溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么用Python爬蟲獲取國外大橋排行榜數據清單”,在日常操作中,相信很多人在怎么用Python爬蟲獲取國外大橋排行榜數據清單問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么用Python爬蟲獲取國外大橋排行榜數據清單”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
前言:
正式開始前,先安裝 pyquery 到本地開發環境中。命令如下:pip install pyquery ,我使用的版本為 1.4.3。
基本使用如下所示,看懂也就掌握了 5 成了,就這么簡單。
from pyquery import PyQuery as pq
s = '<html><title>橡皮擦的PyQuery小課堂</title></html>'
doc = pq(s)
print(doc('title'))輸出如下內容:
<title>橡皮擦的PyQuery小課堂</title>
也可以直接將要解析的網址 URL 傳遞給 pyquery 對象,代碼如下所示:
from pyquery import PyQuery as pq
url = "https://www.bilibili.com/"
doc = pq(url=url,encoding="utf-8")
print(doc('title')) # <title>嗶哩嗶哩 (゜-゜)つロ 干杯~-bilibili</title>相同的思路,還可以通過文件初始化 pyquery 對象,只需要修改參數為 filename 即可。
基礎鋪墊過后,就可以進入到實操環節,下面是本次要抓取的目標案例分析。
本次要采集的為 :List of Highest International Bridges(最高國際橋梁名單),
頁面呈現的數據如下所示:
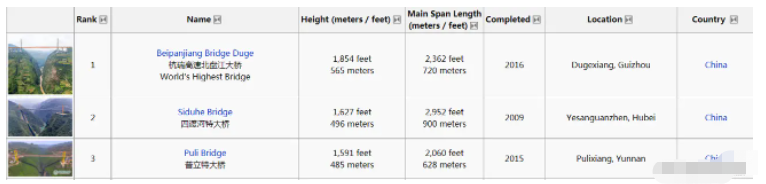
在翻閱過程中發現多數都是中國設計的,果然我們基建世界第一。
翻頁規則如下所示:
http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_1
http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_2
# 實測翻到第 13 頁數據就空了,大概1200座橋梁
http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_13
由于目標數據以表格形式存在,故直接按照表頭提取數據即可。 Rank,Name,Height (meters / feet),Main Span Length,Completed,Location,Country
正式編碼前,先拿第一頁進行練手:
from pyquery import PyQuery as pq
url = "http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_1"
doc = pq(url=url, encoding='utf-8')
print(doc('title'))
def remove(str):
return str.replace("
", "").replace("\n", "")
# 獲取所有數據所在的行,下面使用的是 css 選擇器,稱作 jquery 選擇器也沒啥問題
items = doc.find('table.wikitable.sortable tr').items()
for item in items:
td_list = item.find('td')
rank = td_list.eq(1).find("span.sorttext").text()
name = td_list.eq(2).find("a").text()
height = remove(td_list.eq(3).text())
length = remove(td_list.eq(4).text())
completed = td_list.eq(5).text()
location = td_list.eq(6).text()
country = td_list.eq(7).text()
print(rank, name, height, length, completed, location, country)代碼整體寫下來,發現依舊是對于選擇器的依賴比較大,也就是需要熟練的操作選擇器,選中目標元素,方便獲取最終的數據。
將上述代碼擴大到全部數據,修改成迭代采集:
from pyquery import PyQuery as pq
import time
def remove(str):
return str.replace("
", "").replace("\n", "").replace(",", ",")
def get_data(page):
url = "http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_{}".format(
page)
print(url)
doc = pq(url=url, encoding='utf-8')
print(doc('title'))
# 獲取所有數據所在的行,下面使用的是 css 選擇器,稱作 jquery 選擇器也沒啥問題
items = doc.find('table.wikitable.sortable tr').items()
for item in items:
td_list = item.find('td')
rank = td_list.eq(1).find("span.sorttext").text()
name = remove(td_list.eq(2).find("a").text())
height = remove(td_list.eq(3).text())
length = remove(td_list.eq(4).text())
completed = remove(td_list.eq(5).text())
location = remove(td_list.eq(6).text())
country = remove(td_list.eq(7).text())
data_tuple = (rank, name, height, length, completed, location, country)
save(data_tuple)
def save(data_tuple):
try:
my_str = ",".join(data_tuple) + "\n"
# print(my_str)
with open(f"./data.csv", "a+", encoding="utf-8") as f:
f.write(my_str)
print("寫入完畢")
except Exception as e:
pass
if __name__ == '__main__':
for page in range(1, 14):
get_data(page)
time.sleep(3)其中發現存在英文的逗號,統一進行修改,即 remove(str) 函數的應用。
到此,關于“怎么用Python爬蟲獲取國外大橋排行榜數據清單”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





