溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“基于Python怎么通過cookie獲取某芯片網站信息”,內容詳細,步驟清晰,細節處理妥當,希望這篇“基于Python怎么通過cookie獲取某芯片網站信息”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
進入頁面,就能看到我們需求的信息了。
但是,在頁面請求完成之前,有一點點不對勁,就是頁面的各個部份請求的速度是不一樣的:
所以啊,需要的數據,大概率不是簡單的get請求,所以要進一步去看,特意在開發者模式—Fetch/XHR選項卡中有一個請求,返回值正好是我們需要的內容:

程序員必備接口測試調試工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api設計、調試、文檔、自動化測試工具
后端、前端、測試,同時在線協作,內容實時同步
這一條鏈接返回了所有的數據,無需翻頁,下面開始請求鏈接。
根據上面的鏈接,直接get請求,分析json即可,上代碼:

登錄后復制 def getItemList():
url = "https://www.xx.com.cn/selectiontool/paramdata/family/3658/results?lang=cn&output=json"
headers = {
'authority': 'www.xx.com.cn',
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
res = getRes(url,headers,'','','GET')//自己寫的請求方法
nodes = res.json()['ParametricResults']
for node in nodes:
data = {}
data["itemName"] = node["o3"] #名稱
data["inventory"] = node["p3318"] #庫存
data["price"] = node["p1130"]['multipair1']['l'] #價格
data["infoUrl"] = f"https://www.xx.com.cn/product/cn/{node['o1']}"#詳情URL
分析上面的json,可知 o3 是商品名,p3318是庫存,p1130里面的內容有一個帶單位的價格,o1是型號,可湊出詳情鏈接,下面是請求結果:

終于拿到詳情頁鏈接了,該獲取剩下的內容了。
打開開發者模式,沒有額外的請求,只有一個包含內容的get請求。
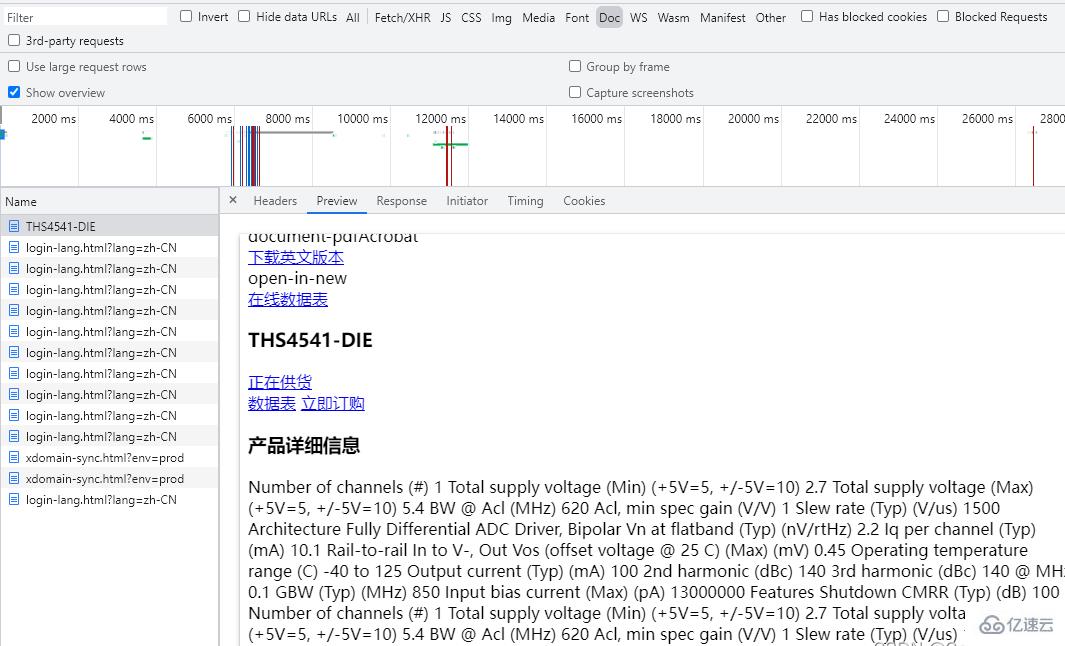
那直接請求不就得了,上代碼:
登錄后復制def getItemInfo(url):
logger.info(f'正在請求詳情url-{url}')
headers = {
'authority': 'www.xx.com.cn',
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
'referer':'https://www.xx.com.cn/product/cn/THS4541-DIE',
}
res = getRes(url, headers,'', '', 'GET')//自己寫的請求方法
content = res.content.decode('utf-8')
但是發現,請求的詳情頁,跟開發者模式的預覽怎么不太一樣?

我這里的第一反應就覺得,完了,這個需要cookie。
繼續分析,清屏開發者模式,清除cookie,再次訪問詳情鏈接,在All選項卡中,可以發現:

本以為該請求一次的詳情頁鏈接請求了兩次,兩次中間還有一個xhr請求。
預覽第一次請求,可以發現跟剛才本地請求的內容相差無幾:

所以問題出在第二次的請求,進一步分析:
查看第二次的get請求,與第一次的請求相差了一堆cookie

簡化cookie,發現這些cookie最關鍵的參數是ak_bmsc這一部分,而這一部分參數,就來自上一個xhr請求中的響應頭set-cookie中:

分析這個xhr請求,請求鏈接
這是個post請求,先從payload參數下手:

這個bm-verify參數,是不是有些眼熟?這就是第一次的get請求返回的內容嗎,下面還有一個pow參數:

"pow":j,這個j參數就在上面,聲明了i和兩個拼接的數字字符串轉成int之后相加之后的結果:
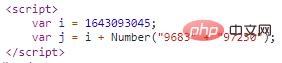
通過這一系列請求,返回了最終get請求所需要的cookie,講的比較瑣碎,上代碼:
登錄后復制 #詳情需要cookie
def getVerify(url):
infourl = url
headers = {
'authority': 'www.xx.com.cn',
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
proxies = getApiIp()//取代理
if proxies:
#無cookie訪問詳情頁拿參數bm-verify,pow
res = getRes(infourl,headers,proxies,'','GET')
if res:
#拿第一次請求的ak_bmsc
cookie = re.findall("ak_bmsc=.*?;",res.headers['set-cookie'])[0]
#拿bm-verify
verifys = re.findall('"bm-verify": "(.*?)"', res.text)[0]
#合并字符串轉int相加取pow
a = re.findall('var i = (\d+);',res.text)[0]
b = re.findall('Number\("(.*?)"\);',res.text)[0]
b = int(b.replace('" + "',''))
pow = int(a)+b
post_data = {
'bm-verify': verifys,
'pow':pow
}
#轉json
post_data = json.dumps(post_data)
if verifys:
logger.info('第一次參數獲取完畢')
return post_data,proxies,cookie
else:
print('verify獲取異常')
else:
print('verify請求出錯')
# 第二次帶參數訪問驗證鏈接
def getCookie(url):
post_headers = {
"authority": "www.xx.com.cn",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
"accept": "*/*",
"content-type": "application/json",
"origin": "https://www.xx.com.cn",
"referer":url,
}
post_data,proxies,c_cookie = getVerify(url)
post_headers['Cookie'] = c_cookie
posturl = "https://www.xx.com.cn/_sec/verify?provider=interstitial"
check = getRes(posturl,post_headers,proxies,post_data,'POST')
if check:
#從請求頭拿到ak_bmsc cookie
cookie = check.headers['Set-Cookie']
cookie = re.findall("ak_bmsc=.*?;",cookie)[0]
if cookie:
logger.info('Cookie獲取完畢')
return cookie,proxies
else:
print('cookie獲取異常')
else:
print('cookie請求出錯')
簡單的概括一下詳情頁的請求流程:
第一次請求,取得所需參數bm-verify,pow,cookie,提供給下一次的post請求(getVerify方法)
第二次請求,根據已知條件進行post請求,并獲取響應頭cookie的ak_bmsc(getCookie)
切記,在整個獲取cookie的三次請求過程中,第二、三兩次請求都需要伴隨著上一次請求的ak_bmsc作為cookie傳遞,第二次請求需要第一次的ak_bmsc,最終請求需要第二次的ak_bmsc。
登錄后復制 def getItemInfo(url):
logger.info(f'正在請求詳情url-{url}')
cookie,proxies = getCookie(url)
headers = {
'authority': 'www.xx.com.cn',
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
'referer':'https://www.xx.com.cn/product/cn/THS4541-DIE',
'cookie':cookie
}
res = getRes(url, headers,proxies, '', 'GET')
content = res.content.decode('utf-8')
print(content)
exit()
sel = Selector(text=content)
Parameters = sel.xpath('//ti-tab-panel[@tab-title="參數"]/ti-view-more/div').extract_first()
Features = sel.xpath('//ti-tab-panel[@tab-title="特性"]/ti-view-more/div').extract_first()
Description = sel.xpath('//ti-tab-panel[@tab-title="描述"]/ti-view-more').extract_first()
if Parameters and Features and Description:
return Parameters,Features,Description
通過上一步cookie的獲取,帶著cookie再次訪問詳情鏈接,就可以順利的獲取內容并可以使用xpath進行解析,獲取需要的內容。
T網站詳情頁帶cookie請求有100多次,如果用本地代理一直去請求,會有IP封鎖的可能性出現,導致無法正常獲取。所以,需要高效請求的話,優質穩定的代理IP必不可少,我這里使用的ipidea代理請求的T網站,數據很快就訪問出來了。
地址:http://www.ipidea.net/?utm-source=PHP&utm-keyword=?PHP ,首次可以白嫖流量哦。本次使用的api獲取,代碼如下:
登錄后復制 # api獲取ip
def getApiIp():
# 獲取且僅獲取一個ip
api_url = 'http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1?ions=&port=1'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('獲取失敗')
except:
print('獲取失敗')
登錄后復制 # coding=utf-8
import requests
from scrapy import Selector
import re
import json
from loguru import logger
# api獲取ip
def getApiIp():
# 獲取且僅獲取一個ip
api_url = '獲取代理地址'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('獲取失敗')
except:
print('獲取失敗')
def getItemList():
url = "https://www.xx.com.cn/selectiontool/paramdata/family/3658/results?lang=cn&output=json"
headers = {
'authority': 'www.xx.com.cn',
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
proxies = getApiIp()
if proxies:
# res = requests.get(url, headers=headers, proxies=proxies)
res = getRes(url,headers,proxies,'','GET')
nodes = res.json()['ParametricResults']
for node in nodes:
data = {}
data["itemName"] = node["o3"] #名稱
data["inventory"] = node["p3318"] #庫存
data["price"] = node["p1130"]['multipair1']['l'] #價格
data["infoUrl"] = f"https://www.ti.com.cn/product/cn/{node['o1']}"#詳情URL
Parameters, Features, Description = getItemInfo(data["infoUrl"])
data['Parameters'] = Parameters
data['Features'] = Features
data['Description'] = Description
print(data)
#詳情需要cookie
def getVerify(url):
infourl = url
headers = {
'authority': 'www.xx.com.cn',
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
proxies = getApiIp()
if proxies:
#訪問詳情頁拿參數bm-verify,pow
res = getRes(infourl,headers,proxies,'','GET')
if res:
#拿第一次請求的ak_bmsc
cookie = re.findall("ak_bmsc=.*?;",res.headers['set-cookie'])[0]
#拿bm-verify
verifys = re.findall('"bm-verify": "(.*?)"', res.text)[0]
#字符串轉int相加取pow
a = re.findall('var i = (\d+);',res.text)[0]
b = re.findall('Number\("(.*?)"\);',res.text)[0]
b = int(b.replace('" + "',''))
pow = int(a)+b
post_data = {
'bm-verify': verifys,
'pow':pow
}
#轉json
post_data = json.dumps(post_data)
if verifys:
logger.info('第一次參數獲取完畢')
return post_data,proxies,cookie
else:
print('verify獲取異常')
else:
print('verify請求出錯')
# 第二次帶參數訪問驗證鏈接
def getCookie(url):
post_headers = {
"authority": "www.xx.com.cn",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
"accept": "*/*",
"content-type": "application/json",
"origin": "https://www.xx.com.cn",
"referer":url,
}
post_data,proxies,c_cookie = getVerify(url)
post_headers['Cookie'] = c_cookie
posturl = "https://www.xx.com.cn/_sec/verify?provider=interstitial"
check = getRes(posturl,post_headers,proxies,post_data,'POST')
if check:
#從請求頭拿到ak_bmsc cookie
cookie = check.headers['Set-Cookie']
cookie = re.findall("ak_bmsc=.*?;",cookie)[0]
if cookie:
logger.info('Cookie獲取完畢')
return cookie,proxies
else:
print('cookie獲取異常')
else:
print('cookie請求出錯')
def getItemInfo(url):
logger.info(f'正在請求詳情url-{url}')
cookie,proxies = getCookie(url)
headers = {
'authority': 'www.xx.com.cn',
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
'referer':'https://www.xx.com.cn/product/cn/THS4541-DIE',
'cookie':cookie
}
res = getRes(url, headers,proxies, '', 'GET')
content = res.content.decode('utf-8')
sel = Selector(text=content)
Parameters = sel.xpath('//ti-tab-panel[@tab-title="參數"]/ti-view-more/div').extract_first()
Features = sel.xpath('//ti-tab-panel[@tab-title="特性"]/ti-view-more/div').extract_first()
Description = sel.xpath('//ti-tab-panel[@tab-title="描述"]/ti-view-more').extract_first()
if Parameters and Features and Description:
return Parameters,Features,Description
#專門發送請求的方法,代理請求三次,三次失敗返回錯誤
def getRes(url,headers,proxies,post_data,method):
if proxies:
for i in range(3):
try:
# 傳代理的post請求
if method == 'POST':
res = requests.post(url,headers=headers,data=post_data,proxies=proxies)
# 傳代理的get請求
else:
res = requests.get(url, headers=headers,proxies=proxies)
if res:
return res
except:
print(f'第{i}次請求出錯')
else:
return None
else:
for i in range(3):
proxies = getApiIp()
try:
# 請求代理的post請求
if method == 'POST':
res = requests.post(url, headers=headers, data=post_data, proxies=proxies)
# 請求代理的get請求
else:
res = requests.get(url, headers=headers, proxies=proxies)
if res:
return res
except:
print(f"第{i}次請求出錯")
else:
return None
if __name__ == '__main__':
getItemList()

讀到這里,這篇“基于Python怎么通過cookie獲取某芯片網站信息”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





