溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“python yml文件讀寫與xml文件讀寫怎么實現”,在日常操作中,相信很多人在python yml文件讀寫與xml文件讀寫怎么實現問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”python yml文件讀寫與xml文件讀寫怎么實現”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
使用庫 :import yaml
安裝:
pip install pyyaml
示例:
文件config2.yml
guard_url : 'https://www.xxxx.com' app : chrome_files : 'C:\Program Files\Google\Chrome\Application\chrome.exe' networkTime : 30 title : '公司'
讀取yml數據
def read_yml(file): """讀取yml,傳入文件路徑file""" f = open(file,'r',encoding="utf-8") # 讀取文件 yml_config = yaml.load(f,Loader=yaml.FullLoader) # Loader為了更加安全 """Loader的幾種加載方式 BaseLoader - -僅加載最基本的YAML SafeLoader - -安全地加載YAML語言的子集。建議用于加載不受信任的輸入。 FullLoader - -加載完整的YAML語言。避免任意代碼執行。這是當前(PyYAML5.1)默認加載器調用yaml.load(input)(發出警告后)。 UnsafeLoader - -(也稱為Loader向后兼容性)原始的Loader代碼,可以通過不受信任的數據輸入輕松利用。""" return yml_config
打印yml內容
yml_info=read_yml('config.yml')
print(yml_info['guard_url'])
print(yml_info['app'])
print((yml_info['app'])['chrome_files'])
"""
https:xxxx.com
{'chrome_files': 'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe'}
C:\Program Files\Google\Chrome\Application\chrome.exe
"""插入到yml數據
def write_yml(file,data):
# 寫入數據:
with open(file, "a",encoding='utf-8') as f:
# data數據中有漢字時,加上:encoding='utf-8',allow_unicode=True
f.write('\n') # 插入到下一行
yaml.dump(data, f, encoding='utf-8', allow_unicode=True)
data = {"S_data": {"test1": "hello"}, "Sdata2": {"name": "漢字"}}
write_yml('config2.yml',data=data)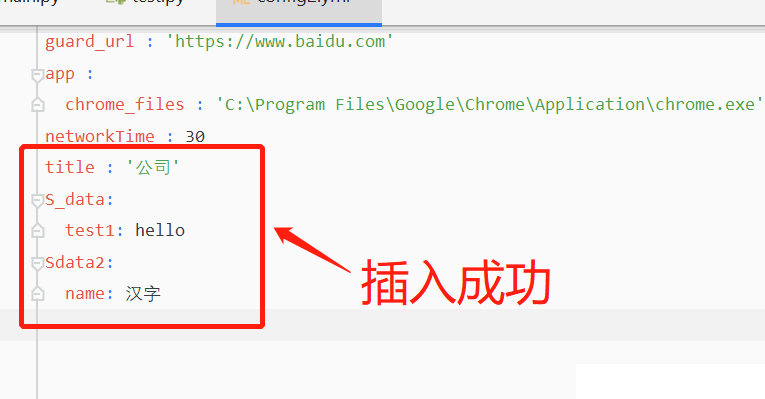
邏輯是完整讀取然后更新數值后在完整寫入。
def read_yml(file):
"""讀取yml,傳入文件路徑file"""
f = open(file, 'r', encoding="utf-8") # 讀取文件
yml_config = yaml.load(f, Loader=yaml.FullLoader) # Loader為了更加安全
return yml_config
def updata_yaml(file):
"""更新yml的數值"""
old_data=read_yml(file) #讀取文件數據
old_data['title']='仔仔大哥哥' #修改讀取的數據(
with open(file, "w", encoding="utf-8") as f:
yaml.dump(old_data,f,encoding='utf-8', allow_unicode=True)
updata_yaml('config2.yml')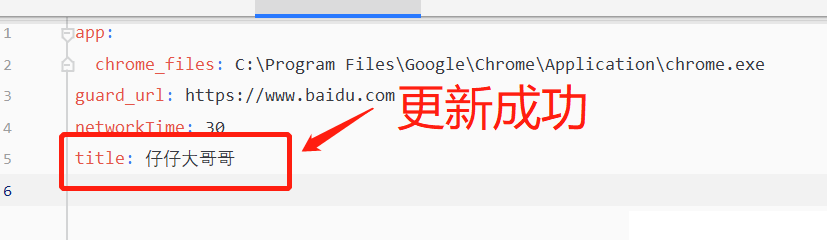
使用庫 :import xml
安裝:系統自帶
示例:
如果只是配置文件盡量使用yml來讀寫,
讀取xml文件:
config.xml
<config> <id>905594711349653</id> <sec>0tn1jeerioj4x6lcugdd8xmzvm6w42tp</sec> </config>
import xml.dom.minidom
dom = xml.dom.minidom.parse('config.xml')
root = dom.documentElement
def xml(suser):
suser = root.getElementsByTagName(suser)
return suser[0].firstChild.data
id = xml('id') # 進程名
print("打印ID:"+id)
"""
打印ID:905594711349653
"""進階country_data.xml
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank>1</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank>4</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank>68</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
這里產生的 root 是一個 Element 物件,代表 XML 的根節點,每一個 Element 物件都有 tag 與 attrib 兩個屬性:
import xml.etree.ElementTree as ET
# 從文件加載并解析 XML 數據
tree = ET.parse('country_data.xml')
root = tree.getroot()
print(root.tag) # 打印根節點名稱
print(root.attrib) # 打印根節點屬性
# for 循環可以列出所有的子節點:
# 子節點與屬性
for child in root:
print(child.tag, child.attrib)
"""
data
{} # data 沒有屬性所以返回空
country {'name': 'Liechtenstein'}
country {'name': 'Singapore'}
country {'name': 'Panama'}
"""
也可以使用索引的方式存取任意的節點,透過 text 屬性即可取得節點的內容:
print(root[0][1].text) """ 2008 """
可透過 get 直接取得指定的屬性值:
# 取得指定的屬性值
print(root[0][3].get('name'))
"""
Austria
"""iter 可以在指定節點之下,以遞回方式搜索所有子節點:
# 搜索所有子節點
for neighbor in root.iter('neighbor'):
print(neighbor.attrib)
"""
{'name': 'Austria', 'direction': 'E'}
{'name': 'Switzerland', 'direction': 'W'}
{'name': 'Malaysia', 'direction': 'N'}
{'name': 'Costa Rica', 'direction': 'W'}
{'name': 'Colombia', 'direction': 'E'}
"""findall 與 find 則是只從第一層子節點中搜索(不包含第二層以下),findall 會傳回所有結果,而 find 則是只傳回第一個找到的節點:
# 只從第一層子節點中搜索,傳回所有找到的節點
for country in root.findall('country'):
# 只從第一層子節點中搜索,傳回第一個找到的節點
rank = country.find('rank').text
# 取得節點指定屬性質
name = country.get('name')
print(name, rank)
"""
Liechtenstein 1
Singapore 4
Panama 68
"""XML 節點的數據可以透過 Element.text 來修改,而屬性值則可以使用 Element.set() 來指定,若要將修改的結果寫入 XML 文件,則可使用 ElementTree.write():
# 尋找 rank 節點
for rank in root.iter('rank'):
# 將 rank 的數值加 1
new_rank = int(rank.text) + 1
# 設置新的 rank 值
rank.text = str(new_rank)
# 增加一個 updated 屬性值
rank.set('updated', 'yes')
# 寫入 XML 文件
tree.write('output.xml')編輯之后的 XML 文件內容會像這樣:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
若要移除 XML 的節點,可以使用 Element.remove():
# 在第一層子節點鐘尋找 country 節點
for country in root.findall('country'):
# 取得 rank 數值
rank = int(country.find('rank').text)
# 若 rank 大于 50,則移除此節點
if rank > 50:
root.remove(country)
# 寫入 XML 文件
tree.write('output.xml')移除節點之后的 XML 文件內容會像這樣:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> </data>
若要建立一個全新的 XML 結構,可以使用 Element 建立根節點,再以 SubElement() 加入子節點:
# 建立新的 XML 結構
orders = ET.Element('orders')
# 新增節點
order1 = ET.SubElement(orders, 'order')
order1.text = "My Order 1"
order1.set("new", "yes")
# 新增節點
order2 = ET.SubElement(orders, 'order')
order2.text = "My Order 2"
order2.set("new", "no")
# 輸出 XML 原始數據
ET.dump(orders)
<orders><order new="yes">My Order 1</order><order new="no">My Order 2</order></orders>XPath 可以讓用戶在 XML 結構中以較復雜的條件進行搜索,以下是一些常見的范例。
# 頂層節點
root.findall(".")
# 尋找「頂層節點 => country => neighbor」這樣結構的節點
root.findall("./country/neighbor")
# 尋找 name 屬性為 Singapore,且含有 year 子節點的節點
root.findall(".//year/..[@name='Singapore']")
# 尋找父節點 name 屬性為 Singapore 的 year 節點
root.findall(".//*[@name='Singapore']/year")
# 尋找在同一層 neighbor 節點中排在第二位的那一個
root.findall(".//neighbor[2]")若要對一般的 XML 文件內容進行自動排版,可以使用 lxml 模組的 etree:
import lxml.etree as etree
# 讀取 XML 文件
root = etree.parse("country_data.xml")
# 輸出排版的 XML 數據
print(etree.tostring(root, pretty_print=True, encoding="unicode"))
# 將排版的 XML 數據寫入文件
root.write("pretty_print.xml", encoding="utf-8")到此,關于“python yml文件讀寫與xml文件讀寫怎么實現”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





