溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Java編碼算法與哈希算法如何使用”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Java編碼算法與哈希算法如何使用”吧!
ASCII 碼就是一種編碼,字母 A 的編碼是十六進制的 0x41 ,字母 B 是 0x42 ,以此類推。
因為 ASCII 編碼最多只能有 127 個字符,要想對更多的文字進行編碼,就需要用占用 2個字節的 Unicode 。而中文的"中"字使用 Unicode 編碼就是 0x4e2d ,使用 UTF8 則需要 3 個字節編碼;因此,最簡單的編碼是直接給每個字符指定一個若干字節表示的整數,復雜一點的 編碼就需要根據一個已有的編碼推算出來。比如 UTF-8 編碼,它是一種不定長編碼, 但可以從給定字符的 Unicode 編碼推算出來。
URL 編碼是瀏覽器發送數據給服務器時使用的編碼,它通常附加在 URL 的參數部 分,例如: https://www.baidu.com/s?wd=%E4%B8%AD%E6%96%87
之所以需要 URL 編碼,是因為出于兼容性考慮,很多服務器只識別 ASCII 字符。 但如果 URL 中包含中文、日文這些非 ASCII 字符怎么辦?不要緊, URL 編碼有一套 規則:
如果字符是 A ~ Z , a ~ z , 0 ~ 9 以及 - 、 _ 、 . 、 * ,則保持不變;
如果是其他字符,先轉換為 UTF-8 編碼,然后對每個字節以 %XX 表示。
例如:字符"中"的 UTF-8 編碼是 0xe4b8ad ,因此,它的 URL 編碼 是 %E4%B8%AD 。 URL 編碼總是大寫。
Java 標準庫提供了一個 URLEncoder 類來對任意字符串進行 URL 編碼:
import java.net.URLEncoder;
public class Main {
public static void main(String[] args) {
String encoded = URLEncoder.encode("中文!", "utf-8");
System.out.println(encoded);
}
}上述代碼的運行結果是 %E4%B8%AD%E6%96%87%21 ,"中"的 URL 編碼 是 %E4%B8%AD ,"文"的URL編碼是 %E6%96%87 , ! 雖然是 ASCII 字符,也要對其編 碼為 %21 。
如果服務器收到 URL 編碼的字符串,就可以對其進行解碼,還原成原始字符串。 Java 標準庫的 URLDecoder 就可以解碼:
public class Main {
public static void main(String[] args) {
String decoded = URLDecoder.decode("%E4%B8%AD%E6%96%87%21", "utf-8");
System.out.println(decoded);
}
}特別注意: URL 編碼是編碼算法,不是加密算法。 URL 編碼的目的是把任意文本數據編碼為 % 前綴 表示的文本,編碼后的文本僅包含 A ~ Z , a ~ z , 0 ~ 9 , - , _ , . , * 和 % ,便于瀏覽 器和服務器處理。
URL 編碼是對字符進行編碼,表示成 %xx 的形式,而 Base64 編碼是對二進制數 據進行編碼,表示成文本格式。
Base64 編碼可以把任意長度的二進制數據變為純文本,并且純文本內容中且只包 含指定字符內容: A ~ Z 、 a ~ z 、 0 ~ 9 、 + 、 / 、 = 。它的原理是把 3 字 節的二進制數據按 6bit 一組,用 4 個int整數表示,然后查表,把 int 整數用索引對 應到字符,得到編碼后的字符串。
6 位整數的范圍總是 0 ~ 63 ,所以,能用 64 個字符表示:字符 A ~ Z 對應索 引 0 ~ 25 ,字符 a ~ z 對應索引 26 ~ 51 ,字符 0 ~ 9 對應索引 52 ~ 61 ,最 后兩個索引 62 、 63 分別用字符 + 和 / 表示。
舉個例子: 3 個 byte 數據分別是 e4 、 b8 、 ad ,按 6bit 分組得到 39 、 0b 、 22 和 2d :
┌───────────────┬───────────────┬───────────────┐
│ e4 │ b8 │ ad │
└───────────────┴───────────────┴───────────────┘
┌─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┐
│1│1│1│0│0│1│0│0│1│0│1│1│1│0│0│0│1│0│1│0│1│1│0│1│
└─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┘
┌───────────┬───────────┬───────────┬───────────┐
│ 39 │ 0b │ 22 │ 2d │
└───────────┴───────────┴───────────┴───────────┘
在 Java 中,二進制數據就是 byte[] 數組。 Java 標準庫提供了 Base64 來對 byte[] 數組進行編解碼:
public class Main {
public static void main(String[] args) {
byte[] input = new byte[] { (byte) 0xe4, (byte) 0xb8, (byte) 0xad };
String b64encoded = Base64.getEncoder().encodeToString(input);
System.out.println(b64encoded);
}
}編碼后得到字符串結果: 5Lit4 。要對這個字符使用 Base64 解碼,仍然用 Base64 這個類:
public class Main {
public static void main(String[] args) {
byte[] output = Base64.getDecoder().decode("5Lit");
System.out.println(Arrays.toString(output)); // [-28, -72, -83]
}
}因為標準的 Base64 編碼會出現 + 、 / 和 = ,所以不適合把 Base64 編碼后的字符串放到 URL 中。 一種針對 URL 的 Base64 編碼可以在 URL 中使用的 Base64 編碼,它僅僅是把 + 變成 - , / 變成 _ :
public class Main {
public static void main(String[] args) {
// 原始字節內容
byte[] input = new byte[] { 0x01, 0x02, 0x7f, 0x00 };
// 分別使用兩種方式進行編碼
String b64Encode = Base64.getEncoder().encodeToString(input);
String b64UrlEncoded = Base64.getUrlEncoder().encodeToString(input);
// 結果完全一致
System.out.println(b64Encode);
System.out.println(b64UrlEncoded);
// 分別使用兩種方式進行重新解碼
byte[] output1 = Base64.getDecoder().decode(b64Encode);
System.out.println(Arrays.toString(output1));
byte[] output2 = Base64.getUrlDecoder().decode(b64UrlEncoded);
System.out.println(Arrays.toString(output2));
}
}Base64 編碼的目的是把二進制數據變成文本格式,這樣在很多文本中就可以處理二進 制數據。例如,電子郵件協議就是文本協議,如果要在電子郵件中添加一個二進制文 件,就可以用 Base64 編碼,然后以文本的形式傳送。
Base64 編碼的缺點是傳輸效率會降低,因為它把原始數據的長度增加了1/3。和 URL 編碼一樣, Base64 編碼是一種編碼算法,不是加密算法。
如果把 Base64 的 64 個字符編碼表換成 32 個、 48 個或者 58 個,就可以使 用 Base32 編碼, Base48 編碼和 Base58 編碼。字符越少,編碼的效率就會越低。
哈希算法( Hash )又稱摘要算法( Digest ),它的作用是:對任意一組輸入數 據進行計算,得到一個固定長度的輸出摘要。哈希算法的目的:為了驗證原始數據是否被篡改。
哈希算法最重要的特點就是:
相同的輸入一定得到相同的輸出;
不同的輸入大概率得到不同的輸出。
Java字符串的 hashCode() 就是一個哈希算法,它的輸入是任意字符串,輸出是固定 的 4 字節 int 整數:
"hello".hashCode(); // 0x5e918d2 "hello, java".hashCode(); // 0x7a9d88e8 "hello, bob".hashCode(); // 0xa0dbae2f
兩個相同的字符串永遠會計算出相同的 hashCode ,否則基于 hashCode 定位的 HashMap 就無法正常工 作。這也是為什么當我們自定義一個 class 時,覆寫 equals() 方法時我們必須正確覆寫 hashCode() 方法。
哈希碰撞是指,兩個不同的輸入得到了相同的輸出:
"AaAaAa".hashCode(); // 0x7460e8c0 "BBAaBB".hashCode(); // 0x7460e8c0 "通話".hashCode(); // 0x11ff03 "重地".hashCode(); // 0x11ff03
碰撞能不能避免?答案是不能。碰撞是一定會出現的,因為輸出的字節長度是固定的, String 的 hashCode() 輸出是 4 字節整數,最多只有 4294967296 種輸出,但輸入的數據長度是不固定的,有無數種輸入。所以,哈希算 法是把一個無限的輸入集合映射到一個有限的輸出集合,必然會產生碰撞。
碰撞不可怕,我們擔心的不是碰撞,而是碰撞的概率,因為碰撞概率的高低關系到哈希算法的安全性。一個安全的哈希算法必須滿足:
碰撞概率低;
不能猜測輸出:輸入的任意一個 bit 的變化會造成輸出完全不同,這樣就很難從輸出反推輸入(只能依靠 暴力窮舉)。
假設一種哈希算法有如下規律:
hashA("java001") = "123456"
hashA("java002") = "123457"
hashA("java003") = "123458"那么很容易從輸出 123459 反推輸入,這種哈希算法就不安全。安全的哈希算法從輸出是看不出任何規律的:
hashB("java001") = "123456"
hashB("java002") = "580271"
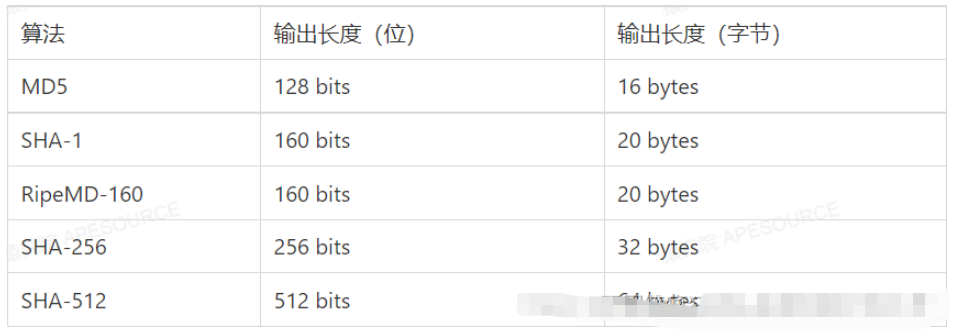
hashB("java003") = ???常用的哈希算法有:根據碰撞概率,哈希算法的輸出長度越長,就越難產生碰撞,也就越安全。
import java.security.MessageDigest;
public class main {
public static void main(String[] args) {
// 創建一個MessageDigest實例:
MessageDigest md = MessageDigest.getInstance("MD5");
// 反復調用update輸入數據:
md.update("Hello".getBytes("UTF-8"));
md.update("World".getBytes("UTF-8"));
// 16 bytes: 68e109f0f40ca72a15e05cc22786f8e6
byte[] results = md.digest();
StringBuilder sb = new StringBuilder();
for(byte bite : results) {
sb.append(String.format("%02x", bite));
}
System.out.println(sb.toString());
}
}運行上述代碼,可以得到輸入HelloWorld 的 MD5 是 68e109f0f40ca72a15e05cc22786f8e6
使用 MessageDigest 時,我們首先根據哈希算法獲取一個 MessageDigest 實例,然后, 反復調用 update(byte[]) 輸入數據。當輸入結束后,調用 digest() 方法獲得 byte [] 數組表示的摘要,最后,把它轉換為十六進制的字符串。
import java.security.MessageDigest;
public class main {
public static void main(String[] args) {
// 創建一個MessageDigest實例:
MessageDigest md = MessageDigest.getInstance("SHA-1");
// 反復調用update輸入數據:
md.update("Hello".getBytes("UTF-8"));
md.update("World".getBytes("UTF-8"));
// 20 bytes: db8ac1c259eb89d4a131b253bacfca5f319d54f2
byte[] results = md.digest();
StringBuilder sb = new StringBuilder();
for(byte bite : results) {
sb.append(String.format("%02x", bite));
}
System.out.println(sb.toString());
}
}類似的,計算 SHA-256 ,我們需要傳入名稱" SHA-256 ",計算 SHA-512 ,我們需要傳入名稱" SHA-512 "。
BouncyCastle是一個提供了很多哈希算法和加密算法的第三方開源庫。它提供了 Java 標準庫沒 有的一些算法,例如, RipeMD160 哈希算法。 RIPEMD160 是一種基于 Merkle-Damgård 結構的加密哈希函數,它是比特幣標準之一。 RIPEMD-160 是 RIPEMD 算法的增強版本, RIPEMD-160 算法可以產生出 160 位的的哈希摘要。
用法:
首先,我們必須把 BouncyCastle 提供的 bcprov-jdk15on-1.70.jar 添加至 classpath 。
其次,Java標準庫的 java.security 包提供了一種標準機制,允許第三方提供商無縫接入。我們要使用 Bouncy Castle 提供的 RipeMD160 算法,需要先把 BouncyCastle 注冊一下:
public class Main {
public static void main(String[] args) throws Exception {
// 注冊BouncyCastle提供的通知類對象BouncyCastleProvider
Security.addProvider(new BouncyCastleProvider());
// 獲取RipeMD160算法的"消息摘要對象"(加密對象)
MessageDigest md = MessageDigest.getInstance("RipeMD160");
// 更新原始數據
md.update("HelloWorld".getBytes());
// 獲取消息摘要(加密)
byte[] result = md.digest();
// 消息摘要的字節長度和內容
System.out.println(result.length); // 160位=20字節
System.out.println(Arrays.toString(result));
// 16進制內容字符串
String hex = new BigInteger(1,result).toString(16);
System.out.println(hex.length()); // 20字節=40個字符
System.out.println(hex);
}
}校驗下載文件
因為相同的輸入永遠會得到相同的輸出,因此,如果輸入被修改了,得到的輸出就會不同。
如何判斷下載到本地的軟件是原始的、未經篡改的文件?我們只需要自己計算一下本地文件的哈希值,再 與官網公開的哈希值對比,如果相同,說明文件下載正確,否則,說明文件已被篡改。
存儲用戶密碼
如果直接將用戶的原始口令存放到數據庫中,會產生極大的安全風險: 數據庫管理員能夠看到用戶明文口令; 數據庫數據一旦泄漏,黑客即可獲取用戶明文口令。
到此,相信大家對“Java編碼算法與哈希算法如何使用”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





