溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Groovy的規則腳本引擎怎么應用”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
互聯網時代隨著業務的飛速發展,迭代和產品接入的速度越來越快,需要一些靈活的配置。
辦法通常有如下幾個方面:
1、最為傳統的方式是java程序直接寫死提供幾個可調節的參數配置然后封裝成為獨立的業務模塊組件,在增加參數或簡單調整規則后,重新調上線。
2、使用開源方案,例如drools規則引擎,此類引擎適合業務較復雜的系統
3、使用動態腳本引擎:groovy,simpleEl,QLExpress
引入規則腳本對業務進行抽象可以大大提升效率,例如:
在貸款審核系統中,貸款的訂單在收單后會經過多個流程扭轉:收單后需要根據風控系統給出結果決定訂單的流程,而不同的產品訂單的扭轉是不一致的,每接入一個新產品,碼農都要寫一堆對于此產品的流程邏輯;現有的產品規則也經常需要更換。
所以想利用腳本引擎動態解析執行,到使用規則腳本將流程的扭轉抽象出來,提升效率
groovy的優勢:
1.歷史悠久,使用范圍大,坑少
2.和java兼容性強:可以無縫銜接,即使不懂groovy語法也沒有關系
3.語法糖
4.項目周期短,上線時間急
項目流轉的抽象:
因為不同的業務在流轉的過程中對于邏輯處理是不一致的,我們先考慮一種簡單的情況:
本身的項目在業務上會對不同的貸款訂單進行流程扭轉,例如訂單可以從流程a扭轉到流程b或者流程c,取決于每一個Strategy unit(策略單位)的執行情況:每個strategy unit執行后都會返回一個boolean值,具體邏輯可以自己定義,在這里我們假設:如果滿足所有的strategy unit a的條件(既每個執行單元都返回true),那么訂單就會扭轉到Scenario B;如果滿足所有的strategy unit b的條件那么訂單就會扭轉到scenario c。
那為什么要設計成多個strategy unit呢?是因為我的項目中,為了方便配置,將整個流程的strategyunit的配置展示在ui上,可讀性強,修改時也只需要修改某一個unit中的執行邏輯
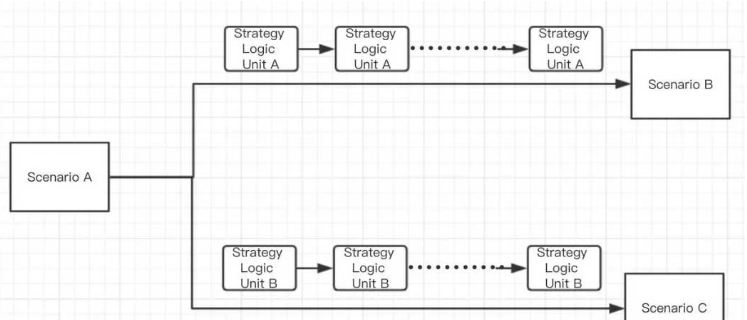
每個strategy unit執行時依賴的數據我們可以抽象成為一個context,context中包含兩部分數據:
一部分是業務上的數據:例如訂單的產品,訂單依賴的風控數據等
一部分是規則執行的數據:包括當前執行的node、所屬的策略組信息、當前的流程、下一個流程等
這一部分規則引擎執行數據的context可以根據不同的業務進行設計,設計時主要考慮斷點重跑,策略組等:比如可以設計不同的策略組與產品進行關聯,這一部分業務耦合性比較大,本文主要focus在groovy上
可以把Context理解為Strategy Unit的輸入和輸出,Strategy Unit在Groovy中進行執行,我們可以對每一個執行的Strategy Unit進行可配置化的展示和配置。執行過程中可以根據context中含有的不同的信息進行邏輯判斷,也可以改變context對象中的值。
基于上面的設計,groovy腳本的執行本質上只是接受context對象,并且基于context對象中的關鍵信息進行邏輯判斷,輸出結果,而結果也保存在context中。
先看看Groovy與java集成的方式:
用 Groovy 的 GroovyClassLoader ,它會動態地加載一個腳本并執行它。GroovyClassLoader是一個Groovy定制的類裝載器,負責解析加載Java類中用到的Groovy類。
GroovyShell允許在Java類中(甚至Groovy類)求任意Groovy表達式的值。您可使用Binding對象輸入參數給表達式,并最終通過GroovyShell返回Groovy表達式的計算結果。
GroovyShell多用于推求對立的腳本或表達式,如果換成相互關聯的多個腳本,使用GroovyScriptEngine會更好些。GroovyScriptEngine從您指定的位置(文件系統,URL,數據庫,等等)加載Groovy腳本,并且隨著腳本變化而重新加載它們。如同GroovyShell一樣,GroovyScriptEngine也允許您傳入參數值,并能返回腳本的值。
現在我們以GroovyClassLoader為例,展示一下如何實現與java的集成:
例如:我們假設申請金額大于20000的訂單進入流程B
1.在SpringBoot項目中maven中引入
<dependency> <groupId>org.codehaus.groovy</groupId> <artifactId>groovy-all</artifactId> <version>2.4.10</version> </dependency>
2.定義groovy執行的java接口
public interface EngineGroovyModuleRule {
boolean run(Object context);
}3.抽象出一個Groovy模板文件,放在resource下面以便加載:
import com.groovyexample.groovy.*
class %s implements EngineGroovyModuleRule {
boolean run(Object context){
%s //業務執行邏輯:可配置化
}
}4.解析groovy的模板文件,可以將模板文件緩存起來,解析通過spring的PathMatchingResourcePatternResolver進行
下面的Strategy Unit這個String就是具體的業務規則的邏輯,把這一部分的邏輯進行一個配置化
//解析Groovy模板文件
ConcurrentHashMap<String,String> concurrentHashMap = new ConcurrentHashMap(128);
final String path = "classpath*:*.groovy_template";
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
Arrays.stream(resolver.getResources(path))
.parallel()
.forEach(resource -> {
try {
String fileName = resource.getFilename();
InputStream input = resource.getInputStream();
InputStreamReader reader = new InputStreamReader(input);
BufferedReader br = new BufferedReader(reader);
StringBuilder template = new StringBuilder();
for (String line; (line = br.readLine()) != null; ) {
template.append(line).append("\n");
}
concurrentHashMap.put(fileName, template.toString());
} catch (Exception e) {
log.error("resolve file failed", e);
}
});
String scriptBuilder = concurrentHashMap.get("ScriptTemplate.groovy_template");
String scriptClassName = "testGroovy";
//這一部分String的獲取邏輯進行可配置化
String StrategyLogicUnit = "if(context.amount>=20000){\n" +
" context.nextScenario='A'\n" +
" return true\n" +
" }\n" +
" ";
String fullScript = String.format(scriptBuilder, scriptClassName, StrategyLogicUnit); GroovyClassLoader classLoader = new GroovyClassLoader();
Class<EngineGroovyModuleRule> aClass = classLoader.parseClass(fullScript);
Context context = new Context();
context.setAmount(30000);
try {
EngineGroovyModuleRule engineGroovyModuleRule = aClass.newInstance();
log.info("Groovy Script returns:{} "+engineGroovyModuleRule.run(context));
log.info("Next Scenario is {}"+context.getNextScenario());
}
catch (Exception e){
log.error("error...")
}5.執行上述代碼:
Groovy Script returns: true Next Scenario is A
關鍵的部分是Strategy Unit這個部分的可配置化,我們是通過管理端UI上展示不同產品對應的StrategyLogicUnit,并可進行CRUD,為了方便配置同時引進了策略組、產品策略復制關聯、一鍵復制模板等功能。
項目在測試時就發現隨著收單的數量增加,進行頻繁的Full GC,測試環境復現后查看日志顯示:
[Full GC (Metadata GC Threshold) [PSYoungGen: 64K->0K(43008K)]
[ParOldGen: 3479K->3482K(87552K)] 3543K->3482K(130560K),
[Metaspace: 15031K->15031K(1062912K)], 0.0093409 secs]
[Times: user=0.03 sys=0.00, real=0.01 secs]
日志中可以看出是mataspace空間不足,并且無法被full gc回收。 通過JVisualVM可以查看具體的情況:

發現class太多了,有2326個,導致metaspace滿了。我們先回顧一下metaspace ##metaspace和permgen 這是jdk在1.8中才有的東西,并且1.8講將permgen去除了,其中的方法區移到non-heap中的Metaspace。
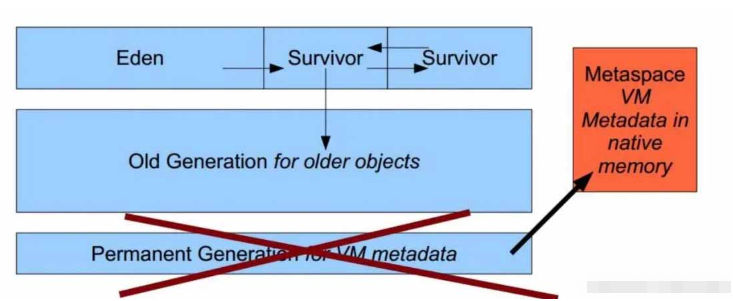
這個區域主要存放:存儲類的信息、常量池、方法數據、方法代碼等。 分析主要問題有兩方面:
問題1:Class數量問題:可能是引入groovy導致加載的類過多了,但實際上項目只配置了10個StrategyLogicUnit,不同的訂單執行同一個StrategyLogicUnit時應該對應同一個class。class的數量過于異常。
問題2:就算Class數量過多,Full GC為何沒有辦法回收?
我們先分析Groovy執行的過程,最關鍵的代碼是如下幾部分:
GroovyClassLoader classLoader = new GroovyClassLoader(); Class<EngineGroovyModuleRule> aClass = classLoader.parseClass(fullScript); EngineGroovyModuleRule engineGroovyModuleRule = aClass.newInstance(); engineGroovyModuleRule.run(context)
GroovyClassLoader是一個定制的類裝載器,在代碼執行時動態加載groovy腳本為java對象。
大家都知道classloader的雙親委派,我們先來分析一下這個GroovyClassloader,看看它的祖先分別是啥:
def cl = this.class.classLoader
while (cl) {
println cl
cl = cl.parent
}輸出:
groovy.lang.GroovyClassLoader$InnerLoader@13322f3
groovy.lang.GroovyClassLoader@127c1db
org.codehaus.groovy.tools.RootLoader@176db54
sun.misc.Launcher$AppClassLoader@199d342
sun.misc.Launcher$ExtClassLoader@6327fd
從而得出:
Bootstrap ClassLoader
↑
sun.misc.Launcher.ExtClassLoader // 即Extension ClassLoader
↑
sun.misc.Launcher.AppClassLoader // 即System ClassLoader
↑
org.codehaus.groovy.tools.RootLoader // 以下為User Custom ClassLoader
↑
groovy.lang.GroovyClassLoader
↑
groovy.lang.GroovyClassLoader.InnerLoader
查看關鍵的GroovyClassLoader.parseClass方法,發現如下代碼:
public Class parseClass(String text) throws CompilationFailedException {
return parseClass(text, "script" + System.currentTimeMillis() +
Math.abs(text.hashCode()) + ".groovy");
} protected ClassCollector createCollector(CompilationUnit unit, SourceUnit su) {
InnerLoader loader = AccessController.doPrivileged(new PrivilegedAction<InnerLoader>() {
public InnerLoader run() {
return new InnerLoader(GroovyClassLoader.this);
}
});
return new ClassCollector(loader, unit, su);
}這兩處代碼的意思是: groovy每執行一次腳本,都會生成一個腳本的class對象,這個class對象的名字由 "script" + System.currentTimeMillis() + Math.abs(text.hashCode()組成,對于問題1:每次訂單執行同一個StrategyLogicUnit時,產生的class都不同,每次執行規則腳本都會產品一個新的class。
接著看問題2InnerLoader部分: groovy每執行一次腳本都會new一個InnerLoader去加載這個對象,而對于問題2,我們可以推測:InnerLoader和腳本對象都無法在fullGC的時候被回收,因此運行一段時間后將PERM占滿,一直觸發fullGC。
為什么需要有innerLoader呢?
結合雙親委派模型,由于一個ClassLoader對于同一個名字的類只能加載一次,如果都由GroovyClassLoader加載,那么當一個腳本里定義了C這個類之后,另外一個腳本再定義一個C類的話,GroovyClassLoader就無法加載了。
由于當一個類的ClassLoader被GC之后,這個類才能被GC。
如果由GroovyClassLoader加載所有的類,那么只有當GroovyClassLoader被GC了,所有這些類才能被GC,而如果用InnerLoader的話,由于編譯完源代碼之后,已經沒有對它的外部引用,除了它加載的類,所以只要它加載的類沒有被引用之后,它以及它加載的類就都可以被GC了。
Class回收的條件(摘自《深入理解JVM虛擬機》)
JVM中的Class只有滿足以下三個條件,才能被GC回收,也就是該Class被卸載(unload):
1、該類所有的實例都已經被GC,也就是JVM中不存在該Class的任何實例。
2、加載該類的ClassLoader已經被GC。
3、該類的java.lang.Class
對象沒有在任何地方被引用,如不能在任何地方通過反射訪問該類的方法.
第一點被排除:
查看GroovyClassLoader.parseClass()代碼,總結:Groovy會把腳本編譯為一個名為Scriptxx的類,這個腳本類運行時用反射生成一個實例并調用它的MAIN函數執行,這個動作只會被執行一次,在應用里面不會有其他地方引用該類或它生成的實例;
第二點被排除:
關于InnerLoader:Groovy專門在編譯每個腳本時new一個InnerLoader就是為了解決GC的問題,所以InnerLoader應該是獨立的,并且在應用中不會被引用;
只剩下第三種可能:
該類的Class對象有被引用,繼續查看代碼:
/**
* sets an entry in the class cache.
*
* @param cls the class
* @see #removeClassCacheEntry(String)
* @see #getClassCacheEntry(String)
* @see #clearCache()
*/
protected void setClassCacheEntry(Class cls) {
synchronized (classCache) {
classCache.put(cls.getName(), cls);
}
}可以復現問題并查看原因:具體思路是無限循環解析腳本,jmap -clsstat查看classloader的情況,并結合導出dump查看引用關系。
所以總結原因是:每次groovy parse腳本后,會緩存腳本的Class,下次解析該腳本時,會優先從緩存中讀取。這個緩存的Map由GroovyClassLoader持有,key是腳本的類名,value是class,class對象的命名規則為:
"script" + System.currentTimeMillis() + Math.abs(text.hashCode()) + ".groovy"
因此,每次編譯的對象名都不同,都會在緩存中添加一個class對象,導致class對象不可釋放,隨著次數的增加,編譯的class對象將PERM區撐滿。
大多數的情況下,Groovy都是編譯后執行的,實際在本次的應用場景中,雖然是腳本是以參數傳入,但其實大多數腳本的內容是相同的。
解決方案就是在項目啟動時通過InitializingBean接口對于 parseClass 后生成的 Class 對象進行緩存,key 為 groovyScript 腳本的md5值,并且在配置端修改配置后可進行緩存刷新。 這樣做的好處有兩點:
1、解決metaspace爆滿的問題
2、因為不需要在運行時編譯加載,所以可以加快腳本執行的速度
“Groovy的規則腳本引擎怎么應用”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





