mat2 dim 0
后面一查,發現問題出在這句上面:
for i, (imgs, _) in enumerate(dataloader)
這樣得到的imgs已經沒有batch-size的信息了,需要改為這樣:
for i, imgs in enumerate(dataloader):
下面是整個代碼塊,貼上去記錄下來,以便過段時間萬一忘了,還有個看的地方。
import argparse
import os
import numpy as np
import math
# import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets, models, transforms
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from tools.my_dataset import myDataset
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=2, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=4, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=128, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
print('cuda is',cuda)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# # Configure data loader
# os.makedirs("./data/mnist", exist_ok=True)
# dataloader = torch.utils.data.DataLoader(
# datasets.MNIST(
# "./data/mnist",
# train=True,
# download=True,
# transform=transforms.Compose(
# [transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
# ),
# ),
# batch_size=opt.batch_size,
# shuffle=True,
# )
dataset = r'E:\Projects\gan\battery'
ng_directory = os.path.join(dataset, 'ng')
ok_directory = os.path.join(dataset, 'ok')
image_transforms = {
'ng': transforms.Compose([
transforms.Resize([opt.img_size,opt.img_size]),
transforms.ToTensor(),
]),
'ok': transforms.Compose([
transforms.Resize([opt.img_size,opt.img_size]),
transforms.ToTensor(),
])}
data = {
'ng': myDataset(data_dir=ng_directory, transform=image_transforms['ng']),
'ok': myDataset(data_dir=ok_directory, transform=image_transforms['ok'])
}
dataloader = DataLoader(data['ng'], batch_size=opt.batch_size, shuffle=True)
ng_data_size = len(data['ng'])
ok_data_size = len(data['ok'])
print('train_size: {:4d} valid_size:{:4d}'.format(ng_data_size, ok_data_size))
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
# for i, (imgs, _) in enumerate(dataloader):
for i, imgs in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 3, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
aa = discriminator(gen_imgs)
g_loss = adversarial_loss(aa, valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
bb = discriminator(real_imgs)
real_loss = adversarial_loss(bb, valid)
# 此處需要注意,detach()是為了截斷梯度流,不計算生成網絡的損失,
# 因為d_loss包含了fake_loss,回傳的時候如果不做處理,默認會計算generator的梯度,
# 而這里只需要計算判別網絡的梯度,更新其權重值,生成網絡保持不變即可。
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
上面是原始圖片,下面是生成的圖片,從開始的噪聲,到慢慢有點樣子,還沒訓練完,由于我的顯卡比較小,GTX1660Ti,6G顯存,所以將原始圖片從800x800壓縮到了128x128,可能影響了效果,沒關系,后面還可以優化,包括將全連接網絡改為卷積的,圖片設置大點,等等。

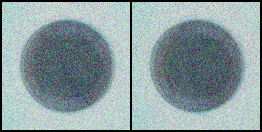
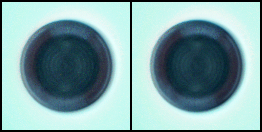
讀到這里,這篇“怎么用GAN訓練自己數據生成新的圖片”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





