溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“MySQL全文索引如何解決like模糊匹配查詢慢的問題”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“MySQL全文索引如何解決like模糊匹配查詢慢的問題”吧!
需要模糊匹配查詢一個單詞
select * from t_phrase where LOCATE('昌',phrase) = 0;
select * from t_chinese_phrase where instr(phrase,'昌') > 0;
select * from t_chinese_phrase where phrase like '%昌%'
explain一下看看執行計劃

由explain的結果可知,雖然我們給phrase建了索引,但是查詢的時候,索引是失效的。
原因: mysql的索引是B+樹結構,InnoDB在模糊查詢數據時使用 "%xx" 會導致索引失效(此處就不展開講了)
從查詢時長上來看,花費時間:90ms
目前數據量:93230(9.3W)已經需要90ms,這個時間不太能接受,假如數據量增加,這個時間會不斷增長。
解決方案:
數據量不大的情況下,使用mysql的全文索引;
數據量比較大或者mysql的全文索引不達預期的情況下,可以考慮使用ES
下面主要是MySQL的全文索引相關.
舊版的MySQL的全文索引只能用在MyISAM存儲引擎的char、varchar和text的字段上。
MySQL5.6.24上InnoDB引擎也加入了全文索引。
全文檢索(Full-Text Search) 是將存儲于數據庫中的整本書或整篇文章中的任意內容信息查找出來的技術。它可以根據需要獲得全文中有關章、節、段、詞等信息,也可以進行各種統計和分析
若需對大量數據設置全文索引,建議先添加數據再創建索引。
1、創建表時創建全文索引
2、為已有表添加全文索引create table 表名(
字段名1,
字段名2,
字段名3,
字段名4,
FULLTEXT full_index_name (字段名)
)ENGINE=InnoDB;
create fulltext index 索引名稱 on 表名(字段名);
eg:
create table t_word
(
id int unsigned auto_increment comment '自增id' primary key,
uid char(32) not null comment '32位唯一id',
word varchar(256) null comment '英文單詞',
translate varchar(256) null
);
create fulltext index full_idx_translate
on t_word (translate);
create fulltext index full_idx_word
on t_word (word);
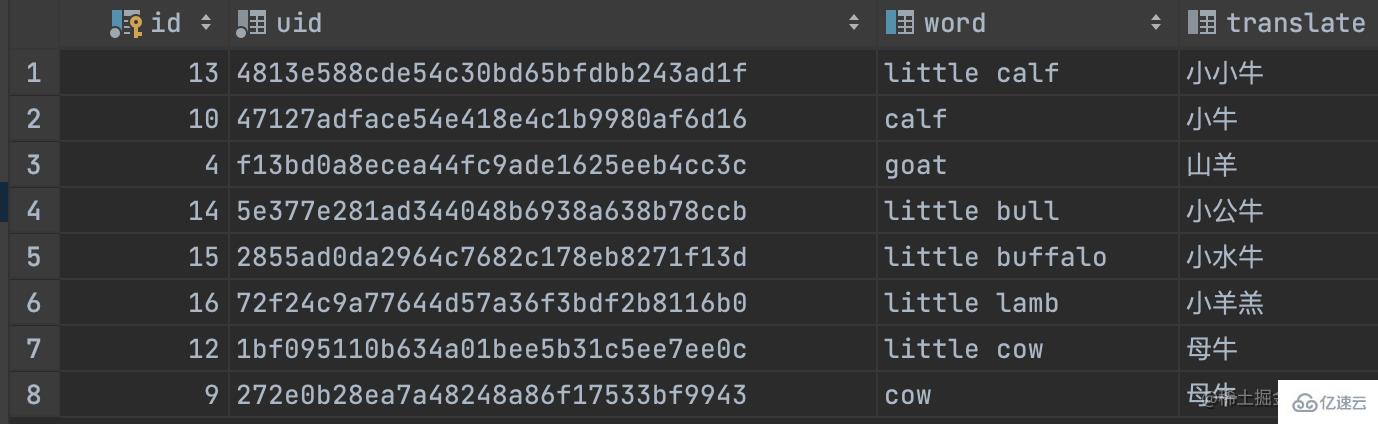
INSERT INTO t_word (id, uid, word, translate) VALUES (1, '9d592499c65648b0a9519206688ef3f9', 'lion', '獅子');
INSERT INTO t_word (id, uid, word, translate) VALUES (2, 'ce26ac4239514bc6af481bcb1d9b67df', 'panda', '熊貓');
INSERT INTO t_word (id, uid, word, translate) VALUES (3, 'a7d6042853c44904b68275daafb44702', 'tiger', '老虎');
INSERT INTO t_word (id, uid, word, translate) VALUES (4, 'f13bd0a8ecea44fc9ade1625eeb4cc3c', 'goat', '山羊');
INSERT INTO t_word (id, uid, word, translate) VALUES (5, '27d5cbfc93a046388d712085e567474f', 'sheep', '綿羊');
INSERT INTO t_word (id, uid, word, translate) VALUES (6, 'ed35df138cf348aa937781be8ee21cbf', 'lamb', '羊羔');
INSERT INTO t_word (id, uid, word, translate) VALUES (7, 'fba5861d9527440990276e999f47ef8f', 'buffalo', '水牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (8, '3a72e76f210841b1939fff0d3d721375', 'bull', '公牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (9, '272e0b28ea7a48248a86f17533bf9943', 'cow', '母牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (10, '47127adface54e418e4c1b9980af6d16', 'calf', '小牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (11, '10592499c65648b0a9519206688ef3f9', 'little lion', '小獅子');
INSERT INTO t_word (id, uid, word, translate) VALUES (12, '1bf095110b634a01bee5b31c5ee7ee0c', 'little cow', '母牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (13, '4813e588cde54c30bd65bfdbb243ad1f', 'little calf', '小小牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (14, '5e377e281ad344048b6938a638b78ccb', 'little bull', '小公牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (15, '2855ad0da2964c7682c178eb8271f13d', 'little buffalo', '小水牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (16, '72f24c9a77644d57a36f3bdf2b8116b0', 'little lamb', '小羊羔');
INSERT INTO t_word (id, uid, word, translate) VALUES (17, '2d592499c65648b0a9519206688ef3f9', 'I''m a big lion', '我是一只大獅子');
3、刪除全文索引
alter table 表名 drop index 索引名;
語法
MATCH(col1,col2,...) AGAINST(expr[search_modifier])
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}
4.1 IN NATURAL LANGUAGE MODE
自然語言模式是MySQL 默認 的全文檢索模式。自然語言模式不能使用操作符,不能指定關鍵詞必須出現或者必須不能出現等復雜查詢。
// 默認是使用 in natural language mode
select * from t_word where match(word) against ('lion');
// 或者 顯示寫
select * from t_word where match(word) against ('lion' in natural language mode);
結果如下:

4.2 IN BOOLEAN MODE
BOOLEAN模式可以使用操作符,可以支持指定關鍵詞必須出現或者必須不能出現或者關鍵詞的權重高還是低等復雜查詢。推薦使用boolean模式
| 操作者 | 描述 |
|---|---|
| 為空 | 默認,包含該詞 |
| + | 包括,這個詞必須存在。 |
| - | 排除,詞不得出現。 |
| >(大于號) | 包括,并提高排名值,查詢的結果會靠前 |
| < | 包括,并降低排名值,查詢的結果會靠后 |
| () | 將單詞分組為子表達式(允許將它們作為一組包括在內,排除在外,排名等等)。 |
| ? | 否定單詞的排名值。 |
| * | 通配符在這個詞的結尾。 |
| “” | 定義短語(與單個單詞列表相對,整個短語匹配以包含或排除)。 |
示例:
// 默認是使用 in natural language mode
select * from t_word where match(word) against ('lion');
// 或者 顯示寫
select * from t_word where match(word) against ('lion' in natural language mode);

// 排除包含lion記錄、查詢出包含cow或者little的記錄,提升包含calf單詞的排名,降低包含cow記錄的排名,查詢出以go開頭的記錄
select * from t_word where match(word) against ('-lion cow little >calf <cow go*' in boolean mode) ;
好像問題都解決了, 但是問題才剛開始
回到最開始的需求,我想模糊搜索
select * from t_word where match(word) against('lio' in boolean mode);
預期值:把包含lion的都查詢出來 實際結果:啥都沒有。

全匹配查詢的時候能查詢出來
select * from t_word where match(translate) against('小水牛' in boolean mode);

只查詢部分查詢不出來。如:下面只查詢 "小水" 或者"水牛" 都沒有數據
select * from t_word where match(translate) against('小水' in boolean mode);

奇怪了,這咋沒出來呢?
全文索引默認是只按照
空格進行分詞的,所以當我完整的單個單詞去查詢的時候是能查出來的。但是使用部分單詞去查詢或者使用部分中文去查詢時,是查詢不出來數據的,像中文需要使用中文分詞器進行分詞。
InnoDB默認的全文索引parser非常合適于Latin,因為Latin是通過空格來分詞的。但對于像中文,日文和韓文來說,沒有這樣的分隔符。一個詞可以由多個字來組成,所以我們需要用不同的方式來處理。在MySQL 5.7.6中我們能使用一個新的全文索引插件來處理它們:N-gram parser。
在全文索引中,n-gram就是一段文字里面連續的n個字的序列。例如,用n-gram來對“齒輪傳動”來進行分詞,得到的結果如下:
N=1 : '齒', '輪', '傳', '動';
N=2 : '齒輪', '輪傳', '傳動';
N=3 : '齒輪傳', '輪傳動';
N=4 : '齒輪傳動';
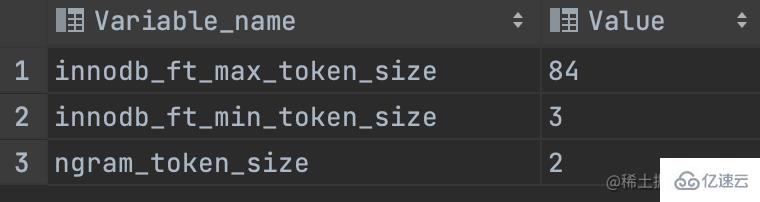
show variables like '%token%';
參數解析:
innodb_ft_min_token_size
默認3,表示最小3個字符作為一個關鍵詞,增大該值可減少全文索引的大小
innodb_ft_max_token_size
默認84,表示最大84個字符作為一個關鍵詞,限制該值可減少全文索引的大小
ngram_token_size
默認2,表示2個字符作為內置分詞解析器的一個關鍵詞,合法取值范圍是1-10,如對“abcd”建立全文索引,關鍵詞為’ab’,‘bc’,‘cd’ 當使用ngram分詞解析器時,innodb_ft_min_token_size和innodb_ft_max_token_size 無效
方式1: 在my.cnf中修改/添加參數
[mysqld]ngram_token_size = 1
方式2: 修改啟動參數
mysqld --ngram_token_size=1復制代碼
參數均不可動態修改,修改后需重啟MySQL服務,并重新建立全文索引
這里只提供部分測試數據,我下面sql使用全量數據,數據對不上
create table t_chinese_phrase
(
id int unsigned auto_increment comment 'id'
primary key,
phrase varchar(32) not null comment '詞組'
)
collate = utf8mb4_general_ci;
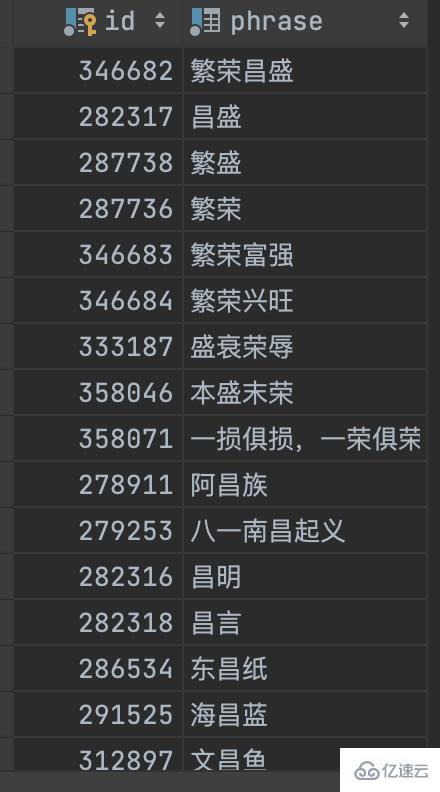
INSERT INTO t_chinese_phrase (id, phrase) VALUES (278911, '阿昌族');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (279253, '八一南昌起義');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (282316, '昌明');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (282317, '昌盛');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (282318, '昌言');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (286534, '東昌紙');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (291525, '海昌藍');
INSERT INTO test.t_chinese_phrase (id, phrase) VALUES (346682, '繁榮昌盛');
INSERT INTO test.t_chinese_phrase (id, phrase) VALUES (282317, '昌盛');
INSERT INTO test.t_chinese_phrase (id, phrase) VALUES (287738, '繁盛');
INSERT INTO test.t_chinese_phrase (id, phrase) VALUES (287736, '繁榮');
mysql 全文索引使用倒排索引為 full inverted index
結構:{單詞,(單詞所在文檔的ID,單詞在具體文件中的位置)}
添加索引:
alter table t_chinese_phrase add fulltext ful_phrase (phrase) with parser ngram;
建完索引,我們可以通過查詢INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE和INFORMATION_SCHEMA.INNODB_FT_TABLE_TABLE來查詢哪些詞在全文索引里面。這是一個非常有用的調試工具。如果我們發現一個包含某個詞的文檔,沒有如我們所期望的那樣出現在查詢結果中,那么這個詞可能是因為某些原因不在全文索引里面。比如,它含有stopword,或者它的大小小于ngram_token_size等等。這個時候我們就可以通過查詢這兩個表來確認。下面是一個簡單的例子:
# test: 庫名 t_chinese_phrase: 表名字
SET GLOBAL innodb_ft_aux_table="test/t_chinese_phrase";
# 查詢分詞情況
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE;
# 查詢分詞情況
select * from information_schema.innodb_ft_index_table;
查詢結果如下:
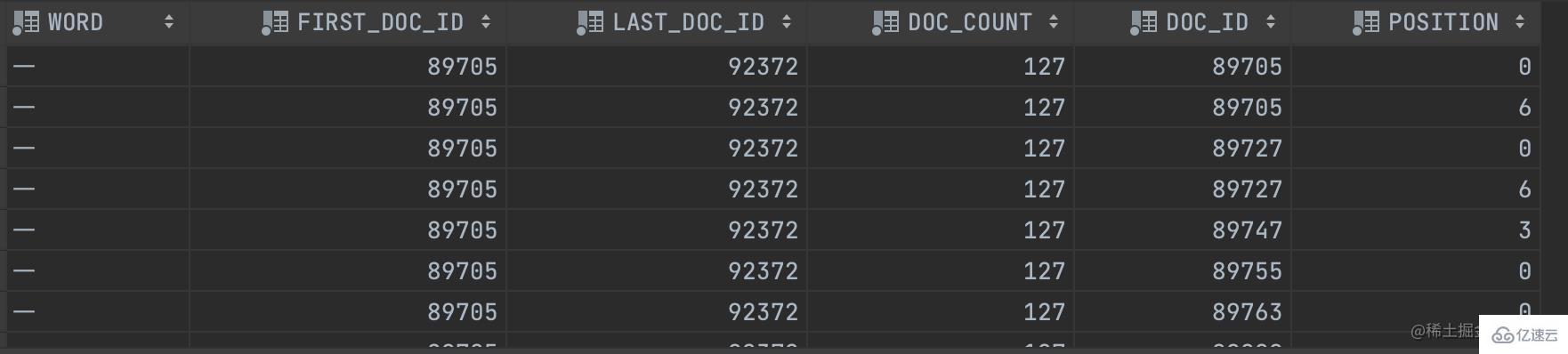
因為我們上面設置了分詞數是1,所以,可以看到都是按照一個詞進行分詞的。
字段解析:
FIRST_DOC_ID :word第一次出現的文檔ID
LAST_DOC_ID : word最后一次出現的文檔ID
DOC_COUNT :含有word的文檔個數
DOC_ID :當前文檔ID
POSITION : word 當在前文檔ID的位置
在自然語言模式(NATURAL LANGUAGE MODE)下,文本的查詢被轉換為n-gram分詞查詢的
并集。
例如,當ngram_token_size = 1 時,(‘繁榮昌盛’)轉換為(‘繁 榮 昌 盛’)。下面一個例子:
SELECT * FROM t_chinese_phrase WHERE MATCH (phrase) AGAINST ('繁榮昌盛' in natural language mode) ;
布爾模式(BOOLEAN MODE)文本查詢被轉化為n-gram分詞的
短語查詢
例如,當ngram_token_size = 1 時,(‘繁榮昌盛’)轉換為(‘”繁榮昌盛“’)。下面一個例子:
SELECT * FROM t_chinese_phrase WHERE MATCH (phrase) AGAINST ('繁榮昌盛' in boolean mode) ;
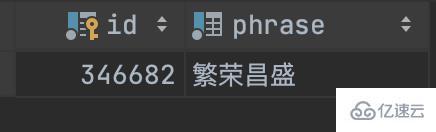
回到我們最開始的查詢需求,看看實際的效果
查詢包含了“昌”的數據
SELECT * FROM t_chinese_phrase WHERE MATCH (phrase) AGAINST ('昌' IN boolean MODE) ;
SELECT * FROM t_chinese_phrase WHERE MATCH (phrase) AGAINST ('昌' ) order by id asc;
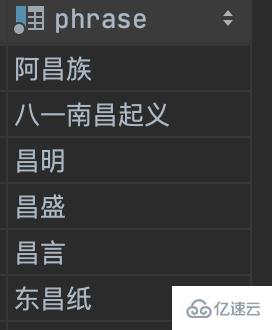
可以看到結果:目前“昌”在任意位置都能被查詢到。
查詢執行計劃如下:

耗時31ms(不走索引是90ms),耗時差不多是之前的1/3。
1、自然語言全文索引創建索引時的字段需與查詢的字段保持一致,即MATCH里的字段必須和FULLTEXT里的一模一樣;
2、自然語言檢索時,檢索的關鍵字在所有數據中不能超過50%(即常見詞),則不會檢索出結果。可以通過布爾檢索查詢;
3、在mysql的stopword中的單詞檢索不出結果。可通過
登錄后復制SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD
查詢所有的stopword。遇到這種情況,有兩種解決辦法:
(1)stopword一般是mysql自建的,但可以通過設置ft_stopword_file變量為自定義文件,從而自己設置stopword,設置完成后需要重新創建索引。但不建議使用這種方法;
(2)使用布爾索引查詢。
4、小于最短長度和大于最長長度的關鍵詞無法查出結果。可以通過設置對應的變量來改變長度限制,修改后需要重新創建索引。
myisam引擎下對應的變量名為ft_min_word_len和ft_max_word_len
innodb引擎下對應的變量名為innodb_ft_min_token_size和innodb_ft_max_token_size
5、MySQL5.7.6之前的版本不支持中文,需使用第三方插件
6、全文索引只能在 InnoDB(MySQL 5.6以后) 或 MyISAM 的表上使用,并且只能用于創建 char,varchar,text 類型的列。
感謝各位的閱讀,以上就是“MySQL全文索引如何解決like模糊匹配查詢慢的問題”的內容了,經過本文的學習后,相信大家對MySQL全文索引如何解決like模糊匹配查詢慢的問題這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





