溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“數據庫的嵌套查詢的性能問題怎么解決”,內容詳細,步驟清晰,細節處理妥當,希望這篇“數據庫的嵌套查詢的性能問題怎么解決”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
explain 是非常重要的性能查詢的工具!!!
首先大家都知道我們一般不提倡嵌套查詢或是join查詢
原因在哪呢?
下面是一個簡單地嵌套查詢
SELECT id ,name ,age FROM teacher WHERE status=0 and name IN ( SELECT name FROM student WHERE age >18 )
我們一開始設想的是先執行內部查詢,然后再執行外部查詢的。
這是我們美好的愿景。
這個時候我們就可以使用explain來看一下這條語句的執行過程是怎樣的
+------+--------------+-------------+--------+---------------+--------------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+--------------+-------------+--------+---------------+--------------+---------+------+------+-------------+ | 1 | PRIMARY | teacher | ALL | NULL | NULL | NULL | NULL |65712| Using where | | 1 | PRIMARY | <subquery2> | eq_ref | distinct_key | distinct_key | 4 | func | 1 | | | 2 | DEPENDENT SUBQUERY| student | ALL | NULL | NULL | NULL | NULL | 418 | Using where |
這里可以看到student表的select_type是DEPENDENT SUBQUERY
DEPENDENT SUBQUERY是什么意思呢?
翻譯就是依靠外層查詢
簡而言之就是student內層查詢要依靠外層查詢
如上面顯示,teacher表中關聯行數是65712
那就意味著內層查詢要執行6萬次之多,肯定會很慢的。
但也不是所有的嵌套的select_type都是DEPENDENT SUBQUERY
比如還有MATERIALIZED類型,他就是sql自己進行的優化,他會在第一次進行子查詢的時候建立一個臨時表,保證后續查詢的速度。
join連接也是類似的,聯表查詢時,會有一個驅動表來作為原始數據的循環表。
如果使用的是left join那么左表就是這個驅動表,反之亦然
我們要盡量用小表來當做驅動表。如果實在不能判斷哪個比較合適就用join讓mysql來幫你做選擇,他會自動選擇一個小表來做驅動表。
1、首先,最直接簡單地方法就是不使用嵌套查詢。
使用多個單個的查詢來代替嵌套查詢
2、其次,我們還可以使用臨時表進行簡單地嵌套查詢
SELECT id ,name ,age FROM teacher t, (SELECT name FROM student WHERE age>18) s WHERE t.status=0 and t.name=s.name )
我在做報表的時候遇到一個問題,想了很長時間沒有解決,后來轉換思路一下子就解決了。具體問題是這樣的,我們公司有一張行業表,總共有四級行業需要維護,具體包括一級行業、二級行業、三級行業和四級行業,每個行業之間又存在包含關系,比如四級行業包含于三級行業,三級行業包含于二級行業,二級行業包含于一級行業,最詭異的地方就是我們把這么多信息放在一張表里維護,只不過額外加了兩個字段以示區分,一個是行業等級,一個是父行業,具體的表結構如下:
| 行業ID | 行業等級 | 父行業ID |
|---|---|---|
| 二級行業 | 二級 | 一級行業 |
| 三級行業1 | 三級 | 二級行業 |
| 三級行業2 | 三級 | 二級行業 |
| 四級行業1 | 四級 | 三級行業1 |
| 四級行業2 | 四級 | 三級行業2 |
最后的需求是有另外一張表,是用四級行業劃分的,其中有一項費用,最后需要按一級行業統計每個行業的費用。
根據實際業務,為了說明這個問題,筆者在這里做了一個模型簡化,假設我們只有兩張表tb_cls和tb_cost,tb_cls包含行業id,行業等級cls,父行業p_id,所有行業(包括一級、二級、三級行業都保存在這張表里)都包含在內,具體創建出來的表如下(為了讀者閱讀方便,這里做了一個簡化:id前面的第一位數代表一級行業編碼,例如121表示屬于一級大行業;整個id的位數代表幾級行業,例如211總共三位表示三級行業):
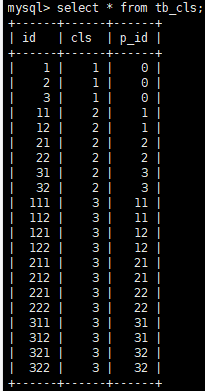
另外一張表,我也做了簡化,只提取其中用到的行業id和費用兩個字段,具體的表內容如下:
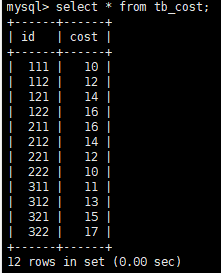
我們現在的任務有兩個:
第一、建立三級行業跟一級行業一一對應關系;
第二、按一級行業統計費用。
彎路:
最開始的思路是嵌套,就是根據現實世界的邏輯關系一層一層建立聯系,SELECT * FROM tb WHERE id IN(SELECT * FROM tb WHERE),沿著這個思路嘗試了很多,首先在SELECT外層聲明的變量內層的嵌套識別不了,內外層建立的變量不能相互訪問,另外一個這種建立起來的關系,沒有一一對應關系,因為我們用的是IN,最終只要存在就可以,所以沒有嚴格的一一對應關系。具體思路如下:
1.1 第1層:
SELECT id FROM tb_cost
1.2 第2層:
SELECT p_id FROM tb_cls WHERE id IN(SELECT id FROM tb_cost) AND cls=3
1.3 第3層:
SELECT p_id FROM tb_cls WHERE id IN(SELECT p_id FROM tb_cls WHERE id IN(SELECT id FROM tb_cost) AND cls=3) AND cls=2
1.4 第4層(最終):
SELECT t1.id,t2.id FROM tb_cls AS t1,tb_cost AS t2 WHERE t1.id IN(SELECT p_id FROM tb_cls WHERE id IN(SELECT p_id FROM tb_cls WHERE id IN(SELECT id FROM tb_cost) AND cls=3) AND cls=2)AND cls=1;
最終查詢的結果如下:
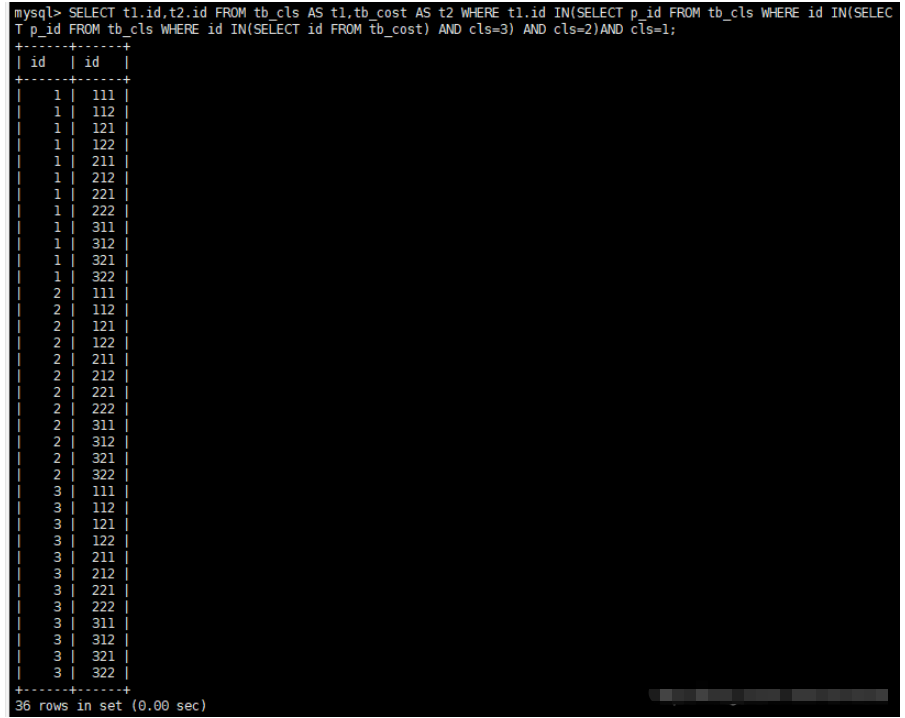
發現那里不對了沒有,每個一級行業下面包含所有的三級行業,所以這種嵌套方式走不通,同時進一步深入下去研究發現嵌套內外層定義的變量是不能相互交互的,什么意思呢?
SELECT t1.id, var_1 FROM t1 WHERE p_id IN(SELECT id AS var_1 FROM t1)var_1變量在內層那個SELECT是不可用的。
新思路:
基于上面的彎路,筆者換了一個,假設我們有3張一模一樣的表,通過這3張不同的表來區分各自的邏輯關系,把這3張表看成不同的表,一個個添加條件,具體思路如下:
2.1 第1層:tb_cls(AS t3)三級行業跟tb_cost(AS t4)建立關聯:t3.id=t4.id AND t3.cls=3
2.2 第2層:tb_cls(AS t2)二級行業跟tb_cls(AS t3)建立關聯:t3.p_id=t2.id AND t2.cls=2
2.3 第3層:tb_cls(AS t1)一級行業跟tb_cls(AS t2)建立關聯:t2.p_id=t1.id AND t1.cls=1
最終,建立起來的三級行業對應一級行業的對應關系如下:
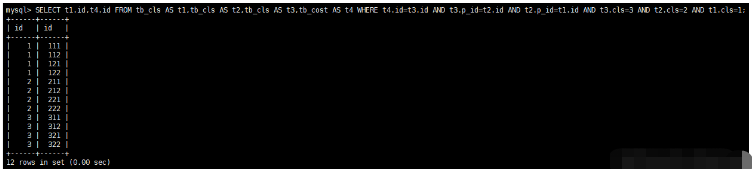
SELECT t1.id,t4.id FROM tb_cls AS t1,tb_cls AS t2,tb_cls AS t3,tb_cost AS t4 WHERE t4.id=t3.id AND t3.p_id=t2.id AND t2.p_id=t1.id AND t3.cls=3 AND t2.cls=2 AND t1.cls=1;
查詢結果如下,跟我們實際建立的情況一致,第一個任務(第一、建立三級行業跟一級行業一一對應關系)完成。
解決了第一個任務,第二個任務就簡單多了,其實就是按照一級行業id加個GROUP BY,分一下組就可以,
具體語句如下:
SELECT t1.id,SUM(t4.cost) FROM tb_cls AS t1,tb_cls AS t2,tb_cls AS t3,tb_cost AS t4 WHERE t4.id=t3.id AND t3.p_id=t2.id AND t2.p_id=t1.id AND t3.cls=3 AND t2.cls=2 AND t1.cls=1 GROUP BY t1.id;
查詢結果如下,簡單計算一下一級、二級、三級費用是不是查詢出來的值,至此,任務二也圓滿完成。

總之,當我們需要解決SQL語句的查詢任務的時候,不要一味的選擇深奧的技術、邏輯復雜的語言去解決(像筆者這里用多層嵌套,最后把自己繞進去了。)首先我們要做的是簡化邏輯,能通過簡單的思路解決復雜的問題本身也是一種能力,在這個基礎上然后基于性能、需求、業務慢慢再繼續優化SQL才是我們應該做的。
讀到這里,這篇“數據庫的嵌套查詢的性能問題怎么解決”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





