溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文小編為大家詳細介紹“Python有關Unicode UTF-8 GBK編碼問題怎么解決”,內容詳細,步驟清晰,細節處理妥當,希望這篇“Python有關Unicode UTF-8 GBK編碼問題怎么解決”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
Unicode也叫萬國碼、單一碼,是計算機科學領域里的一項業界標準,包括字符集、編碼方案等。對于世界上所有的語言文字再unicode中都可以查看到。
unicode編碼就是為了統一世界上的編碼,有一個統一的規范。但是它還存在一些問題。
Unicode的問題
需要注意的是,Unicode只是一個符號集,它只規定了符號的二進制代碼,卻沒有規定這個二進制代碼應該如何存儲。
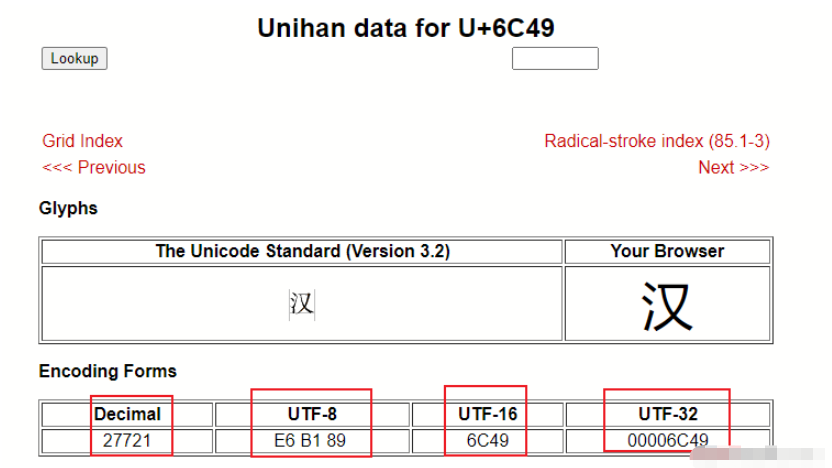
比如,漢字“嚴”的unicode是十六進制數4E25,轉換成二進制數足足有15位(100111000100101),也就是說這個符號的表示至少需要2個字節。表示其他更大的符號,可能需要3個字節或者4個字節,甚至更多。
這里就有兩個嚴重的問題
第一個:如何才能區別unicode和ascii?計算機怎么知道三個字節表示一個符號,而不是分別表示三個符號呢?
第二個:我們已經知道,英文字母只用一個字節表示就夠了,如果unicode統一規定,每個符號用三個或四個字節表示,那么每個英文字母前都必然有二到三個字節是0,這對于存儲來說是極大的浪費,文本文件的大小會因此大出二三倍,這是無法接受的。
它們造成的結果是:
出現了unicode的多種存儲方式,也就是說有許多種不同的二進制格式,可以用來表示unicode。
unicode在很長一段時間內無法推廣,直到互聯網的出現。
互聯網的普及,強烈要求出現一種統一的編碼方式。UTF-8就是在互聯網上使用最廣的一種unicode的實現方式。其他實現方式還包括UTF-16和UTF-32,不過在互聯網上基本不用。重復一遍,這里的關系是,UTF-8是Unicode的實現方式之一。
UTF-8最大的一個特點,就是它是一種變長的編碼方式。它可以使用1~4個字節表示一個符號,根據不同的符號而變化字節長度。
UTF-8的編碼規則很簡單,只有二條:
對于單字節的符號,字節的第一位設為0,后面7位為這個符號的unicode碼。因此對于英語字母,UTF-8編碼和ASCII碼是相同的。
對于n字節的符號(n>1),第一個字節的前n位都設為1,第n+1位設為0,后面字節的前兩位一律設為10。剩下的沒有提及的二進制位,全部為這個符號的unicode碼。
下表總結了編碼規則,字母x表示可用編碼的位。
Unicode符號范圍 | UTF-8編碼方式
(十六進制) | (二進制)
--------------------±--------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Python代碼舉例:
a = '\u6c49' # 漢的unicode編碼
print(a)
a = '漢'
print("漢字utf8格式:",a.encode('utf8'))
print('漢字unicode格式:',a.encode('unicode_escape'))
print('漢字gbk格式:',a.encode('gbk'))
print('漢字gb2312格式:',a.encode('gb2312'))
# 輸出結果
漢
漢字utf8格式: b'\xe6\xb1\x89'
漢字unicode格式: b'\\u6c49'
漢字gbk格式: b'\xba\xba'
漢字gb2312格式: b'\xba\xba'可以看到以上結果,漢字的漢通過print打印時用的是unicode編碼,存儲時使用utf8,也即是我們保存文件時常用的編碼
with open('xxx.txt','w',encoding='utf-8') as f:
f.write(xxx)打開的時候也要指定文件編碼
with open(file_path, encoding='utf-8') as f: f.read()
當使用gbk編碼保存的文件使用utf8打開時會報錯,使用gbk打開即可
with open(r'gbk.txt','r',encoding='utf8') as f: print(f.read()) (result, consumed) = self._buffer_decode(data, self.errors, final) UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte
讀到這里,這篇“Python有關Unicode UTF-8 GBK編碼問題怎么解決”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





