溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Node.js性能監控實例分析”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Node.js性能監控實例分析”吧!

Node作為Javascript在服務端的一個運行時(Runtime),極大的豐富了Javascript的應用場景。
但是Node.js Runtime本身是一個黑盒,我們無法感知運行時的狀態,對于線上問題也難以復現。
因此性能監控是Node.js應用程序「正常運行」的基石。不僅可以隨時監控運行時的各項指標,還可以幫助排查異常場景問題。
性能監控可以分為兩個部分:
性能指標的采集和展示
進程級別的數據:CPU,Memory,Heap,GC等
系統級別的數據:磁盤占用率,I/O負載,TCP/UDP連接狀態等
應用層的數據:QPS,慢HTTP,業務處理鏈路日志等
性能數據的抓取和分析
Heapsnapshot:堆內存快照
Cpuprofile:CPU快照
Coredump:應用崩潰快照
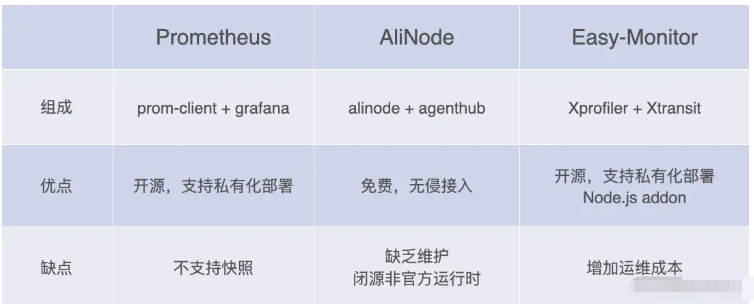
從上圖可以看到目前主流的三種Node.js性能監控方案的優缺點,以下是簡單介紹這三種方案的組成:
Prometheus
prom-client是prometheus的nodejs實現,用于采集性能指標
grafana是一個可視化平臺,用來展示各種數據圖表,支持prometheus的接入
只支持了性能指標的采集和展示,排查問題還需要其他快照工具,才能組成閉環
AliNode
整合了agentx + commdx的便利工具
v8的運行時內存狀態監控
libuv的運行時狀態監控
在線故障診斷功能:堆快照、CPU Profile、GC Trace等
alinode是一個兼容官方nodejs的拓展運行時,提供了一些額外功能:
agenthub是一個常駐進程,用來收集性能指標并上報
整體從監控,展示,快照,分析形成閉環,接入便捷簡單,但是拓展運行時還是有風險
Easy-Monitor
xprofiler 負責進行實時的運行時狀態采樣,以及輸出性能日志(也就是性能數據的抓取)
xtransit 負責性能日志的采集與傳輸
跟AliNode最大的區別在于使用了Node.js Addon來實現采樣器
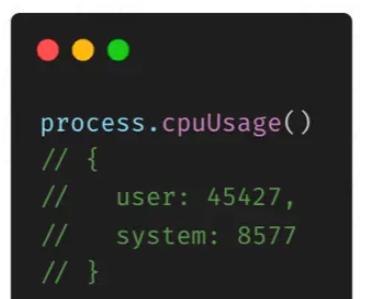
通過process.cpuUsage()可以獲取當前進程的CPU耗時數據,返回值的單位是微秒
user:進程執行時本身消耗的CPU時間
system:進程執行時系統消耗的CPU時間
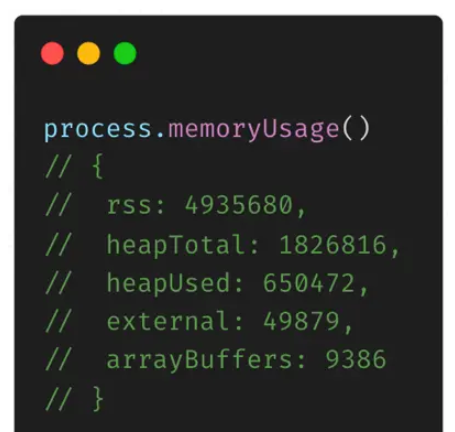
通過process.memoryUsage()可以獲取當前進程的內存分配數據,返回值的單位是字節
rss:常駐內存,node進程分配的總內存大小
heapTotal:v8申請的堆內存大小
heapUsed:v8已使用的堆內存大小
external:v8管理的C++所占用的內存大小
arrayBuffers:分配給ArrayBuffer的內存大小
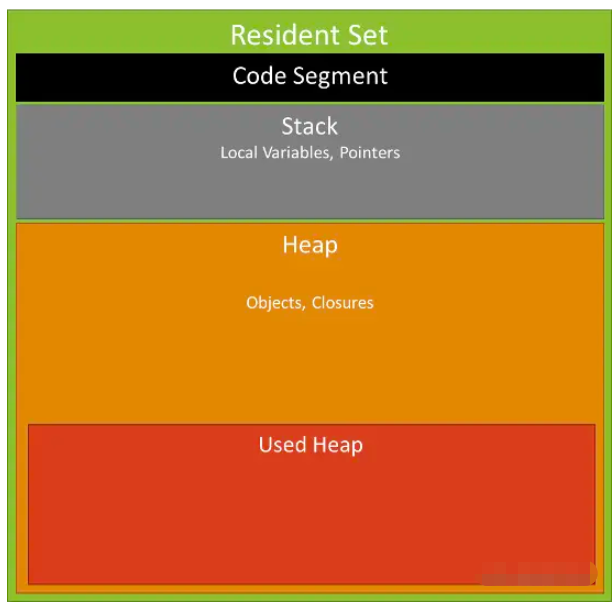
從上圖可以看出,rss包含代碼段(Code Segment)、棧內存(Stack)、堆內存(Heap)
Code Segment:存儲代碼段
Stack:存儲局部變量和管理函數調用
Heap:存儲對象、閉包、或者其他一切
通過v8.getHeapStatistics()和v8.getHeapSpaceStatistics()可以獲取v8堆內存和堆空間的分析數據,下圖展示了v8的堆內存組成分布:
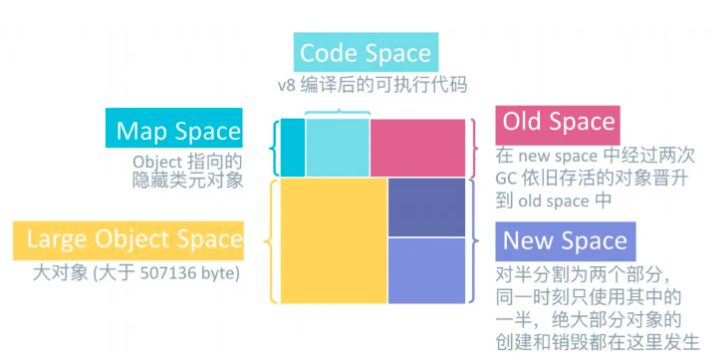
堆內存空間先劃分為空間(space),空間又劃分為頁(page),內存按照1MB對齊進行分頁。
New Space:新生代空間,用來存放一些生命周期比較短的對象數據,平分為兩個空間(空間類型為semi space):from space,to space
晉升條件:在New space中經過兩次GC依舊存活
Old Space:老生代空間,用來存放New Space晉升的對象
Code Space:存放v8 JIT編譯后的可執行代碼
Map Space:存放Object指向的隱藏類的指針對象,隱藏類指針是v8根據運行時記錄下的對象布局結構,用于快速訪問對象成員
Large Object Space:用于存放大于1MB而無法分配到頁的對象
v8的垃圾回收算法分為兩類:
Major GC:使用了Mark-Sweep-Compact算法,用于老生代的對象回收
Minor GC:使用了Scavenge算法,用于新生代的對象回收
前提:New space分為from和to兩個對象空間
觸發時機:當New space空間滿了
步驟:
在from space中,進行寬度優先遍歷
發現存活(可達)對象
已經存活過一次(經歷過一次Scavange),晉升到Old space
其他的復制到to space中
當復制結束時,to space中只有存活的對象,from space就被清空了
交換from space和to space,開始下一輪Scavenge
適用于回收頻繁,內存不大的對象,典型的空間換時間的策略,缺點是浪費了多一倍的空間
三個步驟:標記、清除、整理
觸發時機:當Old space空間滿了
步驟:
Marking(三色標記法)
白色:代表可回收對象
黑色:代表不可回收對象,且其所產生的引用都已經掃描完畢
灰色:代表不可回收對象,且其所產生的引用還沒掃描完
將V8根對象直接引用的對象放進一個marking queue(顯式棧)中,并將這些對象標記為灰色
從這些對象開始做深度優先遍歷,每訪問一個對象,將該對象從marking queue pop出來,并標記為黑色
然后將該對象引用下的所有白色對象標記為灰色,push到marking queue上,如此往復
直到棧上所有對象都pop掉為止,老生代的對象只剩下黑色(不可回收)和白色(可以回收)兩種了
PS:當一個對象太大,無法push到空間有限的棧時,v8會把這個對象保留灰色跳過,將整個棧標記為溢出狀態(overflowed),等棧清空后,再次進行遍歷標記,這樣導致需要額外掃描一遍堆
Sweep
清除白色對象
會造成內存空間不連續
Compact
由于Sweep會造成內存空間不連續,不利于新對象進入GC
把黑色(存活)對象移到Old space的一端,這樣清除出來的空間就是連續完整的
雖然可以解決內存碎片問題,但是會增加停頓時間(執行速度慢)
在空間不足以對新生代晉升過來的對象進行分配時才使用mark-compact
在最開始v8進行垃圾回收時,需要停止程序的運行,掃描完整個堆,回收完內存,才會重新運行程序。這種行為就叫全停頓(Stop-The-World)
雖然新生代活動對象較小,回收頻繁,全停頓,影響不大,但是老生代存活對象多且大,標記、清理、整理等造成的停頓就會比較嚴重。
增量回收(Incremental Marking):在Marking階段,當堆達到一定大小時,開始增量GC,每次分配了一定量的內存后,就暫停運行程序,做幾毫秒到幾十毫秒的marking,然后恢復程序的運行。
這個理念其實有點像React框架中的Fiber架構,只有在瀏覽器的空閑時間才會去遍歷Fiber Tree執行對應的任務,否則延遲執行,盡可能少地影響主線程的任務,避免應用卡頓,提升應用性能。
并發清除(Concurrent Sweeping):讓其他線程同時來做 sweeping,而不用擔心和執行程序的主線程沖突
并行清除(Parallel Sweeping):讓多個 Sweeping 線程同時工作,提升 sweeping 的吞吐量,縮短整個 GC 的周期
由于v8對于新老生代的空間默認限制了大小
New space 默認限制:64位系統為32M,32位系統為16M
Old space 默認限制:64位系統為1400M,32位系統為700M
因此node提供了兩個參數用于調整新老生代的空間上限
--max-semi-space-size:設置New Space空間的最大值
--max-old-space-size:設置Old Space空間的最大值
node也提供了三種查看GC日志的方式:
--trace_gc:一行日志簡要描述每次GC時的時間、類型、堆大小變化和產生原因
--trace_gc_verbose:展示每次GC后每個V8堆空間的詳細狀況
--trace_gc_nvp:每次GC的詳細鍵值對信息,包含GC類型,暫停時間,內存變化等
由于GC日志比較原始,還需要二次處理,可以使用AliNode團隊開發的v8-gc-log-parser
對于運行程序的堆內存進行快照采樣,可以用來分析內存的消耗以及變化
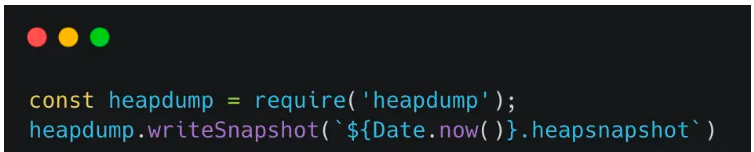
生成.heapsnapshot文件有以下幾種方式:
使用heapdump
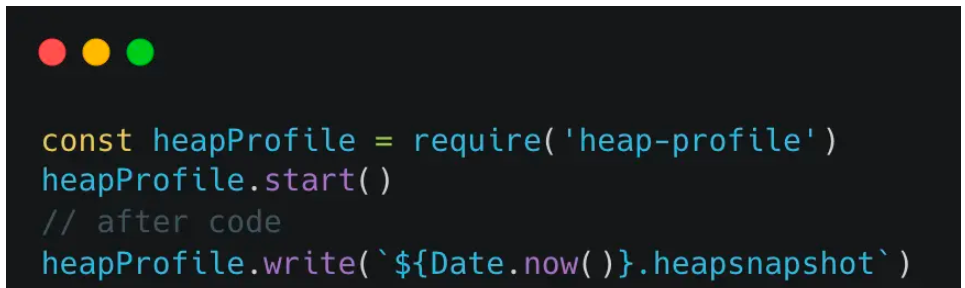
使用v8的heap-profile
使用nodejs內置的v8模塊提供的api


v8.writeHeapSnapshot(fileName)
v8.getHeapSnapshot()
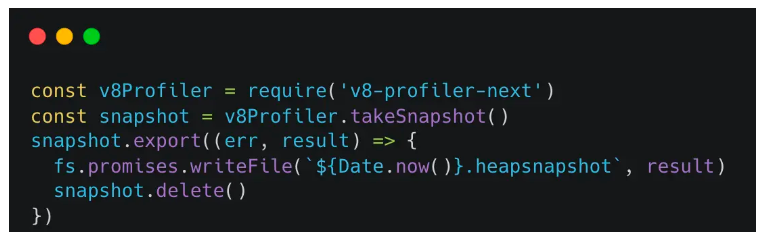
使用v8-profiler-next
生成的.heapsnapshot文件,可以在Chrome devtools工具欄的Memory,選擇上傳后,展示結果如下圖:
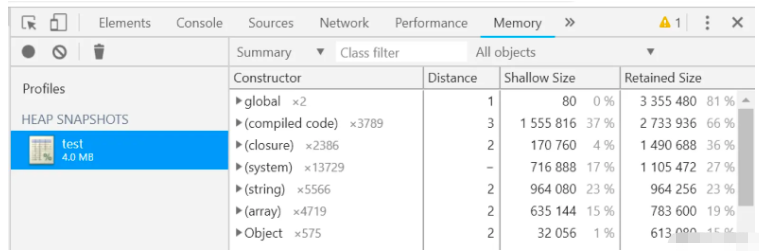
默認的視圖是Summary視圖,在這里我們要關注最右邊兩欄:Shallow Size 和 Retained Size
Shallow Size:表示該對象本身在v8堆內存分配的大小
Retained Size:表示該對象所有引用對象的Shallow Size之和
當發現Retained Size特別大時,該對象內部可能存在內存泄漏,可以進一步展開去定位問題
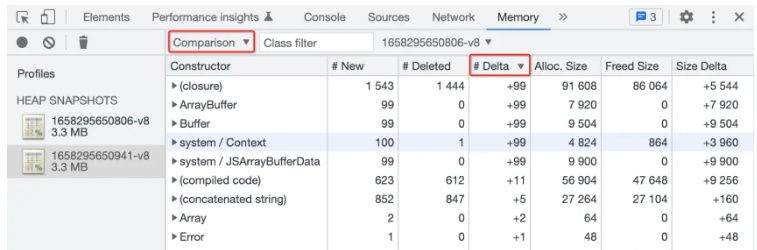
還有Comparison視圖是用于比較分析兩個不同時段的堆快照,通過Delta列可以篩選出內存變化最大的對象
對于運行程序的CPU進行快照采樣,可以用來分析CPU的耗時及占比
生成.cpuprofile文件有以下幾種方式:
v8-profiler(node官方提供的工具,不過已經無法支持node v10以上的版本,并不再維護)
v8-profiler-next(國人維護版本,支持到最新node v18,持續維護中)
這是采集5分鐘的CPU Profile樣例
生成的.cpuprofile文件,可以在Chrome devtools工具欄的Javascript Profiler(不在默認tab,需要在工具欄右側的更多中打開顯示),選擇上傳文件后,展示結果如下圖:
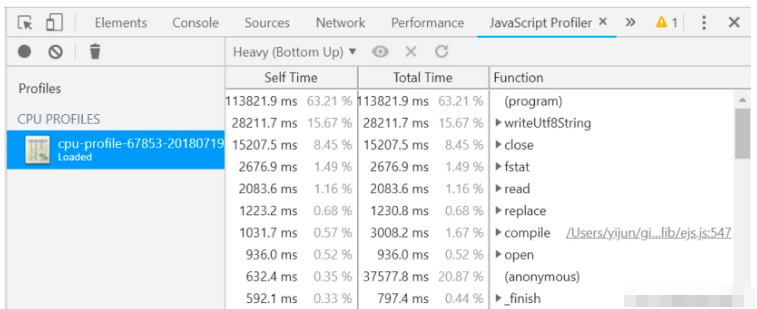
默認的視圖是Heavy視圖,在這里我們看到有兩欄:Self Time和Total Time
Self Time:代表此函數本身(不包含其他調用)的執行耗時
Total Time:代表此函數(包含其他調用函數)的總執行耗時
當發現Total Time和Self Time偏差較大時,該函數可能存在耗時比較多的CPU密集型計算,也可以展開進一步定位排查
當應用意外崩潰終止時,系統會自動記錄下進程crash掉那一刻的內存分配信息,Program Counter以及堆棧指針等關鍵信息來生成core文件
生成.core文件的三種方法:
ulimit -c unlimited打開內核限制
node --abort-on-uncaught-exceptionnode啟動添加此參數,可以在應用出現未捕獲的異常時也能生成一份core文件
gcore <pid>手動生成core文件
獲取.core文件后,可以通過mdb、gdb、lldb等工具實現解析診斷實際進程crash的原因
llnode `which node` -c /path/to/core/dump
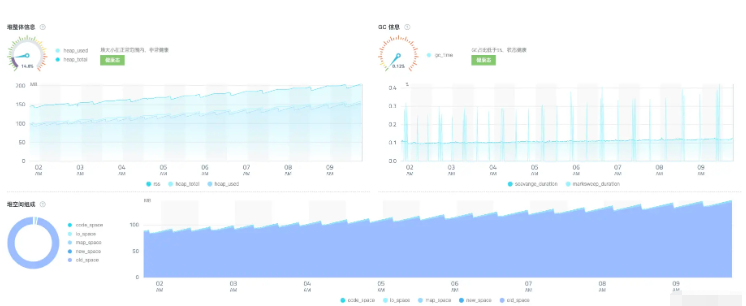
從監控可以觀察到堆內存在持續上升,因此需要堆快照進行排查

根據heapsnapshot可以分析排查到有一個newThing的對象一直保持著比較大的內存
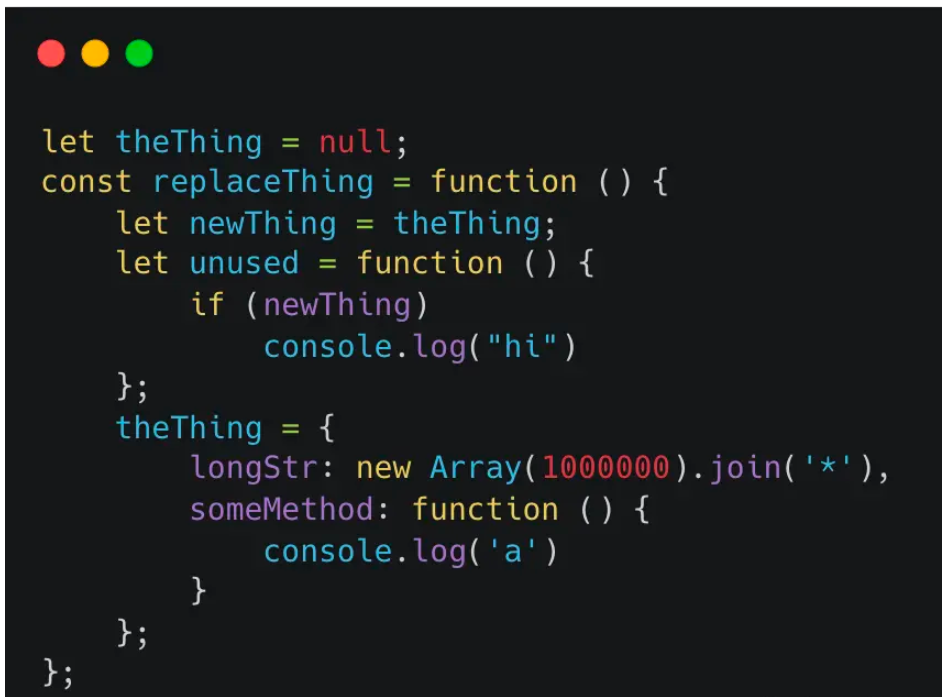
從代碼中可以看到雖然unused方法沒有調用,但是newThing對象是引用自theThing,導致其一直存在于replaceThing這個函數的執行上下文中,沒有被釋放,這就是典型的由于閉包產生的內存泄漏案例
常見的內存泄漏有以下幾種情況:
全局變量
閉包
定時器
事件監聽
緩存
因此在上述這幾種情況時,一定要謹慎考慮對象在內存中是否會被自動回收,不會被自動回收的話,需要手動進行回收,比如手動把對象設置為null、移除定時器、解綁事件監聽等
感謝各位的閱讀,以上就是“Node.js性能監控實例分析”的內容了,經過本文的學習后,相信大家對Node.js性能監控實例分析這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





