溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“pandas刪除部分數據后重新生成索引如何實現”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“pandas刪除部分數據后重新生成索引如何實現”文章能幫助大家解決問題。
在使用pandas時,由于隔行讀取刪除了部分數據,導致刪除數據后的索引不連續:
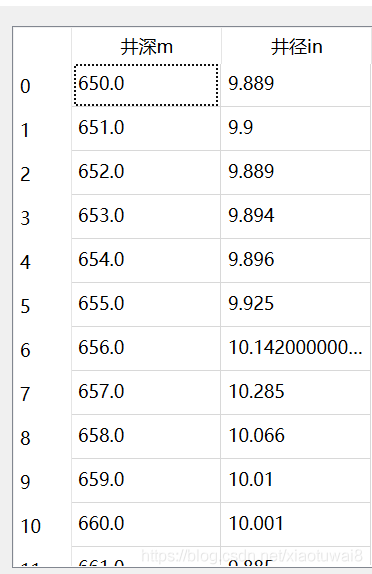
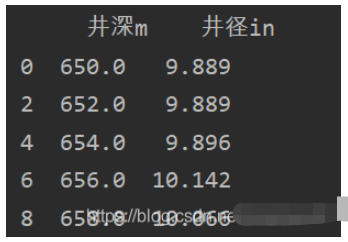
在綁定pyqt的tableview時需進行格式化,結果出現報錯:

主要原因是索引值不連續,所以無法格式化,需對刪除數據后的數據集進行重新索引,在格式化數據集之前加一句代碼:
new_biao = biao.reset_index(drop=True)
順利通過了編碼并顯示到tableview,問題解決。

class PandasModel(QtCore.QAbstractTableModel): """ Class to populate a table view with a pandas dataframe """ def __init__(self, data, parent=None): QtCore.QAbstractTableModel.__init__(self, parent) self._data = data def rowCount(self, parent=None): return len(self._data.values) def columnCount(self, parent=None): return self._data.columns.size def data(self, index, role=QtCore.Qt.DisplayRole): if index.isValid(): if role == QtCore.Qt.DisplayRole: return str(self._data.values[index.row()][index.column()]) return None def headerData(self, col, orientation, role): if orientation == QtCore.Qt.Horizontal and role == QtCore.Qt.DisplayRole: return self._data.columns[col] return None
使用:
model = PandasModel(your_pandas_data_frame) your_tableview.setModel(model)
很多情況下,我們的數據源是 CSV 文件。假設有一個名為的文件data.csv,包含以下數據。
date,temperature,humidity 07/01/21,95,50 07/02/21,94,55 07/03/21,94,56
默認情況下,pandas將會創建一個從0開始的索引行,如下:
>>> pd.read_csv("data.csv", parse_dates=["date"])
date temperature humidity
0 2021-07-01 95 50
1 2021-07-02 94 55
2 2021-07-03 94 56但是,我們可以在導入過程中通過將index_col參數設置為某一列可以直接指定索引列。
>>> pd.read_csv("data.csv", parse_dates=["date"], index_col="date")
temperature humidity
date
2021-07-01 95 50
2021-07-02 94 55
2021-07-03 94 56當然,如果已經讀取數據或做完一些數據處理步驟后,我們可以通過set_index手動設置索引。
>>> df = pd.read_csv("data.csv", parse_dates=["date"])
>>> df.set_index("date")
temperature humidity
date
2021-07-01 95 50
2021-07-02 94 55
2021-07-03 94 56這里有兩點需要注意下。
1.set_index方法默認將創建一個新的 DataFrame。如果要就地更改df的索引,需要設置inplace=True。
df.set_index(“date”, inplace=True)
2.如果要保留將要被設置為索引的列,可以設置drop=False。
df.set_index(“date”, drop=False)
在處理 DataFrame 時,某些操作(例如刪除行、索引選擇等)將會生成原始索引的子集,這樣默認的數字索引排序就亂了。如要重新生成連續索引,可以使用reset_index方法。
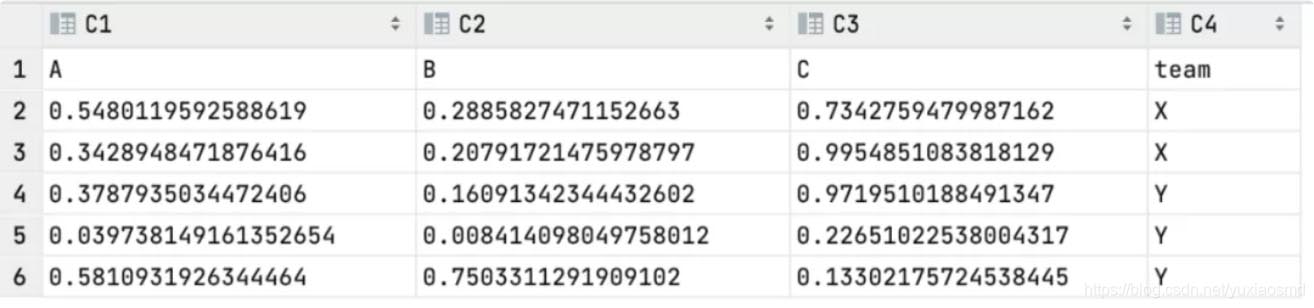
>>> df0 = pd.DataFrame(np.random.rand(5, 3), columns=list("ABC"))
>>> df0
A B C
0 0.548012 0.288583 0.734276
1 0.342895 0.207917 0.995485
2 0.378794 0.160913 0.971951
3 0.039738 0.008414 0.226510
4 0.581093 0.750331 0.133022
>>> df1 = df0[df0.index % 2 == 0]
>>> df1
A B C
0 0.548012 0.288583 0.734276
2 0.378794 0.160913 0.971951
4 0.581093 0.750331 0.133022
>>> df1.reset_index(drop=True)
A B C
0 0.548012 0.288583 0.734276
1 0.378794 0.160913 0.971951
2 0.581093 0.750331 0.133022通常,我們是不需要保留舊索引的,因此可將drop參數設置為True。同樣,如果要就地重置索引,可設置inplace參數為True,否則將創建一個新的 DataFrame。
groupby分組方法是經常用的。比如下面通過添加一個分組列team來進行分組。
>>> df0["team"] = ["X", "X", "Y", "Y", "Y"]
>>> df0
A B C team
0 0.548012 0.288583 0.734276 X
1 0.342895 0.207917 0.995485 X
2 0.378794 0.160913 0.971951 Y
3 0.039738 0.008414 0.226510 Y
4 0.581093 0.750331 0.133022 Y
>>> df0.groupby("team").mean()
A B C
team
X 0.445453 0.248250 0.864881
Y 0.333208 0.306553 0.443828默認情況下,分組會將分組列編程index索引。但是很多情況下,我們不希望分組列變成索引,因為可能有些計算或者判斷邏輯還是需要用到該列的。因此,我們需要設置一下讓分組列不成為索引,同時也能完成分組的功能。
有兩種方法可以完成所需的操作,第一種是用reset_index,第二種是在groupby方法里設置as_index=False。個人更喜歡第二種方法,它只涉及兩個步驟,更簡潔。
>>> df0.groupby("team").mean().reset_index()
team A B C
0 X 0.445453 0.248250 0.864881
1 Y 0.333208 0.306553 0.443828
>>> df0.groupby("team", as_index=False).mean()
team A B C
0 X 0.445453 0.248250 0.864881
1 Y 0.333208 0.306553 0.443828當用sort_value排序方法時也會遇到這個問題,因為默認情況下,索引index跟著排序順序而變動,所以是亂雪。如果我們希望索引不跟著排序變動,同樣需要在sort_values方法中設置一下參數ignore_index即可。
>>> df0.sort_values("A")
A B C team
3 0.039738 0.008414 0.226510 Y
1 0.342895 0.207917 0.995485 X
2 0.378794 0.160913 0.971951 Y
0 0.548012 0.288583 0.734276 X
4 0.581093 0.750331 0.133022 Y
>>> df0.sort_values("A", ignore_index=True)
A B C team
0 0.039738 0.008414 0.226510 Y
1 0.342895 0.207917 0.995485 X
2 0.378794 0.160913 0.971951 Y
3 0.548012 0.288583 0.734276 X
4 0.581093 0.750331 0.133022 Y刪除重復項和排序一樣,默認執行后也會打亂排序順序。同理,可以在drop_duplicates方法中設置ignore_index參數True即可。
>>> df0
A B C team
0 0.548012 0.288583 0.734276 X
1 0.342895 0.207917 0.995485 X
2 0.378794 0.160913 0.971951 Y
3 0.039738 0.008414 0.226510 Y
4 0.581093 0.750331 0.133022 Y
>>> df0.drop_duplicates("team", ignore_index=True)
A B C team
0 0.548012 0.288583 0.734276 X
1 0.378794 0.160913 0.971951 Y當我們有了一個 DataFrame 時,想要使用不同的數據源或單獨的操作來分配索引。在這種情況下,可以直接將索引分配給現有的 df.index。
>>> better_index = ["X1", "X2", "Y1", "Y2", "Y3"] >>> df0.index = better_index >>> df0 A B C team X1 0.548012 0.288583 0.734276 X X2 0.342895 0.207917 0.995485 X Y1 0.378794 0.160913 0.971951 Y Y2 0.039738 0.008414 0.226510 Y Y3 0.581093 0.750331 0.133022 Y
數據導出到 CSV 文件時,默認 DataFrame 具有從 0 開始的索引。如果我們不想在導出的 CSV 文件中包含它,可以在to_csv方法中設置index參數。
>>> df0.to_csv("exported_file.csv", index=False)如下所示,導出的 CSV 文件中,索引列未包含在文件中。
其實,很多方法中都有關于索引的設置,只不過大家一般比較關心數據,而經常忽略了索引,才導致繼續運行時可能會報錯。以上幾個高頻的操作都是有索引設置的,建議大家平時用的時候養成設置索引的習慣,這樣會節省不少時間。
關于“pandas刪除部分數據后重新生成索引如何實現”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





