溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“ChatGPT最小元素的設計方法是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
上一節隨著我能抓openai的列表之后,我的野心開始膨脹,既然我們寫了一個框架,可以開始寫面向各網站的爬蟲了,為什么只面向ChatGPT呢?幾乎所有的平臺都是這么個模式,一個列表,然后逐個抓取。那我能不能把這個能力泛化呢?可不可以設計一套機制,讓所有的抓取功能都變得很簡單呢?我抽取一系列的基礎能力,而不管抓哪個網站只需要復用這些能力就可以快速的開發出爬蟲。公司內的各種平臺都是這么想的對吧?
那么我們就需要進行設計建模,如果按照正常的面向對象,我可能會這么設計建模:
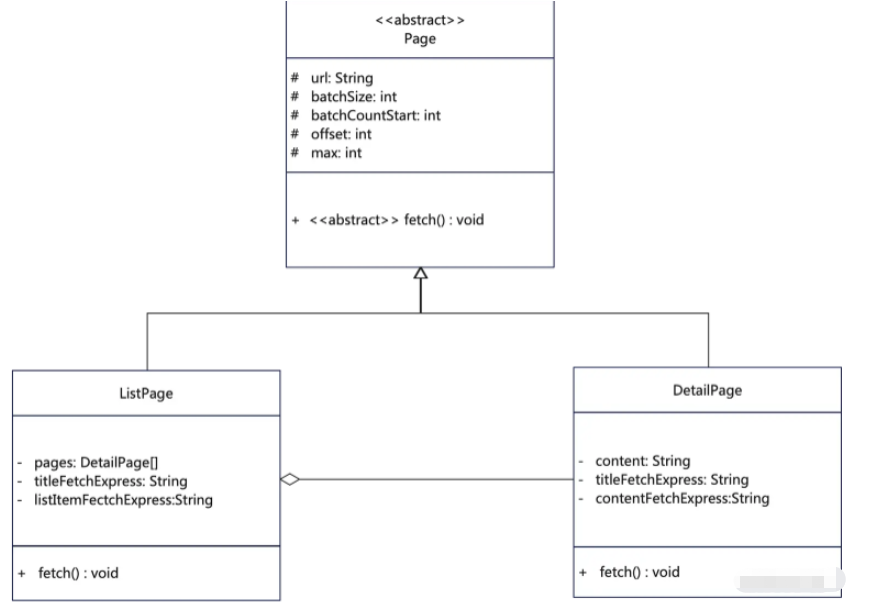
看起來很美好不是嗎?是不是可以按照設計去寫代碼了?其實完全是扯淡,魔鬼隱藏在細節中,每個網站都有各種復雜的HTML、他們可能是簡單的列表,也可能是存在好幾個iframe,而且你在界面上看到的列表和你真正點開的又不一樣,比如說:
有的小說網站,它的列表上假如有N個列表項,但是你真的點擊去之后,你會發現有的章節點擊他只有一半內容,再點下一頁的時候它會調到一個不在列表頁上的展示的頁面,展示后半段內容,而你如果只根據列表鏈接去抓,你會丟掉這后半段內容。
有的網站會在你點了幾個頁面后隨機出現一個按鈕,點擊了才能展開后續內容,防止機器抓取。你不處理這種情況,直接去抓就抓不全。
而有的網站根本就是圖片展示文本內容,你得把圖片搞下來,然后OCR識別,或者插入了各種看不見的文本需要被清洗掉。
而且每個網站還會升級換代,他們一升級換代,你的抓取方式也要跟著變。 等等等等……而且所有這些要素之間還可以排列組合:
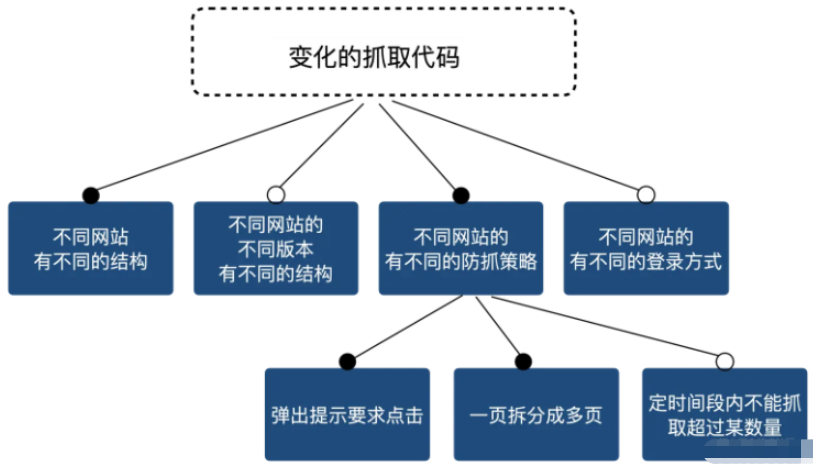
所以最上面的那個建模只能說過于簡化而沒有用處,起碼,以前是這樣的。
在以前,我們可能會進一步完善這個設計,得到一系列復雜的內部子概念、子機制、子策略,比如:
反防抓機制
詳情分頁抓取策略
清洗機制
然后對這些機制進行組合。
然而這并不會讓問題變簡單,人們總是低估膠水代碼的復雜度,最終要么整個體系非常脆弱,要么就從膠水處開始腐化。
那么在今天,我們有沒有什么新的做法呢?我們從一個代碼示例開始講起,比如,我這里有一個抓取某小說網站的代碼:
const fs = require('fs/promises');
async function main() {
const novel_section_list_url = 'https://example.com/list-1234.html';
await driver.goto(novel_section_list_url);
const novelSections = await driver.evaluate(() => {
let title = getNovelTitle(document)
let section_list = getNovelSectionList(document);
return {
title, section_list
}
function getNovelTitle(document) {
return document.querySelector("h2.index_title").textContent;
}
function getNovelSectionList(document) {
let result = [];
document.querySelectorAll("ul.section_list>li>a").forEach(item => {
const { href } = item;
const name = item.textContent;
result.push({ href, name });
});
return result;
}
});
console.log(novelSections.section_list.length);
const batchSize = 50;
const title = novelSections.title;
let section_list = novelSections.section_list;
if (intention.part_fetch) {
section_list = novelSections.section_list.slice(600, 750);
}
await batchProcess(section_list, batchSize, async (one_batch, batchNumber) => {
await download_one_batch_novel_content(one_batch, driver);
async function download_one_batch_novel_content(one_batch, driver) {
let one_text_file_content = "";
for (section of one_batch) {
await driver.goto(section.href);
await driver.waitForTimeout(3000);
const section_text = await driver.evaluate(() => {
return "\n\n" + document.querySelector("h2.chapter_title").textContent
+ "\n"
+ document.querySelector("#chapter_content").textContent;
});
one_text_file_content += section_text;
}
await fs.writeFile(`./output/example/${title}-${batchNumber}.txt`, one_text_file_content);
}
});
}
main().then(() => { });
async function batchProcess(list, batchSize, asyncFn) {
const listCopy = [...list];
const batches = [];
while (listCopy.length > 0) {
batches.push(listCopy.splice(0, batchSize));
}
let batchNumber = 12;
for (const batch of batches) {
await asyncFn(batch, batchNumber);
batchNumber++;
}
}在實際工作中這樣的代碼應該是比較常見的,由于上述的設計沒有什么用處,我們經常見到的就是另一個極端,那就是代碼寫的過于隨意,整個代碼的實現變得無法閱讀,當我想要做稍微地調整,比如說我昨天抓了100個,今天接著從101個往后抓,就要去讀代碼,然后從代碼中看改點什么好讓這個抓取可以從101往后抓。
那在以前呢,我們就要像上面說的要設計比較精密的機制,而越是精密的機制,就越不健壯。而且,以我的經驗,你想讓人們使用那么精細的機制也不好辦,因為大多數人的能力并不足以駕馭精細的機制。
而在今天,我們可以做的更粗放一些。
首先,我們意識到有些代碼,準確的說,是有些變量,是我們經常修改的,所以我們在不改變整體結構的情況下,我們把這些變量提到上面去,變成一個變量:
//意圖描述
const intention = {
list_url:'https://example.com/list-1234.html',
batchSize: 50,
batchStart: 12,
page_waiting_time: 3000,
part_fetch:{ //如果全抓取,就注釋掉整個part_fetch屬性
from:600,//不含該下標
to:750
},
output_folder: "./output/example"
}
const fs = require('fs/promises');
const driver = require('../util/driver.js');
async function main() {
const novel_section_list_url = intention.list_url;
await driver.goto(novel_section_list_url);
const novelSections = await driver.evaluate(() => {
let title = getNovelTitle(document)
let section_list = getNovelSectionList(document);
return {
title, section_list
}
function getNovelTitle(document) {
return document.querySelector("h2.index_title").textContent;
}
function getNovelSectionList(document) {
let result = [];
document.querySelectorAll("ul.section_list>li>a").forEach(item => {
const { href } = item;
const name = item.textContent;
result.push({ href, name });
});
return result;
}
});
console.log(novelSections.section_list.length);
const batchSize = intention.batchSize;
const title = novelSections.title;
let section_list = novelSections.section_list;
if (intention.part_fetch) {
section_list = novelSections.section_list.slice(intention.part_fetch.from, intention.part_fetch.to);
}
await batchProcess(section_list, batchSize, async (one_batch, batchNumber) => {
await download_one_batch_novel_content(one_batch, driver);
async function download_one_batch_novel_content(one_batch, driver) {
let one_text_file_content = "";
for (section of one_batch) {
await driver.goto(section.href);
await driver.waitForTimeout(intention.page_waiting_time);
const section_text = await driver.evaluate(() => {
return "\n\n" + document.querySelector("h2.chapter_title").textContent
+ "\n"
+ document.querySelector("#chapter_content").textContent;
});
one_text_file_content += section_text;
}
await fs.writeFile(`${intention.output_folder}/${title}-${batchNumber}.txt`, one_text_file_content); //一個批次一存儲
}
});
}
main().then(() => { });
async function batchProcess(list, batchSize, asyncFn) {
const listCopy = [...list];
const batches = [];
while (listCopy.length > 0) {
batches.push(listCopy.splice(0, batchSize));
}
let batchNumber = intention.batchStart;
for (const batch of batches) {
await asyncFn(batch, batchNumber);
batchNumber++;
}
}于是我們把程序分成了兩部分結構:

接下來我會發現,在網站不變的情況下,下面這個意圖執行代碼相當的穩定。我經常需要做的不管是偏移量的計算,還是修改抓取目標等等,這些都只需要修改上面的意圖描述數據結構即可。而且我們可以做進一步的封裝,得到下面的代碼(下面的JsDoc也是ChatGPT給我寫的):
/**
* @typedef {Object} Intention
* @property {string} list_url
* @property {integer} batchSize
* @property {integer} batchStart
* @property {integer} page_waiting_time
* @property {PartFetch} part_fetch 如果全抓取,就注釋掉整個part_fetch屬性
* @property {string} output_folder
*
* @typedef {Object} PartFetch
* @property {integer} from 不含該下標
* @property {integer} batchStart
*/
//意圖執行
/**
* @param {Intention} intention
*/
module.exports = (intention, context) => {
Object.assign(this, context);
const {fs,console} = context;
async function main() {
const novel_section_list_url = intention.list_url;
await driver.goto(novel_section_list_url);
const novelSections = await driver.evaluate(() => {
let title = getNovelTitle(document)
let section_list = getNovelSectionList(document);
return {
title, section_list
}
function getNovelTitle(document) {
return document.querySelector("h2.index_title").textContent;
}
function getNovelSectionList(document) {
let result = [];
document.querySelectorAll("ul.section_list>li>a").forEach(item => {
const { href } = item;
const name = item.textContent;
result.push({ href, name });
});
return result;
}
});
console.log(novelSections.section_list.length);
const batchSize = intention.batchSize;
const title = novelSections.title;
// const section_list = novelSections.section_list.slice(0, 3);
let section_list = novelSections.section_list;
if (intention.part_fetch) {
section_list = novelSections.section_list.slice(intention.part_fetch.from, intention.part_fetch.to);
}
await batchProcess(section_list, batchSize, async (one_batch, batchNumber) => {
await download_one_batch_novel_content(one_batch, driver);
async function download_one_batch_novel_content(one_batch, driver) {
let one_text_file_content = "";
for (section of one_batch) {
await driver.goto(section.href);
await driver.waitForTimeout(intention.page_waiting_time);
const section_text = await driver.evaluate(() => {
return "\n\n" + document.querySelector("h2.chapter_title").textContent
+ "\n"
+ document.querySelector("#chapter_content").textContent;
});
one_text_file_content += section_text;
}
await fs.writeFile(`${intention.output_folder}/${title}-${batchNumber}.txt`, one_text_file_content); //一個批次一存儲
}
});
}
main().then(() => { });
async function batchProcess(list, batchSize, asyncFn) {
const listCopy = [...list];
const batches = [];
while (listCopy.length > 0) {
batches.push(listCopy.splice(0, batchSize));
}
let batchNumber = intention.batchStart;
for (const batch of batches) {
await asyncFn(batch, batchNumber);
batchNumber++;
}
}
}于是我們就有了一個穩定的接口將意圖的描述和意圖的執行徹底分離,隨著我對我的代碼進行了進一步的整理后發現,這個意圖描述結構竟然相當的通用,我寫的好多網站的抓取代碼竟然都可以抽取出這樣一個結構。 于是我們可以進一步抽象,到了一種適用于我特定領域的DSL,類似下面的結構:
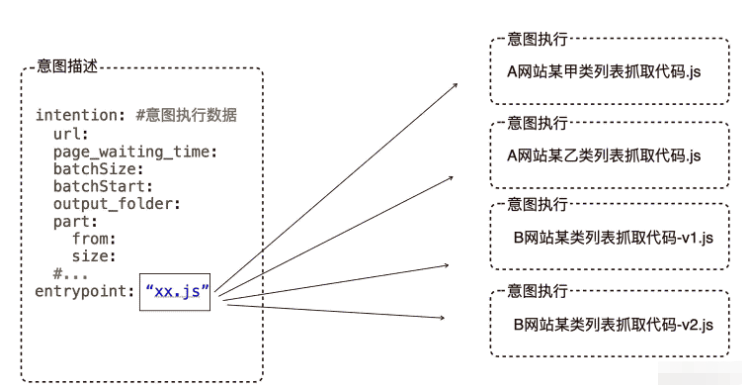
到此為止,我的意圖描述和意圖執行徹底解耦,意圖執行變成了意圖描述中的一個屬性,我只需要寫一個引擎,根據意圖描述中entrypoint的屬性值,加載對應的函數,然后將意圖數據傳給他就可以了,大概的代碼如下:
const intentionString = await fs.readFile(templatePath, 'utf8'); const intention = yaml.load(intentionString); const intention_exec = require(intention.entrypoint); intention_exec(intention, context);
而我們的每一個意圖執行的代碼,可以有自己的不同變化原因,不管是網站升級了,還是我們要抓下一個網站了,我們只需要把HTML扔給ChatGPT,他就可以幫我們生成對應的意圖執行代碼。哪怕我們想基于一些可以復用庫函數,比如之前說的反防抓、反詳情頁分頁機制封裝的庫函數,他也可以給我們生成膠水代碼把這些函數粘起來(具體的手法我們在后續的文章里講),所有這一切的變化,都可以用ChatGPT生成代碼這一步解決。那么所謂的在膠水層腐化的問題也就不存在了。
很有趣的是,在我基于該結構的DSL得到一組實例之后,我很快就開始產生了在DSL這一層的新需求,比如:
DSL文件的管理需求,因為人總是很懶的,而且我只有業余時間寫點這些東西,不能保證自己一直記得哪個網站對應哪個文件,然后怎么設置。
我還希望能夠根據我本地已經抓的內容和智能生成偏移量
我也希望能定時去查看更新然后生成抓取意圖。
這一切都是很有價值的需求,而如果我們沒有一個穩定的下層DSL結構,我們這些更上層需求也注定是不穩定的。
而有了這個穩定的DSL結構后,我們回過頭來看我們的設計,其實是在更大的尺度上實現了面向對象設計中的開閉原則,盡管擴展需要大量的代碼,而這些代碼卻并不需要人來寫,所以效率依然很高。
“ChatGPT最小元素的設計方法是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





