溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python遺傳算法Geatpy工具箱怎么用的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Python遺傳算法Geatpy工具箱怎么用文章都會有所收獲,下面我們一起來看看吧。
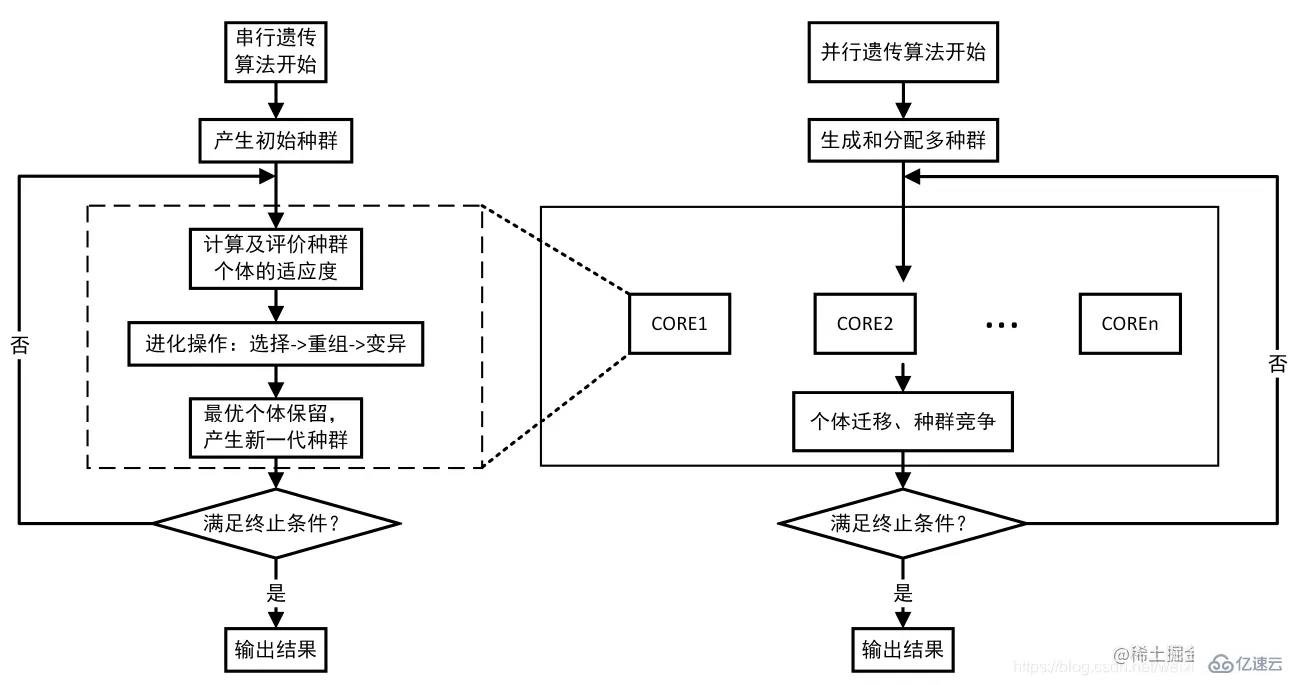
遺傳算法是仿真生物遺傳學和自然選擇機理,通過人工方式所構造的一類搜索算法,從某種程度上說遺傳算法是對生物進化過程進行的數學方式仿真。生物種群的生存過程普遍遵循達爾文進化準則,群體中的個體根據對環境的適應能力而被大自然所選擇或淘汰。進化過程的結果反映在個體的結構上,其染色體包含若干基因,相應的表現型和基因型的聯系體現了個體的外部特性與內部機理間邏輯關系。通過個體之間的交叉、變異來適應大自然環境。生物染色體用數學方式或計算機方式來體現就是一串數碼,仍叫染色體,有時也叫個體;適應能力是對應著一個染色體的一個數值來衡量;染色體的選擇或淘汰則按所面對的問題是求最大還是最小來進行。

API官方參考文檔
population參數【重要屬性:Chrom,Phen,Objv,CV,FitnV】
sizes : int - 種群規模,即種群的個體數目。
ChromNum : int - 染色體的數目,即每個個體有多少條染色體。
Encoding : str - 染色體編碼方式, 'BG':二進制/格雷編碼; 'RI':實整數編碼,即實數和整數的混合編碼; 'P':排列編碼
Field : array - 譯碼矩陣
Chrom : array - 種群染色體矩陣,每一行對應一個個體的一條染色體。
Lind : int - 種群染色體長度。
ObjV : array - 種群目標函數值矩陣,每一行對應一個個體的目標函數值,每一列對應一個目標
FitnV : array - 種群個體適應度列向量,每個元素對應一個個體的適應度,最小適應度為0
CV : array - CV(Constraint Violation Value)是用來定量描述違反約束條件程度的矩陣,每行對應一個個體,每列對應一個約束
Phen : array - 種群表現型矩陣(即種群各染色體解碼后所代表的決策變量所組成的矩陣)。
如果通過CV矩陣基于可行性法則進行約束的設置,那么 不等式約束需要 ≤,等式約束 需要傳入abs( ) (因為遵循值越大,適應度越小的原則)
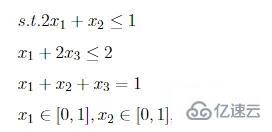

ea.Problem.init()中的lbin與ubin(決策變量范圍邊界矩陣)表示范圍區間的開閉,1閉合0開區間
Geatpy 結果參數介紹
success: True or False, 表示算法是否成功求解。
stopMsg: 存儲著算法停止原因的字符串。
optPop: 存儲著算法求解結果的種群對象。如果無可行解,則optPop.sizes=0。optPop.Phen為決策變量矩陣,optPop.ObjV為目標函數值矩陣。
lastPop: 算法進化結束后的最后一代種群對象。
Vars: 等于optPop.Phen,此處即最優解。若無可行解,則Vars=None。
ObjV: 等于optPop.ObjV,此處即最優解對應的目標函數值。若無可行解,ObjV=None。
CV: 等于optPop.CV,此處即最優解對應的違反約束程度矩陣。若無可行解,CV=None。
startTime: 程序執行開始時間。
endTime: 程序執行結束時間。
executeTime: 算法 所用時間。
nfev: 算法評價次數
gd: (多目標優化且給定了理論最優解時才有) GD指標值。
igd: (多目標優化且給定了理論最優解時才有) IGD指標值。
hv: (多目標優化才有) HV指標值。
spacing: (多目標優化才有) Spacing指標值。

解集:
header_regex = '|'.join(['{}'] * len(headers))
header_str = header_regex.format(*[str(key).center(width) for key, width in zip(headers, widths)])
print("=" * len(header_str))
print(header_str)
print("-" * len(header_str))
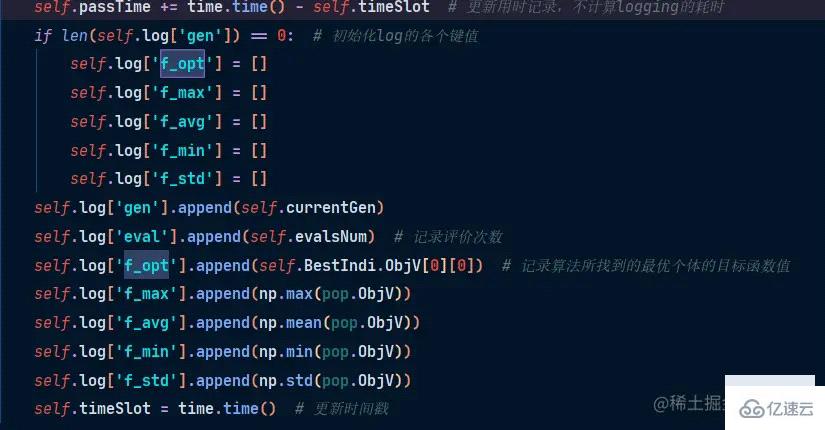
gen: 進化代數
eval:記錄評價次數
f\_opt: 當代最優個體的目標函數值
f\_max=當代種群最大函數值
f\_min 最小 f\_avg : 平均水平
f\_std: 標準約束水平

使用geatpy庫求解有向無環圖最短路
代碼【最短路】一:使用geatpy庫
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 繼承Problem父類
def __init__(self):
name = 'Shortest_Path' # 初始化name(函數名稱,可以隨意設置)
M = 1 # 初始化M(目標維數)
maxormins = [1] # 初始化maxormins(目標最小最大化標記列表,1:最小化該目標;-1:最大化該目標)
Dim = 10 # 初始化Dim(決策變量維數)
varTypes = [1] * Dim # 初始化varTypes(決策變量的類型,元素為0表示對應的變量是連續的;1表示是離散的)
lb = [0] * Dim # 決策變量下界
ub = [9] * Dim # 決策變量上界
lbin = [1] * Dim # 決策變量下邊界 1表示閉合區間,0表示開區間
ubin = [1] * Dim # 決策變量上邊界
# 調用父類構造方法完成實例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
# 設置每一個結點下一步可達的結點(結點從1開始數,因此列表nodes的第0號元素設為空列表表示無意義)
self.nodes = [[], [2, 3], [3, 4, 5], [5, 6], [7, 8], [4, 6], [7, 9], [8, 9], [9, 10], [10]]
# 設置有向圖中各條邊的權重
self.weights = {'(1, 2)': 36, '(1, 3)': 27, '(2, 4)': 18, '(2, 5)': 20, '(2, 3)': 13, '(3, 5)': 12,
'(3, 6)': 23,
'(4, 7)': 11, '(4, 8)': 32, '(5, 4)': 16, '(5, 6)': 30, '(6, 7)': 12, '(6, 9)': 38,
'(7, 8)': 20,
'(7, 9)': 32, '(8, 9)': 15, '(8, 10)': 24, '(9, 10)': 13}
def decode(self, priority): # 將優先級編碼的染色體解碼得到一條從節點1到節點10的可行路徑
edges = [] # 存儲邊
path = [1] # 結點1是路徑起點
while not path[-1] == 10: # 開始從起點走到終點
currentNode = path[-1] # 得到當前所在的結點編號
nextNodes = self.nodes[currentNode] # 獲取下一步可達的結點組成的列表
chooseNode = nextNodes[np.argmax(
priority[np.array(nextNodes) - 1])] # 從NextNodes中選擇優先級更高的結點作為下一步要訪問的結點,因為結點從1數起,而下標從0數起,因此要減去1
path.append(chooseNode)
edges.append((currentNode, chooseNode))
return path, edges
def aimFunc(self, pop): # 目標函數
pop.ObjV = np.zeros((pop.sizes, 1)) # 初始化ObjV
for i in range(pop.sizes): # 遍歷種群的每個個體,分別計算各個個體的目標函數值
priority = pop.Phen[i, :]
path, edges = self.decode(priority) # 將優先級編碼的染色體解碼得到訪問路徑及經過的邊
pathLen = 0
for edge in edges:
key = str(edge) # 根據路徑得到鍵值,以便根據鍵值找到路徑對應的長度
if not key in self.weights:
raise RuntimeError("Error in aimFunc: The path is invalid. (當前路徑是無效的。)", path)
pathLen += self.weights[key] # 將該段路徑長度加入
pop.ObjV[i] = pathLen # 計算目標函數值,賦值給pop種群對象的ObjV屬性
## 執行腳本
if __name__ == "__main__":
# 實例化問題對象
problem = MyProblem()
# 構建算法
algorithm = ea.soea_EGA_templet(problem,
ea.Population(Encoding='RI', NIND=4),
MAXGEN=10, # 最大進化代數
logTras=1) # 表示每隔多少代記錄一次日志信息
# 求解
res = ea.optimize(algorithm, verbose=True, drawing=1, outputMsg=False, drawLog=False, saveFlag=True,
dirName='result')
print('最短路程為:%s' % (res['ObjV'][0][0]))
print('最佳路線為:')
best_journey, edges = problem.decode(res['Vars'][0])
for i in range(len(best_journey)):
print(int(best_journey[i]), end=' ')
print()關于“Python遺傳算法Geatpy工具箱怎么用”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Python遺傳算法Geatpy工具箱怎么用”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





