溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了python壓縮和解壓縮模塊之zlib怎么使用的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇python壓縮和解壓縮模塊之zlib怎么使用文章都會有所收獲,下面我們一起來看看吧。
由于早期的zlib和Python之間不兼容,故推薦1.1.4以后的版本。導入zlib后可以查看版本號
>>> import zlib >>> zlib.ZLIB_VERSION '1.2.11' >>> zlib.ZLIB_RUNTIME_VERSION '1.2.11'
zlib中封裝了兩對壓縮和解壓的函數
| 壓縮 | 解壓 |
|---|---|
| compress | decompress |
| compressobj | decompressobj |
其中compress和decompress比較簡單,二者聲明為
zlib.compress(data, level=-1) zlib.decompress(data, wbits=MAX_WBITS, bufsize=DEF_BUF_SIZE)
即分別對data進行壓縮和解壓。
其中level為整數,用于指定壓縮等級,決定壓縮后文件的大小,取值為-1到9。
zlib中內置了四個常量,用以表示四種情況。
| 壓縮模式 | ||
|---|---|---|
| 1 | Z_BEST_SPEED | 最快速度和最低壓縮率 |
| 9 | Z_BEST_COMPRESSION | 最慢速度最高壓縮率 |
| 0 | Z_NO_COMPRESSION | 不壓縮 |
| -1 | Z_DEFAULT_COMPRESSION | 一般相當于設壓縮等級為6 |
解壓函數中的wbits控制歷史緩沖區的大小(或稱“窗口大小”)以及所期望的頭部和尾部格式。
默認為MAX_WBITS,其取值范圍和含義如下
| 包含頭尾 | ||
|---|---|---|
| +8至+15 | 必須 | 窗口尺寸以二為底的對數。輸入必須包含zlib頭部和尾部。 |
| 0 | 必須含頭 | 根據 zlib 頭部自動確定窗口大小 |
| −8至−15 | 無頭尾 | 使用wbits絕對值作為窗口大小以二為底的對數 |
| +24至+31 | 必須包含 | 使用后4個比特位作為窗口大小以二為底的對數。 |
| +40 至+47 | 自動 | 使用后4個比特位作為窗口大小以二為底的對數 |
bufsize是表示緩沖區初始大小,默認為DEF_MEM_LEVEL,由于在解壓過程中會自動調節,故不必完全精確。
例如:
>>> x = b'abcdefghijk'*100 >>> x0 = compress(x,0) >>> x1 = compress(x,1) >>> x9 = compress(x,9) >>> print(len(x),len(x0), len(x1), len(x9)) 1100 1111 32 29 #無壓縮時得到的數據比原始數據還大 >>> d1 = decompress(x9) #解壓縮 >>> d1 == x True
compressobj和decompressobj分別返回一個壓縮對象和解壓對象。
compressobj返回一個 壓縮對象,用來壓縮內存中難以容下的數據流,聲明如下
compressobj(level=-1, method=DEFLATED, wbits=MAX_WBITS, memLevel=DEF_MEM_LEVEL, strategy=Z_DEFAULT_STRATEGY[, zdict])
其中level為壓縮級別,和前文一樣取值為 -1 到 9;method 表示壓縮算法,現在只支持 DEFLATED;memLevel指定內部壓縮操作時所占用內存大小。參數取 1 到 9,默認DEF_MEM_LEVEL,取值越大越占內存,但速度更快。
wbits 和decompress中相似,但取值范圍更少,默認是15(MAX_WBITS)。
參數范圍如下:
| +9 至 +15 | 窗口大小以二為底的對數。 即這些值對應著 512 至 32768 的窗口大小。 更大的值會提供更好的壓縮,同時內存開銷也會更大。 壓縮輸出會包含 zlib 特定格式的頭部和尾部。 |
| −9 至 −15 | 絕對值為窗口大小以二為底的對數。 壓縮輸出僅包含壓縮數據,沒有頭部和尾部。 |
| +25 至 +31 | 后 4 個比特位為窗口大小以二為底的對數。 壓縮輸出包含一個基本的 gzip 頭部,并以校驗和為尾部。 |
strategy 用于調節壓縮算法,默認即可。
zdict 指定預定義的壓縮字典。是一個字節序列,其中包含用戶認為要壓縮的數據中可能頻繁出現的子序列。頻率高的子序列應當放在字典的尾部。
除了壓縮和解壓縮,zlib還提供了兩個數據校驗的函數,
| 函數 | 算法 | |
|---|---|---|
| zlib.adler32 | Adler-32校驗 | |
| zlib.crc32 | CRC(循環冗余)校驗 |
二者均輸入數據和校驗起始值,校驗起始值value默認為1。這兩個函數僅為驗證數據的正確性,均無加密強度,不適合做密碼。
>>> zlib.adler32(b'abcdefghijk') 434701411 >>> zlib.crc32(b'abcdefghijk') 3461812127
字符串:使用zlib.compress可以壓縮字符串。使用zlib.decompress可以解壓字符串。
數據流:壓縮:compressobj,解壓:decompressobj
示例代碼:
import zlib data = 'abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz' \ 'abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz' print(len(data)) print(data) # 壓縮 compressed_data = zlib.compress(data.encode()) # 注意:這兒要以字節的形式傳入 print(len(compressed_data)) print(compressed_data) # 解壓 new_data = zlib.decompress(compressed_data).decode() print(len(new_data)) print(new_data)
運行結果:

示例代碼2:
import zlib
# 壓縮文件或數據
def compress_data(file, zip_file, level=9):
file = open(file, 'rb')
zip_file = open(zip_file, 'wb')
compress = zlib.compressobj(level)
data = file.read(1024)
while data:
zip_file.write(compress.compress(data))
data = file.read(1024)
zip_file.write(compress.flush())
file.close()
zip_file.close()
# 解壓文件或數據
def decompress_data(zip_file, new_file):
zip_file = open(zip_file, 'rb')
new_file = open(new_file, 'wb')
decompress = zlib.decompressobj()
data = zip_file.read(1024)
while data:
new_file.write(decompress.decompress(data))
data = zip_file.read(1024)
new_file.write(decompress.flush())
zip_file.close()
new_file.close()
if __name__ == '__main__':
file = 'text.txt'
zip_file = 'text_zip.txt'
compress_data(file, zip_file)
new_file = 'test_new.txt'
decompress_data(zip_file, new_file)
print('end!')運行結果:
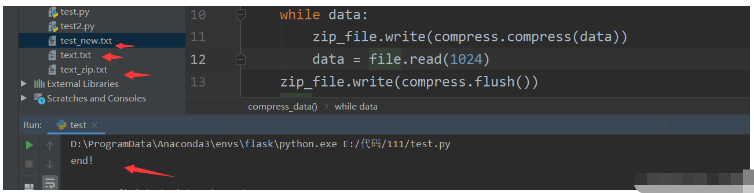
注意:
compressobj返回一個壓縮對象,用來壓縮不能一下子讀入內存的數據流。
level 從9到-1表示壓縮等級,其中1最快但壓縮度最小,9最慢但壓縮度最大,0不壓縮,默認是-1大約相當于與等級6,是一個壓縮速度和壓縮度適中的level。
關于“python壓縮和解壓縮模塊之zlib怎么使用”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“python壓縮和解壓縮模塊之zlib怎么使用”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





