溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下怎么利用Python對500強排行榜數據進行可視化分析的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
今天來跟大家分析一下2020年中國500強企業排行榜數據,從不同角度去對數據進行統計分析,可視化展示。
主要分析內容:
中國500強企業-省份分布。
中國500強企業-營業收入年增率。
中國500強企業-營業收入年減率。
中國500強企業-利潤年增率。
中國500強企業-利潤年減率。
中國500強企業-排名上升最快。
中國500強企業-排名下降最快。
中國500強企業-資產區間分布。
中國500強企業-市值區間分布。
中國500強企業-營業收入區間分布。
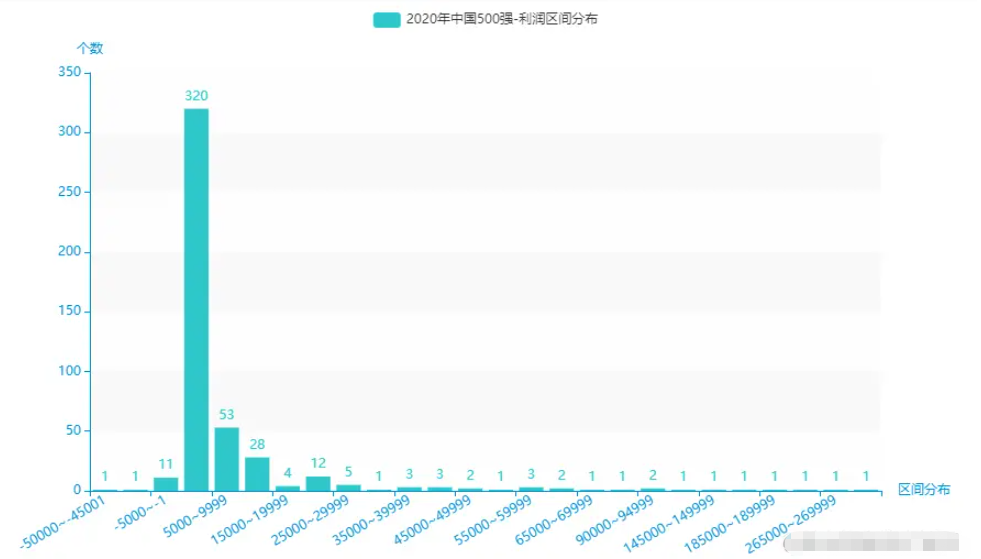
中國500強企業-利潤區間分布。
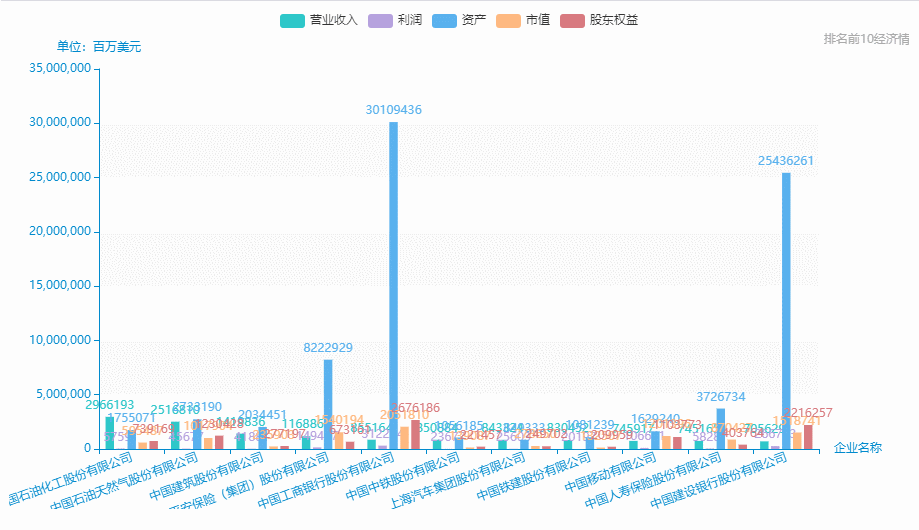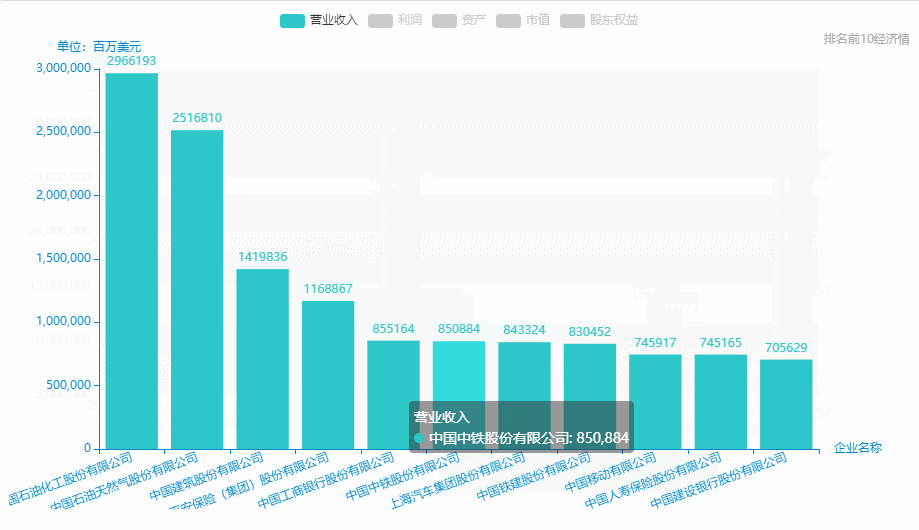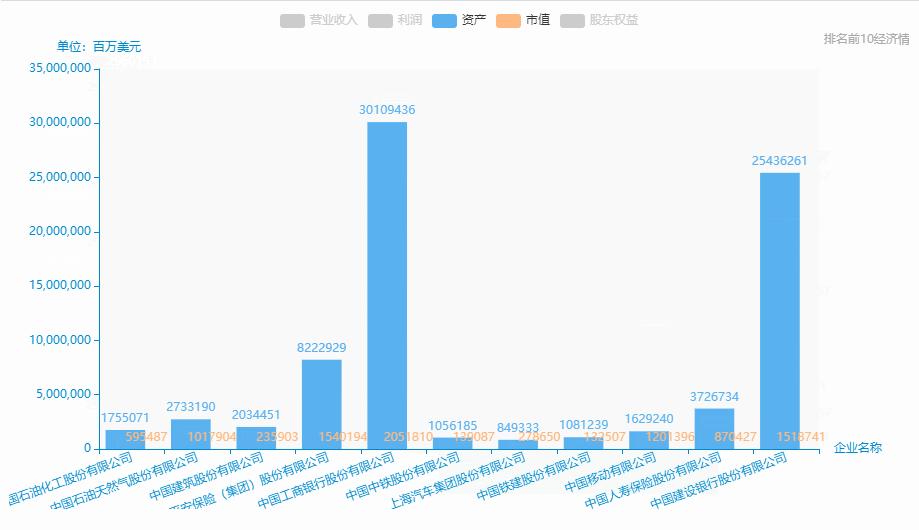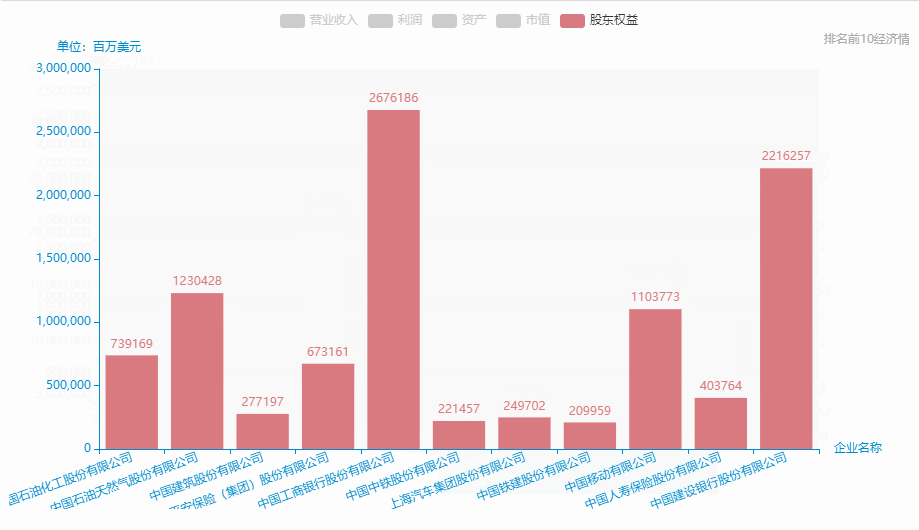
中國500強企業-排名前10營業收入、利潤、資產、市值、股東權益等情況。
下面開始從數據采集到數據統計分析,最后進行可視化!!!

url="http://www.fortunechina.com/fortune500/c/2020-07/27/content_369925.htm" res = requests.get(url,headers=headers) res.encoding = 'utf-8' text = res.text
for i in range(0,len(table_tr)):
try:
#name = i.xpath('.//td/a/text()')[0]
href = table_tr[i].xpath('.//td/a/@href')[0].replace("../../../../","http://www.fortunechina.com/")
column_list = get_detail(href)
for k in range(0,len(column_list)):
outws.cell(row=count, column=k+1, value=column_list[k])
print(count)
count = count+1
except:
passname = selector.xpath('//*[@class="comp-name"]/text()')[0]
r1 = selector.xpath('//*[@class="con"]/em[@class="r1"]/text()')[0]
r2 = selector.xpath('//*[@class="con"]/span/em/font[@class="ft-red"]/text()')[0]
address = selector.xpath('//*[@class="info"]/p')[0].xpath('.//text()')[0].replace(" ", "")
table_tbody_tr = selector.xpath('//*[@class="table"]/table/tr')outwb = openpyxl.Workbook()
outws = outwb.create_sheet(index=0)
outws.cell(row=1, column=1, value="企業名稱")
outws.cell(row=1, column=2, value="2020年排名")
outws.cell(row=1, column=3, value="2019年排名")
outws.cell(row=1, column=4, value="總部地址")
outws.cell(row=1, column=5, value="營業收入")
outws.cell(row=1, column=6, value="營業收入年增減")
outws.cell(row=1, column=7, value="利潤")
outws.cell(row=1, column=8, value="利潤年增減")
outws.cell(row=1, column=9, value="資產")
outws.cell(row=1, column=10, value="市值")
outws.cell(row=1, column=11, value="股東權益")
outwb.save("中國500強排行榜數據.xlsx") # 保存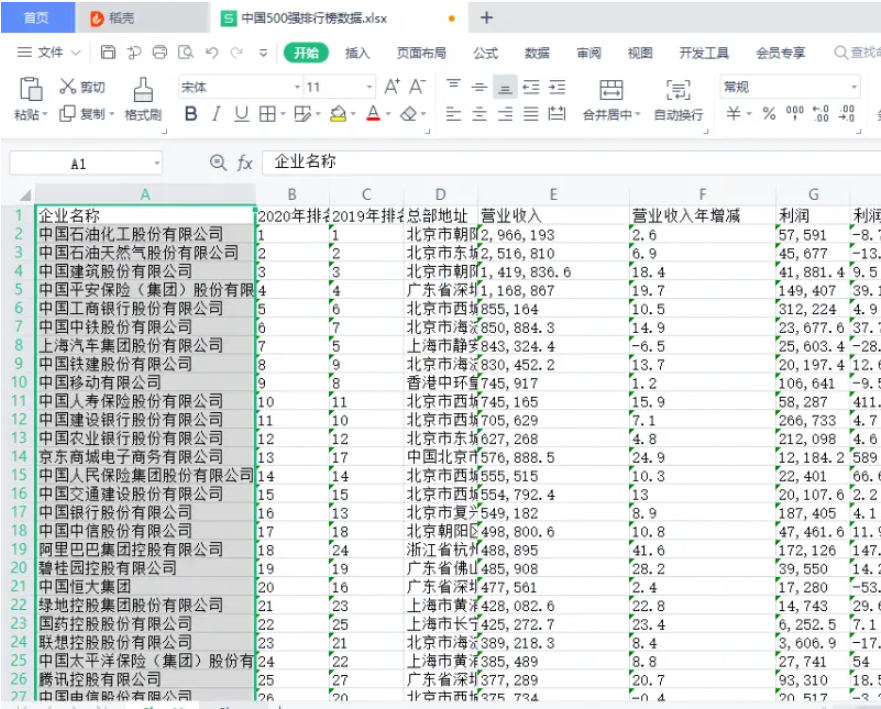
數據就已經保存到Excel中,下面開始進行統計分析,可視化!
from pyecharts import options as opts from pyecharts.charts import Line from pyecharts.charts import Map import pandas as pd from pyecharts import options as opts from pyecharts.globals import ThemeType from pyecharts.charts import Bar

從excel中中取出:總部地址,然后取出前兩位(省份),統計每一個省份的500強分布情況
address = pd_data['總部地址'] address = address.tolist() address_03 = [] for i in address: ###取省份(前兩位) address_03.append(i[0:2]) data =[] address_03_set = set(address_03) #address_03_set是另外一個列表,里面的內容是address_03里面的無重復 項 for item in address_03_set: data.append((item,address_03.count(item)))
def map_china() -> Map:
c = (
Map()
.add(series_name="企業數量", data_pair=data, maptype="china",zoom = 1,center=[105,38])
.set_global_opts(
title_opts=opts.TitleOpts(title="中國500強企業省份分布"),
visualmap_opts=opts.VisualMapOpts(max_=9999,is_piecewise=True,
pieces=[{"max": 9, "min": 0, "label": "0-9","color":"#FFE4E1"},
{"max": 99, "min": 10, "label": "10-99","color":"#FF7F50"},
{"max": 499, "min": 100, "label": "100-499","color":"#F08080"},
{"max": 999, "min": 500, "label": "500-999","color":"#CD5C5C"},
{"max": 9999, "min": 1000, "label": ">=1000", "color":"#8B0000"}]
)
)
)
return c
從excel中中取出:營業收入年增減,統計增加率最大的前50名和減少率(負數)最大的前50名
income_rate = pd_data['營業收入年增減']
compare_name = pd_data['企業名稱']
income_rate = income_rate.tolist()
compare_name = compare_name.tolist()
m = income_rate
# 求一個list中最大的50個數,并排序
max_number = heapq.nlargest(50, m)
# 最大的2個數對應的,如果用nsmallest則是求最小的數及其索引
max_index = map(m.index, heapq.nlargest(50, m))
# max_index 直接輸出來不是數,使用list()或者set()均可輸出
#print(set(max_index)) ###{235, 140, 273, 148, 86}
max_index = list(set(max_index))
#ss = [m.index(j) for j in max_number]
name =[compare_name[k] for k in set(max_index)]
outwb = openpyxl.Workbook()
outws = outwb.create_sheet(index=0)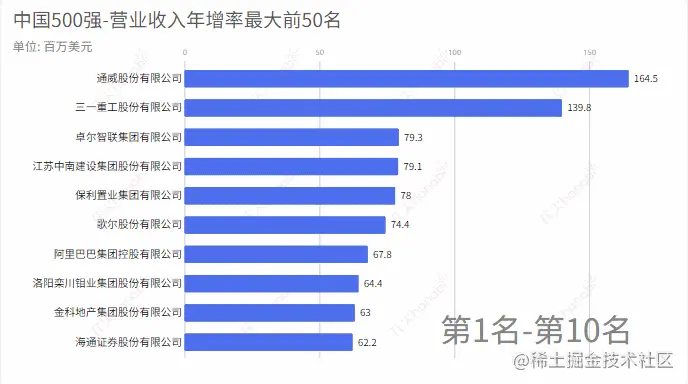
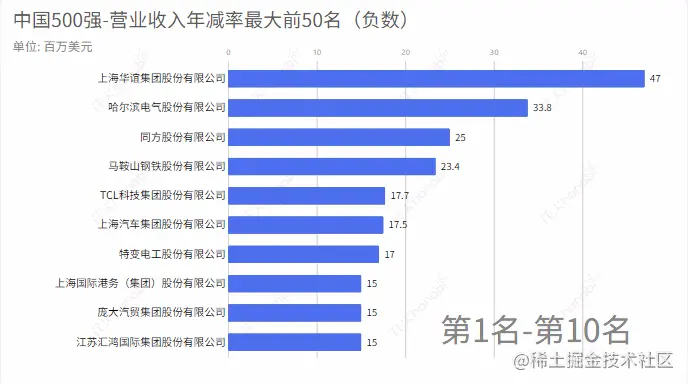
income_rate = income_rate.tolist() compare_name = compare_name.tolist() m = income_rate # 求一個list中最小的50個數,并排序 min_number = heapq.nsmallest(60, m) min_index = [m.index(j) for j in min_number] name =[compare_name[k] for k in set(min_index)]
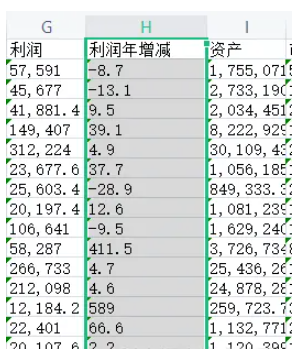
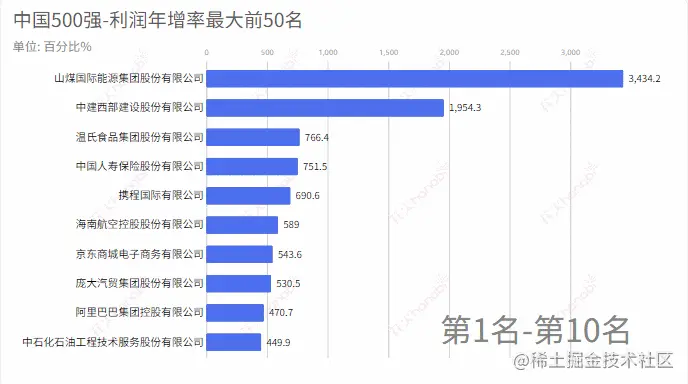
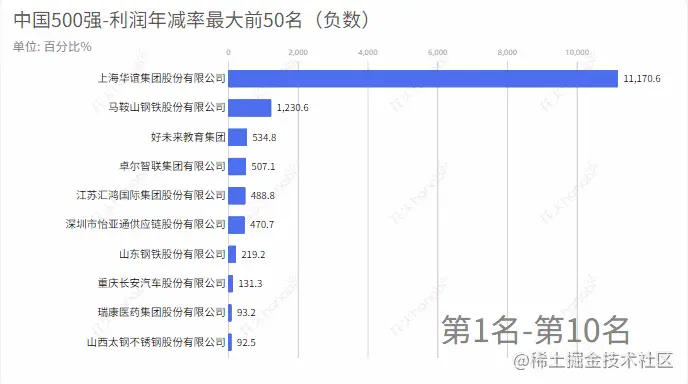
從excel中中取出:利潤年增減,統計增加率最大的前50名和減少率(負數)最大的前50名
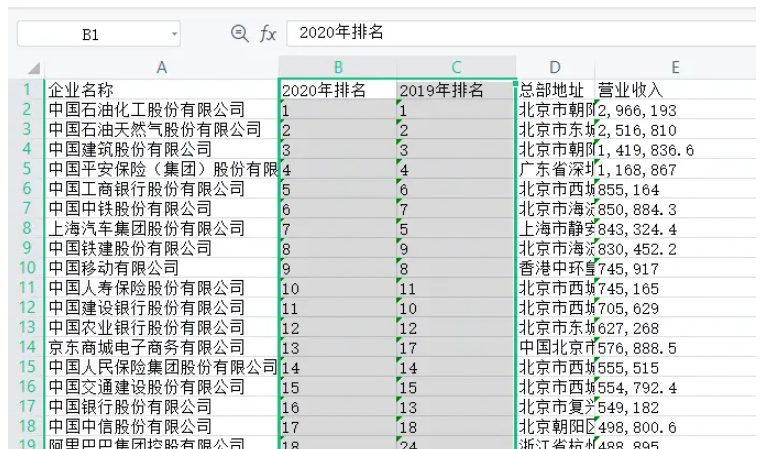
從excel中中取出:2020年排名和2019年排名,進行對比,統計排名上升最大的前20家企業,和排名下降最大的前20家企業。
###折線圖 def LinePic(x_data,y_data,name): ( Line() # 進行全局設置 .set_global_opts( tooltip_opts=opts.TooltipOpts(is_show=True), # 顯示提示信息,默認為顯示,可以不寫 xaxis_opts=opts.AxisOpts(type_="category"), yaxis_opts=opts.AxisOpts( type_="value", axistick_opts=opts.AxisTickOpts(is_show=True), splitline_opts=opts.SplitLineOpts(is_show=True), ), ) # 添加x軸的點 .add_xaxis(xaxis_data=x_data) # 添加y軸的點 .add_yaxis( series_name=name, y_axis=y_data, symbol="emptyCircle", is_symbol_show=True, label_opts=opts.LabelOpts(is_show=True), ) # 保存為一個html文件 .render(name+".html") )
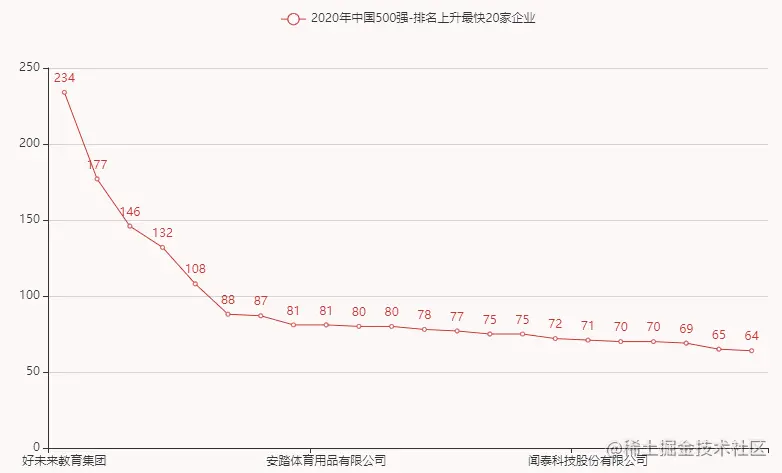
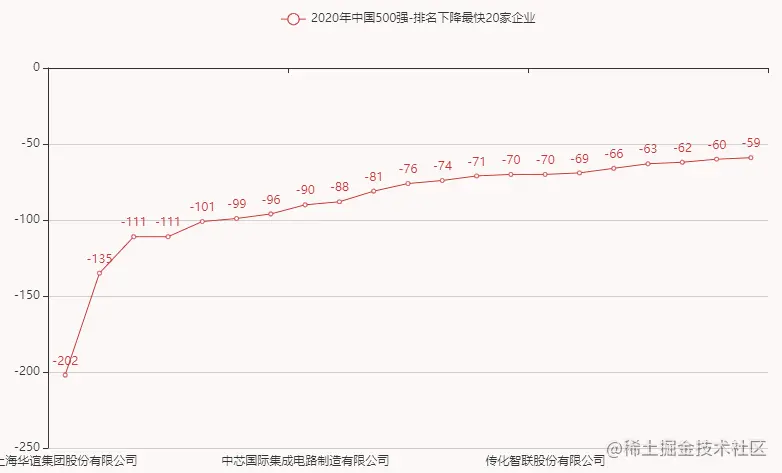
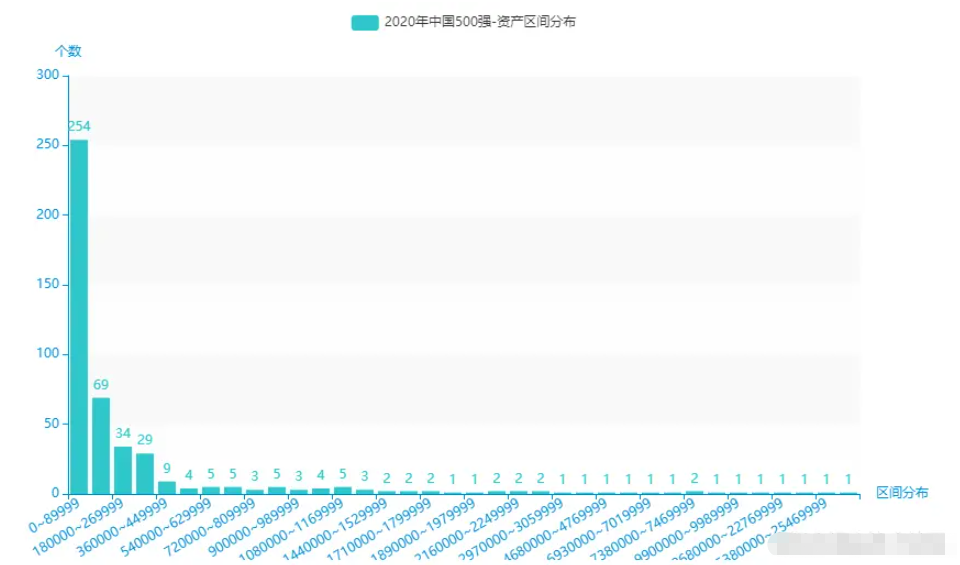
從excel中中取出:資產,為9000 間隔進行區間劃分,并統計每一個區間的個數。
for k, g in groupby(sorted(assets_list), key=lambda x: x // 90000): name.append(str(k * 90000) + "~" + str((k + 1) * 90000 - 1)) dict_value.append(int(len(list(g))))
從excel中中取出:市值,為7000 間隔進行區間劃分,并統計每一個區間的個數。
for k, g in groupby(sorted(assets_list), key=lambda x: x // 7000): name.append(str(k * 7000) + "~" + str((k + 1) * 7000 - 1)) dict_value.append(int(len(list(g))))

從excel中中取出:營業收入,為50000 間隔進行區間劃分,并統計每一個區間的個數。
for k, g in groupby(sorted(assets_list), key=lambda x: x // 50000): name.append(str(k * 50000) + "~" + str((k + 1) * 50000 - 1)) dict_value.append(int(len(list(g))))
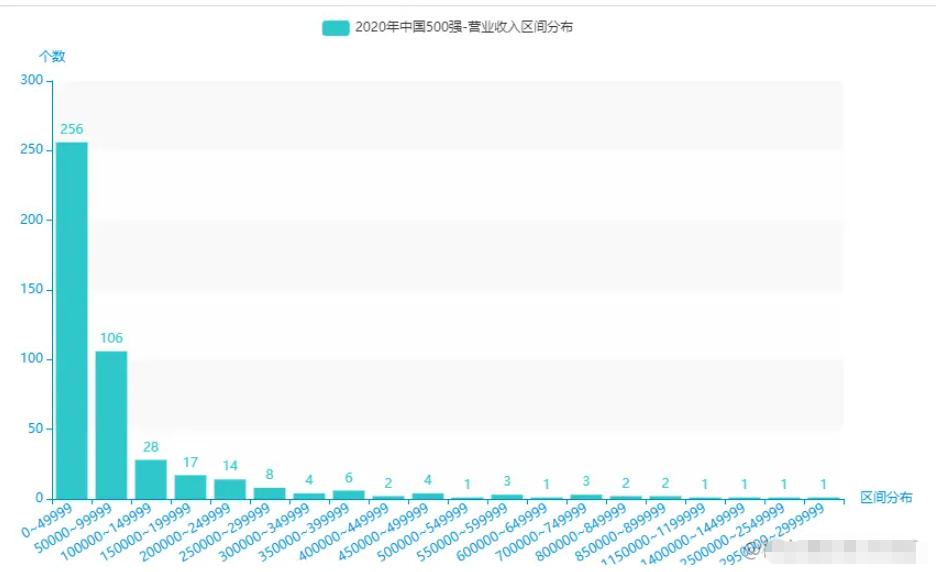
從excel中中取出:利潤為5000 間隔進行區間劃分,并統計每一個區間的個數。
for k, g in groupby(sorted(assets_list), key=lambda x: x//5000): name.append(str(k*5000)+"~"+str((k+1)*5000-1)) dict_value.append(int(len(list(g))))
從excel中中取出排名前10: **營業收入、**利潤、資產、市值、股東權益、
name = pd_data['企業名稱'][0:11].tolist()
data_1 = pd_data['營業收入'][0:11].tolist()
data_2 = pd_data['利潤'][0:11].tolist()
data_3 = pd_data['資產'][0:11].tolist()
data_4 = pd_data['市值'][0:11].tolist()
data_5 = pd_data['股東權益'][0:11].tolist()
# 鏈式調用
c = (
Bar(
init_opts=opts.InitOpts( # 初始配置項
theme=ThemeType.MACARONS,
animation_opts=opts.AnimationOpts(
animation_delay=1000, animation_easing="cubicOut" # 初始動畫延遲和緩動效果
))
)
.add_xaxis(xaxis_data=name) # x軸
.add_yaxis(series_name="營業收入", yaxis_data=cleardata(data_1)) # y軸
.add_yaxis(series_name="利潤", yaxis_data=cleardata(data_2)) # y軸
.add_yaxis(series_name="資產", yaxis_data=cleardata(data_3)) # y軸
.add_yaxis(series_name="市值", yaxis_data=cleardata(data_4)) # y軸
.add_yaxis(series_name="股東權益", yaxis_data=cleardata(data_5)) # y軸
.set_global_opts(
title_opts=opts.TitleOpts(title='', subtitle='排名前10經濟情況', # 標題配置和調整位置
title_textstyle_opts=opts.TextStyleOpts(
font_family='SimHei', font_size=25, font_weight='bold', color='red',
), pos_left="90%", pos_top="10",
),
xaxis_opts=opts.AxisOpts(name='企業名稱', axislabel_opts=opts.LabelOpts(rotate=20)),
# 設置x名稱和Label rotate解決標簽名字過長使用
yaxis_opts=opts.AxisOpts(name='單位:百萬美元'),
)
.render("2020年中國500強-排名前10名經濟情況.html")
)
以上就是“怎么利用Python對500強排行榜數據進行可視化分析”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





