溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“C語言整形數據存儲實例分析”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“C語言整形數據存儲實例分析”吧!
C語言中存在著數據類型,我們或多或少都見到過。
char //字符數據類型 - 1個字節
short //短整型 - 2個字節
int //整形 - 4個字節
long //長整型 - 4/8個字節
long long //更長的整形 - 8個字節
float //單精度浮點數 - 4個字節
double //雙精度浮點數 - 8個字節
小思考:C語言有沒有字符串類型?
C語言有字符串,表示為"字符串內容"的形式,但不存在字符串類型。
類型存在的意義是什么?
使用這個類型開辟內存空間的大小(大小決定使用范圍)。
如何看待內存空間的視角(例如指針解引用和指針運算)。
整形
char
unsigned char
signed char
//雖然是字符類型,但是字符類型存儲的時候,存儲的字符的ascii碼值,ascii碼值是整數
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
unsigned 和 signed
unsigned:無符號,只有正數的數據可以存放在無符號的變量中。
signed:有符號,有正負的數據可以存放在有符號的變量中。
Tips:
對于short,int,long,long long數據在進行定義時,默認都為signed。而對于char類型則不確定,C語言標準沒有規定char是否有符號,取決于編譯器,所以char實際上可以歸為3類,char(不確定),signed char(有符號),unsigned char(無符號)。在vs2022中,char默認為signed char。
浮點型
float//單精度浮點數 - 4個字節
double//雙精度浮點數 - 8個字節
構造類型
//例:int arr[10]
數組類型 int [10]
//數組只要個數和元素類型發生變化,類型都會發生變化
結構體類型 struct
枚舉類型 enum
聯合類型 union
指針類型
int *pi;//整形指針
char *pc;//字符指針
float* pf;//單精度浮點數指針
void* pv;//空類型指針
空類型
void 表示空類型(無類型)
通常應用于函數的返回類型、函數的參數、指針類型。
例:
void test1()//無返回值
{}
void test2(void)//函數接收參數,參數部分加void
{}
int main()
{
void* p = NULL;
//void*可以存放任何類型的指針
int a = 10;
void* p1 = &a;//沒問題
p1++;//err,不知道類型,無法決定跳過幾個字節
*p1;//err,不知道類型,無法決定解引用的權限
//一般用來臨時存放地址,用的時候拿走或者強轉使用
return 0;
}一個整形變量的創建需要再內存中開辟四個字節,那整形在內存中是如何存儲的?
比如:
int a = 10;
int b = -10;
在了解整形在內存中如何存儲之前我們需要了解以下概念:
計算機中的整數有三種2進制表示方法,即原碼、反碼、補碼。
三種表示方法均有符號位和數值位兩部分,二進制序列的第一位為符號位,其他均為數值位,符號位數值位均由0,1組成。
原碼:
直接將數值按照正負的形式翻譯成二進制就可以。
反碼:
原碼的符號位不便,其他位依次按位取反就可以得到。
補碼:
反碼 + 1得到補碼。
注意:
正整數的原碼、反碼、補碼都相同。
負整數的三種表示方式各不相同,需要通過計算得到。
樣例:
int a = 10;//整形值 //0000 0000 0000 0000 0000 0000 0000 1010 a的原、反、補 //轉化為16進制:0X0000000a int b = -10;//整形值 //1000 0000 0000 0000 0000 0000 0000 1010 b的原碼 //1111 1111 1111 1111 1111 1111 1111 0101 b的反碼 //1111 1111 1111 1111 1111 1111 1111 0110 b的補碼 //轉化為16進制:0Xfffffff6
那么對于整形而言,在內存中存儲的是什么呢?
讓我們啟動調試,查看內存:
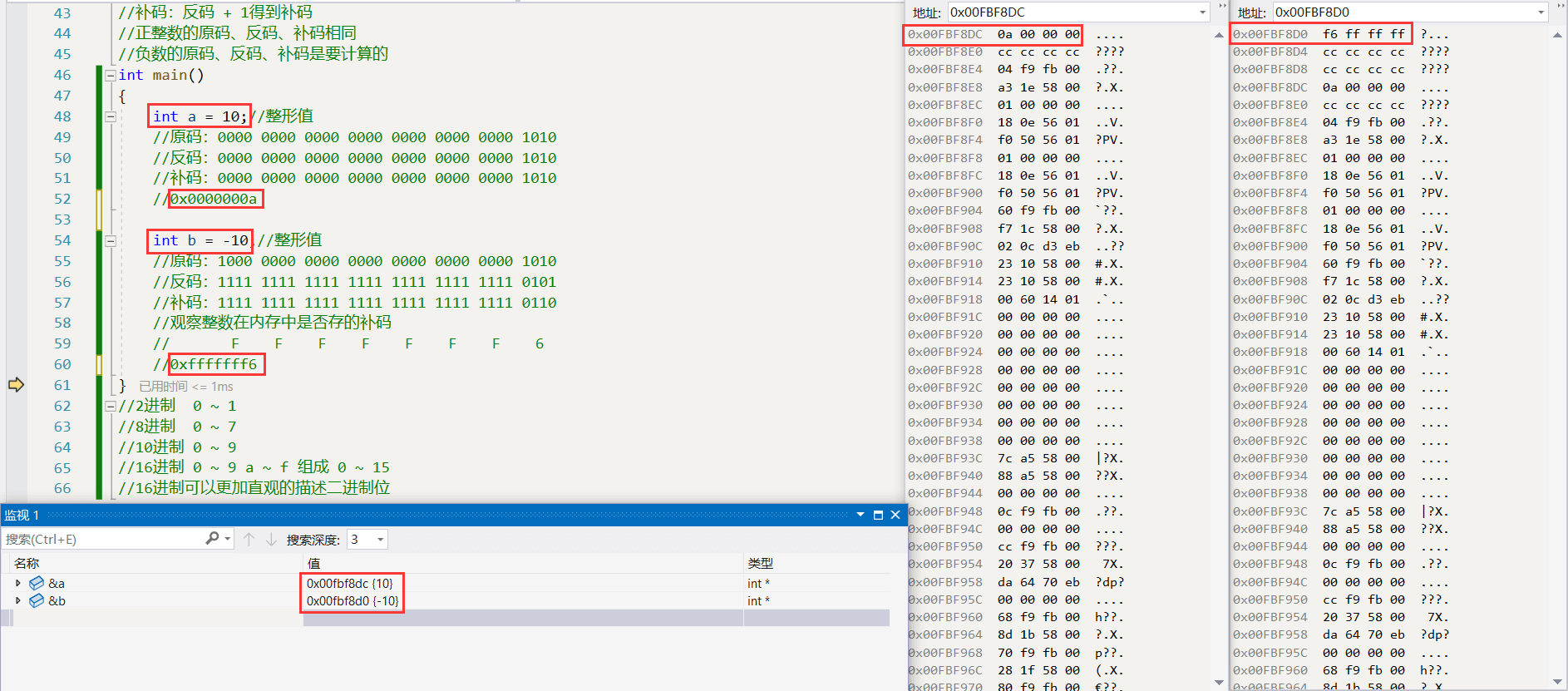
我們可以看到對于a和b分別存儲的是補碼,這是為什么?
在計算機系統中,數值一律用補碼來表示和存儲。原因在于,使用補碼,可以將符號位和數值域統一處理;
同時,加法和減法也可以統一處理(CPU只有加法器)此外,補碼與原碼相互轉換,其運算過程是相同的,不需要額外的硬件電路。
舉個簡單的例子,例如計算機在計算a - b的時候,會轉化成a + (-b)的形式進行計算,而這時使用原碼來進行計算,是無法計算出結果的,但使用補碼就可以計算出結果。
但是對于數據在內存中存儲的方式很奇怪,它是倒著存儲的,這是為什么?讓我們了解一下大小端。
什么是大端小端:
大端字節序存儲:把一個數據低位字節處的數據存放在高地址處,把高位字節處的數據放在低地址處
小端字節序存儲:把一個數據低位字節處的數據存放在低地址處,把高位字節處的數據放在高地址處。
例如:
0x11223344

為什么會有大端和小端:
為什么會有大小端模式之分呢?這是因為在計算機系統中,我們是以字節為單位的,每個地址單元都對應著一個字節,一個字節為8 bit。但是在C語言中除了8 bit的char之外,還有16 bit的short型,32 bit的long型(要看具體的編譯器),另外,對于位數大于8位的處理器,例如16位或者32位的處理器,由于寄存器寬度大于一個字節,那么必然存在著一個如何將多個字節安排的問題。因此就導致了大端存儲模式和小端存儲模式。
例如:一個16bit 的short 型x ,在內存中的地址為0x0010 , x 的值為0x1122 ,那么0x11 為高字節, 0x22 為低字節。對于大端模式,就將0x11 放在低地址中,即0x0010 中, 0x22 放在高地址中,即0x0011 中。小端模式,剛好相反。我們常用的X86 結構是小端模式,而KEIL C51 則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以由硬件來選擇是大端模式還是小端模式。
其實數據在內存中無論是大小端存儲或者亂序存儲都可以,大小端字節序存儲也是為了讓存儲方式變得更簡單,如果亂序存儲的話在還原數據時會更加復雜。
注:大小端存儲時以字節為單元,16進制的兩位為一個字節,為一個單元,按照大小端存儲規律存儲,并不會將16進制的每一位都倒過來存儲。例如0x123456按照小端存儲就為56 34 12 00,而不是65 43 21 00。
所以說大小端字節序存儲,就是以字節為單位的存儲順序。
一道筆試題
請簡述大端字節序和小端字節序的概念,設計一個小程序來判斷當前機器的字節序。
思路:數據在內存中是通過補碼的形式儲存的,判斷大端還是小端,例如數字1,我們只需要觀察它的第一個字節為0或1,就可以判斷字節序。而數據類型決定了指針解引用時看待內存的視角,所以我們可以用char*指針來對元素第一個字節的內容進行解引用。
int check_sys()
{
int a = 1;
//二進制:0000 0000 0000 0000 0000 0000 0000 0001
//十六進制:0x00000001
char* p = (char*)&a;//char*指針解引用為一個字節
if (*p == 1)
return 1;
else
return 0;
}
//簡化
//int check_sys()
//{
// int a = 1;
// return *(char*)&a;//1的大端或小端存儲,第一位為00或者01,取出的值正好和main函數中接收的值相同,直接返回
//}
int main()
{
int ret = check_sys();
if (ret = 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
}char在內存中存儲的是字符的Ascii碼值,所以也歸于整形。但是它的取值范圍和整形不同。
char類型變量的大小為1個byte,也就是8個bit位,對于char類型,我們分signed和unsigned兩塊進行講解。
signed:
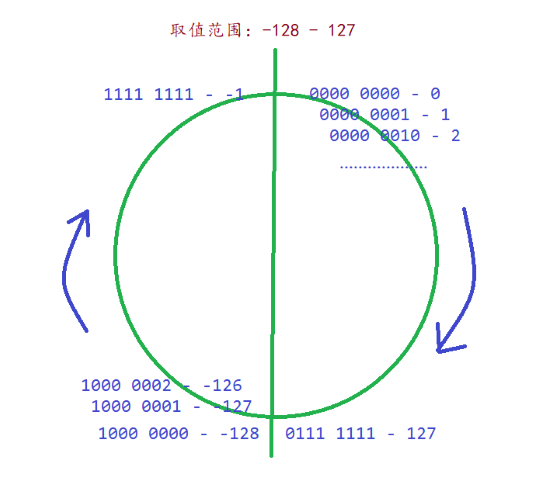
signed為有符號字符類型,二進制序列的第一位為符號位,其他位為數據位,取值范圍為-128 ~ 127.
unsigned:
unsigned為無符號字符類型,二進制序列全為數據位,取值范圍為0 ~ 255.
圖例:

下列程序的輸出結果是什么?
int main()
{
char a = -1;
//整形提升
//1000 0000 0000 0000 0000 0000 0000 0001
//1111 1111 1111 1111 1111 1111 1111 1110
//1111 1111 1111 1111 1111 1111 1111 1111
//截斷:1111 1111
//整形提升
//1111 1111 1111 1111 1111 1111 1111 1111 - 補碼
//1000 0000 0000 0000 0000 0000 0000 0000
//1000 0000 0000 0000 0000 0000 0000 0000 - 原碼
//-1
signed char b = -1;
//求解過程和a相同
unsigned char c = -1;
//截斷:1111 1111
//無符號字符,整形提升,高位補0
//0000 0000 0000 0000 0000 0000 1111 1111 - 補碼==原碼
//截斷:1111 1111
printf("a=%d,b=%d,c=%d", a, b, c);//-1,-1,255
//當打印a,b,c時,要整形提升
return 0;
}運行結果:

下列程序的輸出結果是什么?
int main()
{
char a = -128;
//1000 0000 0000 0000 0000 0000 1000 0000
//1111 1111 1111 1111 1111 1111 0111 1111
//1111 1111 1111 1111 1111 1111 1000 0000
//截斷:1000 0000
//%u - 指的是打印無符號整數
//整形提升
//有符號字符,補符號位
//1111 1111 1111 1111 1111 1111 1000 0000 - 要打印原碼,而這是無符號數,所以這個就是原碼
printf("%u\n", a);//4294967168
return 0;
}運行結果:

下列程序的輸出結果是什么?
int main()
{
char a = 128;
//0000 0000 0000 0000 0000 0000 1000 0000
//1111 1111 1111 1111 1111 1111 0111 1111
//1111 1111 1111 1111 1111 1111 1000 0000
//截斷1000 0000
//整形提升
//有符號字符,補符號位
//1111 1111 1111 1111 1111 1111 1000 0000 - 原碼
printf("%u\n", a);//?
return 0;
}運行結果:

下列程序的輸出結果是什么?
int main()
{
int i = -20;
//1000 0000 0000 0000 0000 0000 0001 0100 - 原碼
//1111 1111 1111 1111 1111 1111 1110 1011 - 反碼
//1111 1111 1111 1111 1111 1111 1110 1100 - 補碼
unsigned int j = 10;
//0000 0000 0000 0000 0000 0000 0000 1010 - 補碼
printf("%d\n", i + j);//-10
//i + j
//1111 1111 1111 1111 1111 1111 1111 0110 - 補碼
//打印有符號整形,轉化成原碼
//1000 0000 0000 0000 0000 0000 0000 1001
//1000 0000 0000 0000 0000 0000 0000 1010 - 原碼
return 0;
}運行結果:

下列程序的輸出結果是什么?
int main()
{
unsigned int i;//恒大于0
for (i = 9; i >= 0; i--)//死循環
{
printf("%u\n", i);
//9 ~ 0 ~ 超大的值:-1的補碼組成的循環
//-1的補碼:1111 1111 1111 1111 1111 1111 1111 1111
//放到無符號整數中,將-1的補碼直接當做原碼輸出
//得到超大的值
Sleep(1000);//程序停止一秒
}
return 0;
}運行結果:

下列程序的輸出結果是什么?
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
//char取值范圍-128 ~ 127
//當a[i]的值小于-128時,會轉化成127并大于0的值,當a[i]=0時,
//'\0'的ascii碼值為0,當strlen進行計算時,計算第一個'\0'前的字符個數
//數組中元素:-1 , -2 , ... ,-128 , 127, ..., 1, 0...
}
printf("%d", strlen(a));
//求'\0'前字符的個數
//'\0'的ascii碼值為0
}圖解:
運行結果:

下列程序的輸出結果是什么?
unsigned char i = 0;//0 ~ 255
int main()
{
int i = 0;
//0 ~ 255為區間,循環進行這個區間,打印hello world
for (i = 0; i <= 255; i++)//死循環
{
printf("hello worrld\n");
}
}運行結果:

感謝各位的閱讀,以上就是“C語言整形數據存儲實例分析”的內容了,經過本文的學習后,相信大家對C語言整形數據存儲實例分析這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





