溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Python多進程知識點有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Python多進程知識點有哪些”吧!

程序:例如xxx.py這是程序,是一個靜態的
進程:一個程序運行起來后,代碼+用到的資源 稱之為進程,它是操作系統分配資源的基本單元。不僅可以通過線程完成多任務,進程也是可以的
工作中,任務數往往大于cpu的核數,即一定有一些任務正在執行,而另外一些任務在等待cpu進行執行,因此導致了有了不同的狀態
就緒態:運行的條件都已經慢去,正在等在cpu執行
執行態:cpu正在執行其功能
等待態:等待某些條件滿足,例如一個程序sleep了,此時就處于等待態
multiprocessing模塊通過創建一個Process對象然后調用它的start()方法來生成進程,Process與threading.Thread API相同。
語法格式:multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
參數說明:
group:指定進程組,大多數情況下用不到
target:如果傳遞了函數的引用,可以任務這個子進程就執行這里的代碼
name:給進程設定一個名字,可以不設定
args:給target指定的函數傳遞的參數,以元組的方式傳遞
kwargs:給target指定的函數傳遞命名參數
multiprocessing.Process 對象具有如下方法和屬性:
| 方法名/屬性 | 說明 |
|---|---|
run() | 進程具體執行的方法 |
start() | 啟動子進程實例(創建子進程) |
join([timeout]) | 如果可選參數 timeout 是默認值 None,則將阻塞至調用 join() 方法的進程終止;如果 timeout 是一個正數,則最多會阻塞 timeout 秒 |
name | 當前進程的別名,默認為Process-N,N為從1開始遞增的整數 |
pid | 當前進程的pid(進程號) |
is_alive() | 判斷進程子進程是否還在活著 |
exitcode | 子進程的退出代碼 |
daemon | 進程的守護標志,是一個布爾值。 |
authkey | 進程的身份驗證密鑰。 |
sentinel | 系統對象的數字句柄,當進程結束時將變為 ready。 |
terminate() | 不管任務是否完成,立即終止子進程 |
kill() | 與 terminate() 相同,但在 Unix 上使用 SIGKILL 信號。 |
close() | 關閉 Process 對象,釋放與之關聯的所有資源 |
# -*- coding:utf-8 -*-from multiprocessing import Processimport timedef run_proc():
"""子進程要執行的代碼"""
while True:
print("----2----")
time.sleep(1)if __name__=='__main__':
p = Process(target=run_proc)
p.start()
while True:
print("----1----")
time.sleep(1)運行結果:
說明:創建子進程時,只需要傳入一個執行函數和函數的參數,創建一個Process實例,用start()方法啟動
# -*- coding:utf-8 -*-from multiprocessing import Processimport osimport timedef run_proc():
"""子進程要執行的代碼"""
print('子進程運行中,pid=%d...' % os.getpid()) # os.getpid獲取當前進程的進程號
print('子進程將要結束...')if __name__ == '__main__':
print('父進程pid: %d' % os.getpid()) # os.getpid獲取當前進程的進程號
p = Process(target=run_proc)
p.start()運行結果:
# -*- coding:utf-8 -*-from multiprocessing import Processimport osfrom time import sleepdef run_proc(name, age, **kwargs):
for i in range(10):
print('子進程運行中,name= %s,age=%d ,pid=%d...' % (name, age, os.getpid()))
print(kwargs)
sleep(0.2)if __name__=='__main__':
p = Process(target=run_proc, args=('test',18), kwargs={"m":20})
p.start()
sleep(1) # 1秒中之后,立即結束子進程
p.terminate()
p.join()運行結果:
# -*- coding:utf-8 -*-from multiprocessing import Processimport osimport time
nums = [11, 22]def work1():
"""子進程要執行的代碼"""
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
for i in range(3):
nums.append(i)
time.sleep(1)
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))def work2():
"""子進程要執行的代碼"""
print("in process2 pid=%d ,nums=%s" % (os.getpid(), nums))if __name__ == '__main__':
p1 = Process(target=work1)
p1.start()
p1.join()
p2 = Process(target=work2)
p2.start()運行結果:
in process1 pid=11349 ,nums=[11, 22]in process1 pid=11349 ,nums=[11, 22, 0]in process1 pid=11349 , nums=[11, 22, 0, 1]in process1 pid=11349 ,nums=[11, 22, 0, 1, 2]in process2 pid=11350 ,nums=[11, 22]
Process之間有時需要通信,操作系統提供了很多機制來實現進程間的通信。
| 方法名 | 說明 |
|---|---|
q=Queue() | 初始化Queue()對象,若括號中沒有指定最大可接收的消息數量,或數量為負值,那么就代表可接受的消息數量沒有上限(直到內存的盡頭) |
Queue.qsize() | 返回當前隊列包含的消息數量 |
Queue.empty() | 如果隊列為空,返回True,反之False |
Queue.full() | 如果隊列滿了,返回True,反之False |
Queue.get([block[, timeout]]) | 獲取隊列中的一條消息,然后將其從列隊中移除,block默認值為True。1、如果block使用默認值,且沒有設置timeout(單位秒),消息列隊如果為空,此時程序將被阻塞(停在讀取狀態),直到從消息列隊讀到消息為止,如果設置了timeout,則會等待timeout秒,若還沒讀取到任何消息,則拋出"Queue.Empty"異常。2、如果block值為False,消息列隊如果為空,則會立刻拋出"Queue.Empty"異常 |
Queue.get_nowait() | 相當Queue.get(False) |
Queue.put(item,[block[, timeout]]) | 將item消息寫入隊列,block默認值為True。1、如果block使用默認值,且沒有設置timeout(單位秒),消息列隊如果已經沒有空間可寫入,此時程序將被阻塞(停在寫入狀態),直到從消息列隊騰出空間為止,如果設置了timeout,則會等待timeout秒,若還沒空間,則拋出"Queue.Full"異常。 2、如果block值為False,消息列隊如果沒有空間可寫入,則會立刻拋出"Queue.Full"異常 |
Queue.put_nowait(item) | 相當Queue.put(item, False) |
可以使用multiprocessing模塊的Queue實現多進程之間的數據傳遞,Queue本身是一個消息列隊程序,首先用一個小實例來演示一下Queue的工作原理:
#coding=utf-8from multiprocessing import Queue
q=Queue(3) #初始化一個Queue對象,最多可接收三條put消息q.put("消息1") q.put("消息2")print(q.full()) #Falseq.put("消息3")print(q.full()) #True#因為消息列隊已滿下面的try都會拋出異常,第一個try會等待2秒后再拋出異常,第二個Try會立刻拋出異常try:
q.put("消息4",True,2)except:
print("消息列隊已滿,現有消息數量:%s"%q.qsize())try:
q.put_nowait("消息4")except:
print("消息列隊已滿,現有消息數量:%s"%q.qsize())#推薦的方式,先判斷消息列隊是否已滿,再寫入if not q.full():
q.put_nowait("消息4")#讀取消息時,先判斷消息列隊是否為空,再讀取if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())運行結果:
FalseTrue消息列隊已滿,現有消息數量:3消息列隊已滿,現有消息數量:3消息1消息2消息3
我們以Queue為例,在父進程中創建兩個子進程,一個往Queue里寫數據,一個從Queue里讀數據:
from multiprocessing import Process, Queueimport os, time, random# 寫數據進程執行的代碼:def write(q):
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())# 讀數據進程執行的代碼:def read(q):
while True:
if not q.empty():
value = q.get(True)
print('Get %s from queue.' % value)
time.sleep(random.random())
else:
breakif __name__=='__main__':
# 父進程創建Queue,并傳給各個子進程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 啟動子進程pw,寫入:
pw.start()
# 等待pw結束:
pw.join()
# 啟動子進程pr,讀取:
pr.start()
pr.join()
# pr進程里是死循環,無法等待其結束,只能強行終止:
print('')
print('所有數據都寫入并且讀完')運行結果:
鎖是為了確保數據一致性。比如讀寫鎖,每個進程給一個變量增加 1,但是如果在一個進程讀取但還沒有寫入的時候,另外的進程也同時讀取了,并寫入該值,則最后寫入的值是錯誤的,這時候就需要加鎖來保持數據一致性。
通過使用Lock來控制一段代碼在同一時間只能被一個進程執行。Lock對象的兩個方法,acquire()用來獲取鎖,release()用來釋放鎖。當一個進程調用acquire()時,如果鎖的狀態為unlocked,那么會立即修改為locked并返回,這時該進程即獲得了鎖。如果鎖的狀態為locked,那么調用acquire()的進程則阻塞。
1. Lock的語法說明:
lock = multiprocessing.Lock(): 創建一個鎖
lock.acquire() :獲取鎖
lock.release() :釋放鎖
with lock:自動獲取、釋放鎖 類似于 with open() as f:
2. 程序不加鎖時:
import multiprocessingimport timedef add(num, value):
print('add{0}:num={1}'.format(value, num))
for i in range(0, 2):
num += value print('add{0}:num={1}'.format(value, num))
time.sleep(1)if __name__ == '__main__':
lock = multiprocessing.Lock()
num = 0
p1 = multiprocessing.Process(target=add, args=(num, 1))
p2 = multiprocessing.Process(target=add, args=(num, 2))
p1.start()
p2.start()運行結果:運得沒有順序,兩個進程交替運行
add1:num=0add1:num=1add2:num=0add2:num=2add1:num=2add2:num=4
3. 程序加鎖時:
import multiprocessingimport timedef add(num, value, lock):
try:
lock.acquire()
print('add{0}:num={1}'.format(value, num))
for i in range(0, 2):
num += value print('add{0}:num={1}'.format(value, num))
time.sleep(1)
except Exception as err:
raise err finally:
lock.release()if __name__ == '__main__':
lock = multiprocessing.Lock()
num = 0
p1 = multiprocessing.Process(target=add, args=(num, 1, lock))
p2 = multiprocessing.Process(target=add, args=(num, 2, lock))
p1.start()
p2.start()運行結果:只有當其中一個進程執行完成后,其它的進程才會去執行,且誰先搶到鎖誰先執行
add1:num=0add1:num=1add1:num=2add2:num=0add2:num=2add2:num=4
當需要創建的子進程數量不多時,可以直接利用
multiprocessing中的Process動態成生多個進程,但如果是上百甚至上千個目標,手動的去創建進程的工作量巨大,此時就可以用到multiprocessing模塊提供的Pool方法。
語法格式:multiprocessing.pool.Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
參數說明:
processes:工作進程數目,如果 processes 為 None,則使用 os.cpu_count() 返回的值。
initializer:如果 initializer 不為 None,則每個工作進程將會在啟動時調用 initializer(*initargs)。
maxtasksperchild:一個工作進程在它退出或被一個新的工作進程代替之前能完成的任務數量,為了釋放未使用的資源。
context:用于指定啟動的工作進程的上下文。
兩種方式向進程池提交任務:
apply(func[, args[, kwds]]):阻塞方式。
apply_async(func[, args[, kwds]]):非阻塞方式。使用非阻塞方式調用func(并行執行,堵塞方式必須等待上一個進程退出才能執行下一個進程),args為傳遞給func的參數列表,kwds為傳遞給func的關鍵字參數列表
multiprocessing.Pool常用函數:
| 方法名 | 說明 |
|---|---|
close() | 關閉Pool,使其不再接受新的任務 |
terminate() | 不管任務是否完成,立即終止 |
join() | 主進程阻塞,等待子進程的退出, 必須在close或terminate之后使用 |
初始化Pool時,可以指定一個最大進程數,當有新的請求提交到Pool中時,如果池還沒有滿,那么就會創建一個新的進程用來執行該請求;但如果池中的進程數已經達到指定的最大值,那么該請求就會等待,直到池中有進程結束,才會用之前的進程來執行新的任務,請看下面的實例:
# -*- coding:utf-8 -*-from multiprocessing import Poolimport os, time, randomdef worker(msg):
t_start = time.time()
print("%s開始執行,進程號為%d" % (msg,os.getpid()))
# random.random()隨機生成0~1之間的浮點數
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"執行完畢,耗時%0.2f" % (t_stop-t_start))po = Pool(3) # 定義一個進程池,最大進程數3for i in range(0,10):
# Pool().apply_async(要調用的目標,(傳遞給目標的參數元祖,))
# 每次循環將會用空閑出來的子進程去調用目標
po.apply_async(worker,(i,))print("----start----")po.close()
# 關閉進程池,關閉后po不再接收新的請求po.join()
# 等待po中所有子進程執行完成,必須放在close語句之后print("-----end-----")運行結果:
----start---- 0開始執行,進程號為21466 1開始執行,進程號為21468 2開始執行,進程號為21467 0 執行完畢,耗時1.01 3開始執行,進程號為21466 2 執行完畢,耗時1.24 4開始執行,進程號為21467 3 執行完畢,耗時0.56 5開始執行,進程號為21466 1 執行完畢,耗時1.68 6開始執行,進程號為21468 4 執行完畢,耗時0.67 7開始執行,進程號為21467 5 執行完畢,耗時0.83 8開始執行,進程號為21466 6 執行完畢,耗時0.75 9開始執行,進程號為21468 7 執行完畢,耗時1.03 8 執行完畢,耗時1.05 9 執行完畢,耗時1.69 -----end-----
如果要使用Pool創建進程,就需要使用multiprocessing.Manager()中的Queue()
而不是multiprocessing.Queue(),否則會得到一條如下的錯誤信息:RuntimeError: Queue objects should only be shared between processes through inheritance.
下面的實例演示了進程池中的進程如何通信:
# -*- coding:utf-8 -*-# 修改import中的Queue為Managerfrom multiprocessing import Manager,Poolimport os,time,randomdef reader(q):
print("reader啟動(%s),父進程為(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader從Queue獲取到消息:%s" % q.get(True))def writer(q):
print("writer啟動(%s),父進程為(%s)" % (os.getpid(), os.getppid()))
for i in "itcast":
q.put(i)if __name__=="__main__":
print("(%s) start" % os.getpid())
q = Manager().Queue() # 使用Manager中的Queue
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1) # 先讓上面的任務向Queue存入數據,然后再讓下面的任務開始從中取數據
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid())運行結果:
(11095) start writer啟動(11097),父進程為(11095)reader啟動(11098),父進程為(11095)reader從Queue獲取到消息:i reader從Queue獲取到消息:t reader從Queue獲取到消息:c reader從Queue獲取到消息:a reader從Queue獲取到消息:s reader從Queue獲取到消息:t(11095) End
進程:能夠完成多任務,比如 在一臺電腦上能夠同時運行多個QQ
線程:能夠完成多任務,比如 一個QQ中的多個聊天窗口
定義的不同
進程是系統進行資源分配和調度的一個獨立單位.
線程是進程的一個實體,是CPU調度和分派的基本單位,它是比進程更小的能獨立運行的基本單位.線程自己基本上不擁有系統資源,只擁有一點在運行中必不可少的資源(如程序計數器,一組寄存器和棧),但是它可與同屬一個進程的其他的線程共享進程所擁有的全部資源.
一個程序至少有一個進程,一個進程至少有一個線程.
-線程的劃分尺度小于進程(資源比進程少),使得多線程程序的并發性高。
-進程在執行過程中擁有獨立的內存單元,而多個線程共享內存,從而極大地提高了程序的運行效率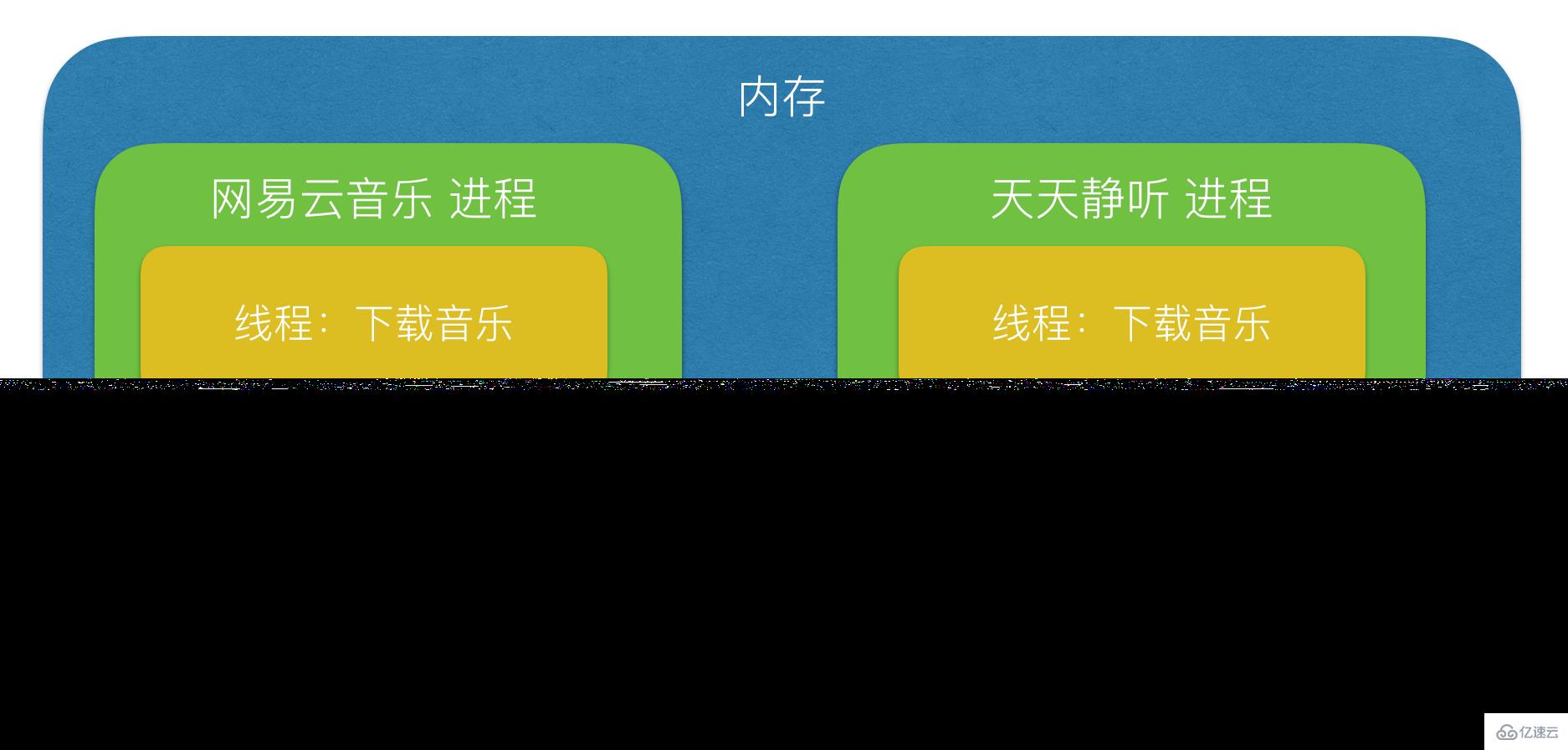
線線程不能夠獨立執行,必須依存在進程中
可以將進程理解為工廠中的一條流水線,而其中的線程就是這個流水線上的工人
線程:線程執行開銷小,但不利于資源的管理和保護
進程:進程執行開銷大,但利于資源的管理和保護
感謝各位的閱讀,以上就是“Python多進程知識點有哪些”的內容了,經過本文的學習后,相信大家對Python多進程知識點有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





