溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Python怎么利用多線程爬取LOL高清壁紙”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Python怎么利用多線程爬取LOL高清壁紙”文章吧。
目標網站:英雄聯盟
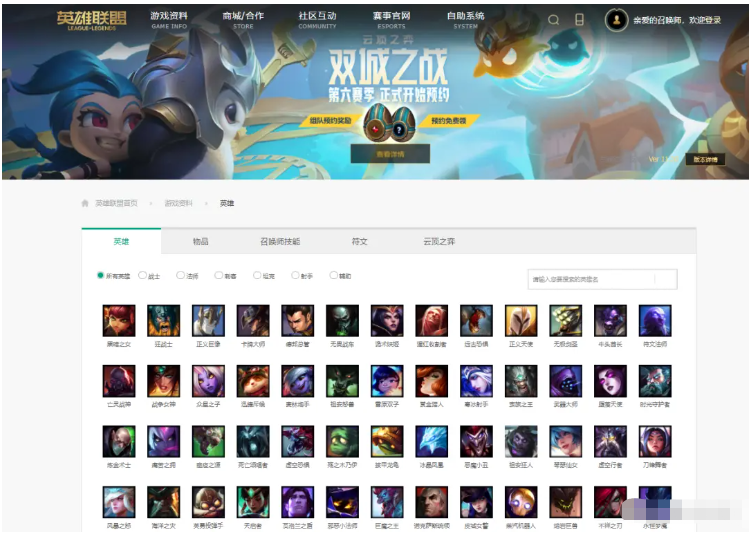
官網界面如圖所示,顯而易見,一個小圖表示一個英雄,我們的目的是爬取每一個英雄的所有皮膚圖片,全部下載下來并保存到本地。
次級頁面
上面的頁面我們稱為主頁面,次級頁面也就是每一個英雄對應的頁面,就以黑暗之女為例,它的次級頁面如下所示:
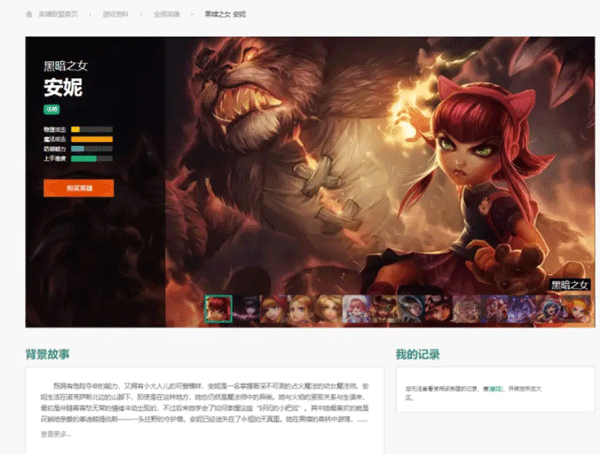
我們可以看到有很多的小圖,每一張小圖對應一個皮膚,通過 network 查看皮膚數據接口,如下圖所示:
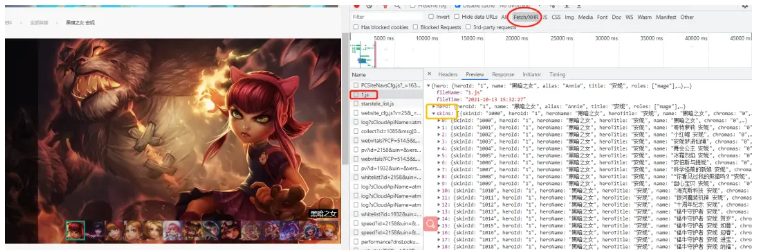
我們知道了皮膚信息是一個 json 格式的字符串進行傳輸的,那么我們只要找到每個英雄對應的 id,找到對應的 json 文件,提取需要的數據就能得到高清皮膚壁紙。
然后這里黑暗之女的 json 的文件地址是:
hero_one = 'https://game.gtimg.cn/images/lol/act/img/js/hero/1.js'
這里其實規律也非常簡單,每個英雄的皮膚數據的地址是這樣的:
url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(id)那么問題來了 id 的規律是怎么樣的呢?這里英雄的 id 需要在首頁查看,如下所示:
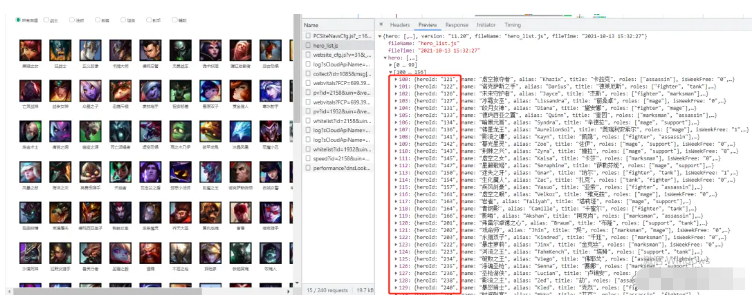
我們可以看到兩個列表[0,99],[100,156],即 156 個英雄,但是 heroId 卻一直到了 240….,由此可見,它是有一定的變化規律的,并不是依次加一,所以要爬取全部英雄皮膚圖片,需要先拿到全部的heroId。
為什么使用多線程,這里解釋一下,我們在爬取圖片,視頻這種數據的時候,因為需要保存到本地,所以會使用大量的文件的讀取和寫入操作,也就是 IO 操作,試想一下如果我們進行同步請求操作;
那么在第一次請求完成一直到文件保存到本地,才會進行第二次請求,那么這樣效率非常低下,如果使用多線程進行異步操作,效率會大大提升。
所以必然要使用多線程或者是多進程,然后把這么多的數據隊列丟給線程池或者進程池去處理;
在 Python 中,multiprocessing Pool 進程池,multiprocessing.dummy 非常好用。
multiprocessing.dummy模塊:dummy模塊是多線程;
multiprocessing模塊:multiprocessing是多進程;
multiprocessing.dummy模塊與multiprocessing模塊兩者的 api 都是通用的,代碼的切換使用上比較靈活;
我們首先在一個測試的 demo.py 文件抓取英雄 id,這里的代碼我已經寫好了,得到一個儲存英雄 id 的列表,直接在主文件里使用即可;
demo.py
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
res = requests.get(url,headers=headers)
res = res.content.decode('utf-8')
res_dict = json.loads(res)
heros = res_dict["hero"] # 156個hero信息
idList = []
for hero in heros:
hero_id = hero["heroId"]
idList.append(hero_id)
print(idList)得到 idList 如下所示:
idlist = [1,2,3,….,875,876,877] # 中間的英雄 id 這里不做展示
構建的 url:
page = 'http://www.bizhi88.com/s/470/{}.html'.format(i)這里的 i 表示 id,進行 url 的動態構建;
那么我們定制兩個函數一個用于爬取并且解析頁面(spider),一個用于下載數據 (download),開啟線程池,使用 for 循環構建存儲英雄皮膚 json 數據的 url,儲存在列表中,作為 url 隊列,使用 pool.map() 方法執行 spider (爬蟲)函數;
def map(self, fn, *iterables, timeout=None, chunksize=1): """Returns an iterator equivalent to map(fn, iter)”“” # 這里我們的使用是:pool.map(spider,page) # spider:爬蟲函數;page:url隊列
作用:將列表中的每個元素提取出來當作函數的參數,創建一個個進程,放進進程池中;
參數1:要執行的函數;
參數2:迭代器,將迭代器中的數字作為參數依次傳入函數中;
json數據解析
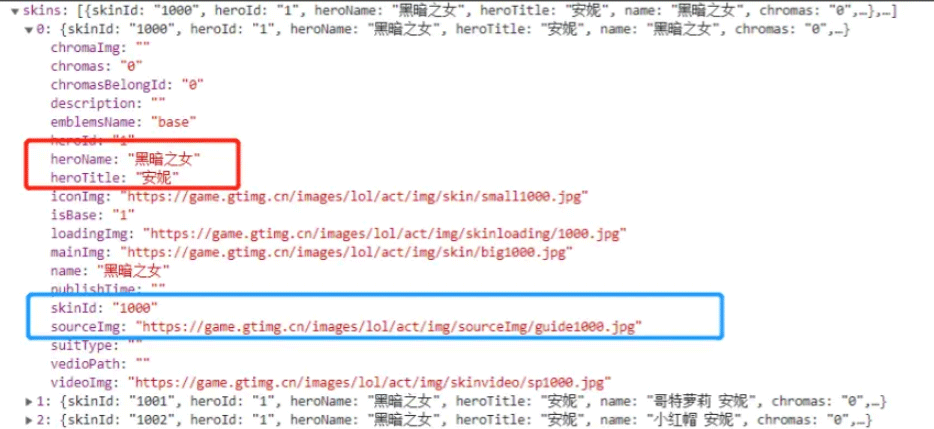
這里我們就以黑暗之女的皮膚的 json 文件做展示進行解析,我們需要獲取的內容有:
1.name
2.skin_name
3.mainImg
因為我們發現 heroName 是一樣的,所以把英雄名作為該英雄的皮膚文件夾名,這樣便于查看保存;
item = {}
item['name'] = hero["heroName"]
item['skin_name'] = hero["name"]
if hero["mainImg"] == '':
continue
item['imgLink'] = hero["mainImg"]有一個注意點:
有的 mainImg 標簽是空的,所以我們需要跳過,否則如果是空的鏈接,請求時會報錯;
導入相關第三方庫
import requests # 請求 from multiprocessing.dummy import Pool as ThreadPool # 并發 import time # 效率 import os # 文件操作 import json # 解析
頁面數據解析
def spider(url):
res = requests.get(url, headers=headers)
result = res.content.decode('utf-8')
res_dict = json.loads(result)
skins = res_dict["skins"] # 15個hero信息
print(len(skins))
for index,hero in enumerate(skins): # 這里使用到enumerate獲取下標,以便文件圖片命名;
item = {} # 字典對象
item['name'] = hero["heroName"]
item['skin_name'] = hero["name"]
if hero["mainImg"] == '':
continue
item['imgLink'] = hero["mainImg"]
print(item)
download(index+1,item)download 下載圖片
def download(index,contdict):
name = contdict['name']
path = "皮膚/" + name
if not os.path.exists(path):
os.makedirs(path)
content = requests.get(contdict['imgLink'], headers=headers).content
with open('./皮膚/' + name + '/' + contdict['skin_name'] + str(index) + '.jpg', 'wb') as f:
f.write(content)這里我們使用 OS 模塊創建文件夾,前面我們有說到,每個英雄的 heroName 的值是一樣的,借此創建文件夾并命名,方便皮膚的保存(歸類),然后就是這里圖片文件的路徑需要仔細,少一個斜杠就會報錯。
main() 主函數
def main():
pool = ThreadPool(6)
page = []
for i in range(1,21):
newpage = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(i)
print(newpage)
page.append(newpage)
result = pool.map(spider, page)
pool.close()
pool.join()
end = time.time()說明:
在主函數里我們首選創建了六個線程池;
通過 for 循環動態構建 20 條 url,我們小試牛刀一下,20 個英雄皮膚,如果爬取全部可以對之前的 idList 遍歷,再動態構建 url;
使用 map() 函數對線程池中的 url 進行數據解析存儲操作;
當線程池 close 的時候并未關閉線程池,只是會把狀態改為不可再插入元素的狀態;
if __name__ == '__main__': main()
結果如下:

當然了這里只是截取了部分圖像,總共爬取了 200+ 張圖片,總體來說還是可以。
以上就是關于“Python怎么利用多線程爬取LOL高清壁紙”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





