溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“python內置堆如何實現”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
堆,又稱優先隊列,是一個完全二叉樹,它的每個父節點的值都只會小于或等于所有孩子節點(的值)。 它使用了數組來實現:從零開始計數,對于所有的 k ,都有 heap[k] <= heap[2k+1] 和 heap[k] <= heap[2k+2]。 為了便于比較,不存在的元素被認為是無限大。 堆最有趣的特性在于最小的元素總是在根結點:heap[0]。
python的堆一般都是最小堆,與很多教材上的內容有所不同,教材上大多以最大堆,由于堆的表示方法,從上到下,從左到右存儲,與列表十分相似,因此創建一個堆,可以使用list來初始化為 [] ,或者你可以通過一個函數 heapify() ,來把一個list轉換成堆。如下是python中關于堆的相關操作,從這可以看出,python確實是將堆看作是列表去處理的。
將 item 的值加入 heap 中,保持堆的不變性。會自動依據python中的最小堆特性,交換相關元素使得堆的根節點元素始終不大于子節點元素。
原有數據是堆
import heapq h = [1, 2, 3, 5, 7] heapq.heappush(h, 2) print(h) #輸出 [1, 2, 2, 5, 7, 3]
操作流程如下:
1.如下是初始狀態
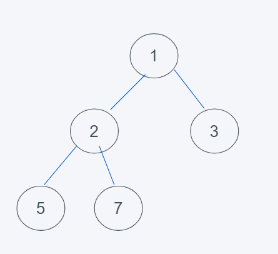
2.添加了2元素之后
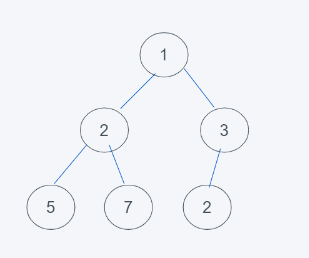
3.由于不符合最小堆的特性,因此與3進行交換
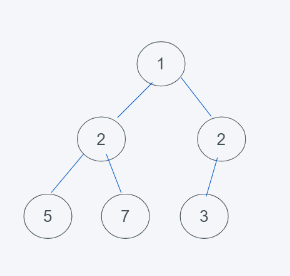
4.符合最小堆的特性,交換結束,因此結果是[1, 2, 3, 5, 7, 3]
原有數據不是堆
import heapq h = [5, 2, 1, 4, 7] heapq.heappush(h, 2) print(h) #輸出 [5, 2, 1, 4, 7, 2]
由此可見,當進行push操作時,元素不是堆的情況下,默認按照列表的append方法進行添加元素
彈出并返回 heap 的最小的元素,保持堆的不變性。如果堆為空,拋出 IndexError 。使用 heap[0] ,可以只訪問最小的元素而不彈出它。
原有數據是堆
import heapq h = [1, 2, 3, 5, 7] heapq.heappop(h) print(h) #輸出 [2, 5, 3, 7]
操作流程如下:
1.初始狀態
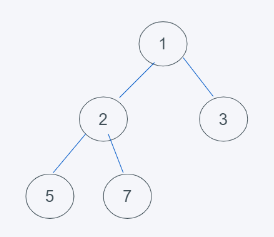
2.刪除了堆頂元素,末尾元素移入堆頂
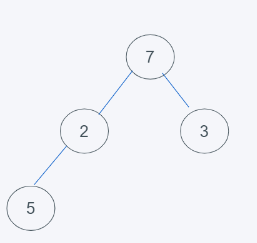
3.依據python最小堆的特性進行交換元素,由于7>2,交換7和2
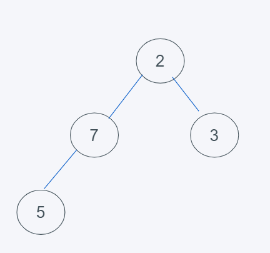
4.依據python最小堆的特性進行交換元素,由于7>5,交換7和5
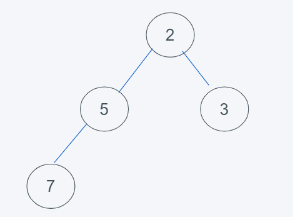
5.符合堆的要求,即結果為[2, 5, 3, 7]
原有數據不是堆
import heapq h = [5, 2, 1, 4, 7] heapq.heappop(h) print(h) [1, 2, 7, 4]
操作流程如下:
1.初始狀態,很明顯不符合堆的性質
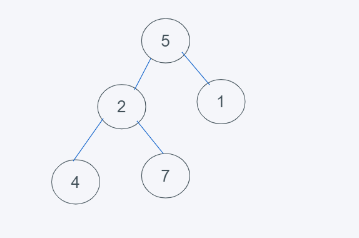
2.移除最上面的元素(第一個元素),重新對剩下的元素進行堆的排列
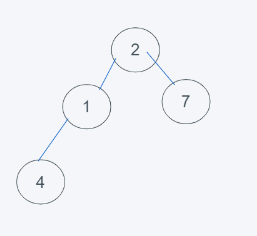
3.依據python最小堆的特性,2>1 交換2與1
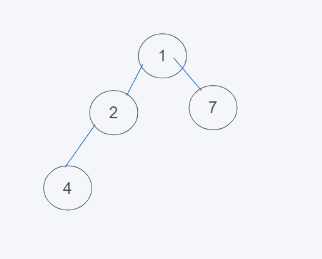
4.符合堆的要求,結果為[1, 2, 7, 4]
將 item 放入堆中,然后彈出并返回 heap 的最小元素。該組合操作比先調用 heappush() 再調用 heappop() 運行起來更有效率。需要注意的是彈出的元素必須位于堆頂或者堆尾,也就是說當插入一個元素后,進行比較最小元素時,其實一直比較的都是堆頂元素,如果插入元素大于或等于堆頂元素,則堆不會發生變化,當插入元素小于堆頂元素,則堆會依據python堆的最小堆特性進行處理。
原有數據是堆
import heapq h = [1, 2, 3, 5, 7] min_data = heapq.heappushpop(h, 2) print(min_data) print(h) #輸出 1 [2, 2, 3, 5, 7]
操作流程如下
1.初始狀態
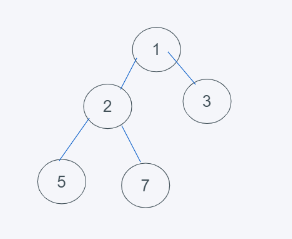
2.插入元素2
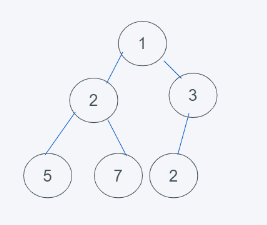
3.刪除最小元素,剛好是堆頂元素1,并使用末尾元素2代替
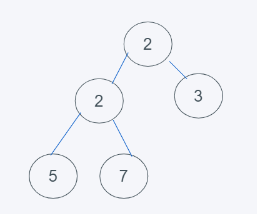
4.符合要求,即結果為[2, 2, 3, 5, 7]
原有數據不是堆
h = [5, 2, 1, 4, 7] min_data = heapq.heappushpop(h, 2) print(min_data) print(h) min_data = heapq.heappushpop(h, 6) print(min_data) print(h) #輸出 2 [5, 2, 1, 4, 7] 5 [1, 2, 6, 4, 7]
對于插入元素6的操作過程如下
1.初始狀態
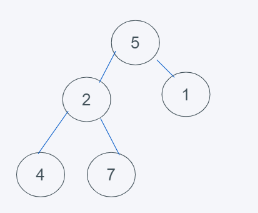
2.插入元素6之后
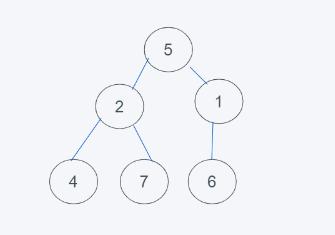
3.發現元素6大于堆頂元素5,彈出堆頂元素5,由堆尾元素6替換
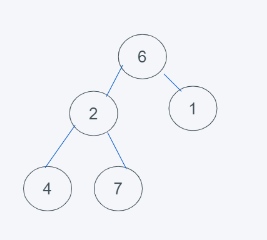
4.依據python的最小堆特性,元素6>元素1且元素6>元素2,但元素2>元素1, 交換6與1
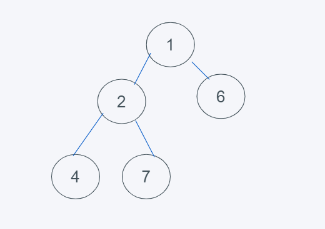
5.符合要求,則結果為[1, 2, 6, 4, 7]
由結果可以看出,當插入元素小于堆頂元素時,則堆不會發生改變,當插入元素大于堆頂元素時,則堆依據python堆的最小堆特性處理。
將列表轉換為堆。
h = [1, 2, 3, 5, 7] heapq.heapify(h) print(h) h = [5, 2, 1, 4, 7] heapq.heapify(h) print(h) #輸出 [1, 2, 3, 5, 7] [1, 2, 5, 4, 7]
會自動將列表依據python最小堆特性進行重新排列。
彈出并返回最小的元素,并且添加一個新元素item,這個單步驟操作比heappop()加heappush() 更高效。適用于堆元素數量固定的情況。
返回的值可能會比添加的 item 更大。 如果不希望如此,可考慮改用heappushpop()。 它的 push/pop 組合會返回兩個值中較小的一個,將較大的值留在堆中。
import heapq h = [1, 2, 3, 5, 7] heapq.heapreplace(h, 6) print(h) h = [5, 2, 1, 4, 7] heapq.heapreplace(h, 6) print(h) #輸出 [2, 5, 3, 6, 7] [1, 2, 6, 4, 7]
原有數據是堆
對于插入元素6的操作過程如下:
1.初始狀態
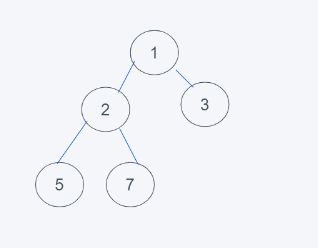
2.彈出最小元素,只能彈出堆頂或者堆尾的元素,很明顯,最小元素是1,彈出1,插入元素是6,代替堆頂元素
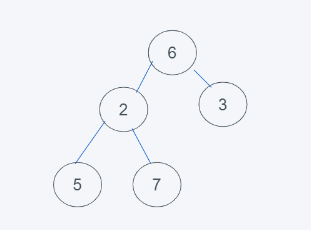
3.依據python堆的最小堆特性,6>2,交換6與2
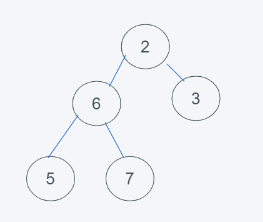
4.依據python堆的最小堆特性,6>5,交換6與5
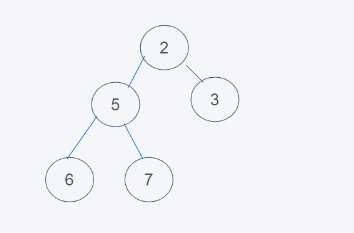
5.符合要求,則結果為[2, 5, 3, 6 ,7]
原有數據不是堆
對于插入元素6的操作過程如下:
1.初始狀態
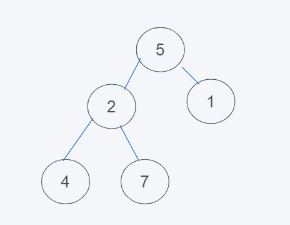
2.對于數據不為堆的情況下,默認移除第一個元素,這里就是元素5,然后插入元素6到堆頂
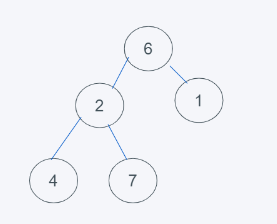
3.依據python的最小堆特性,元素6>1,交換元素6與1
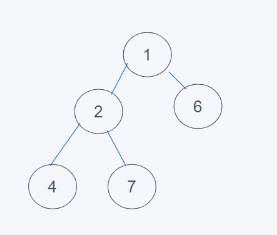
4.符合要求,即結果為[1, 2, 6, 4, 7
將多個已排序的輸入合并為一個已排序的輸出(例如,合并來自多個日志文件的帶時間戳的條目)。 返回已排序值的 iterator。注意需要是已排序完成的可迭代對象(默認為從小到大排序),當reverse為True時,則為從大到小排序。
從 iterable 所定義的數據集中返回前 n 個最大元素組成的列表。 如果提供了 key 則其應指定一個單參數的函數,用于從 iterable 的每個元素中提取比較鍵 (例如 key=str.lower)。
等價于: sorted(iterable, key=key, reverse=True)[:n]。
import time import heapq h = [1, 2, 3, 5, 7] size = 1000000 start = time.time() print(heapq.nlargest(3, h)) for i in range(size): heapq.nlargest(3, h) print(time.time() - start) start = time.time() print(sorted(h, reverse=True)[:3:]) for i in range(size): sorted(h, reverse=True)[:3:] print(time.time() - start) #輸出 [7, 5, 3] 1.6576552391052246 [7, 5, 3] 0.2772986888885498 [7, 5, 4]
由上述結構可見,heapq.nlargest與sorted(iterable, key=key, reverse=False)[:n]功能是類似的,但是性能方面還是sorted較為快速。
從 iterable 所定義的數據集中返回前 n 個最小元素組成的列表。 如果提供了 key 則其應指定一個單參數的函數,用于從 iterable 的每個元素中提取比較鍵 (例如 key=str.lower)。 等價于: sorted(iterable, key=key)[:n]。
import time import heapq h = [1, 2, 3, 5, 7] size = 1000000 start = time.time() print(heapq.nsmallest(3, h)) for i in range(size): heapq.nsmallest(2, h) print(time.time() - start) start = time.time() print(sorted(h, reverse=False)[:3:]) for i in range(size): sorted(h, reverse=False)[:2:] print(time.time() - start) #輸出 [1, 2, 3] 1.1738648414611816 [1, 2, 3] 0.2871997356414795
由上述結果可見,sorted的性能比后面兩個函數都要好,但如果只是返回最大的或者最小的一個元素,則使用max和min最好。
由于在python中堆的特性是最小堆,堆頂的元素始終是最小的,可以將序列轉換成堆之后,再使用pop彈出堆頂元素來實現從小到大排序。具體實現如下:
from heapq import heappush, heappop, heapify def heapsort(iterable): h = [] for value in iterable: heappush(h, value) return [heappop(h) for i in range(len(h))] def heapsort2(iterable): heapify(iterable) return [heappop(iterable) for i in range(len(iterable))] data = [1, 3, 5, 7, 9, 2, 4, 6, 8, 0] print(heapsort(data)) print(heapsort2(data)) #輸出 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
from heapq import heappush, heappop h = [] heappush(h, (5, 'write code')) heappush(h, (7, 'release product')) heappush(h, (1, 'write spec')) heappush(h, (3, 'create tests')) print(h) print(heappop(h)) [(1, 'write spec'), (3, 'create tests'), (5, 'write code'), (7, 'release product')] (1, 'write spec')
上述操作流程如下:
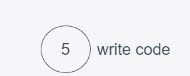
1.當進行第一次push(5, ‘write code’)時
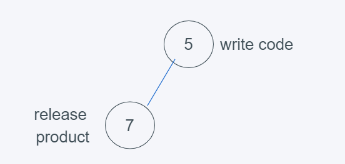
2.當進行第二次push(7, ‘release product’)時,符合堆的要求
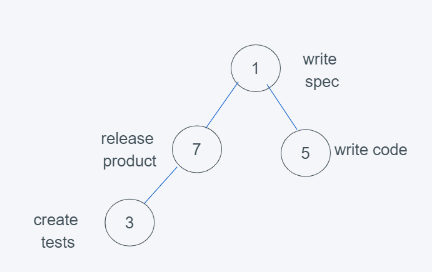
3.當進行第三次push(1, ‘write spec’)時,

4.依據python的堆的最小堆特性,5>1 ,交換5和1
5.當進行最后依次push(3, ‘create tests’)時
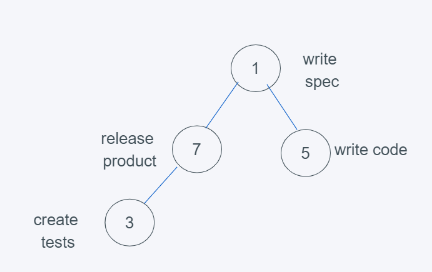
6.依據python堆的最小堆特性,7>3,交換7與3
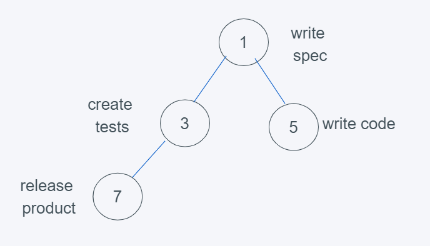
7.符合要求,因此結果為[(1, ‘write spec’), (3, ‘create tests’), (5, ‘write code’), (7, ‘release product’)],彈出元素則是堆頂元素,數字越小,優先級越大。
“python內置堆如何實現”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





