溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“pandas調用函數怎么用”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“pandas調用函數怎么用”文章吧。
這里的數據是虛構的語數外成績,大家在演示的時候拷貝一下就好啦。
import pandas as pd df = pd.read_clipboard() df
姓名 | 語文 | 數學 | 英語 | 性別 | 總分 |
0 | 才哥 | 91 | 95 | 92 | 1 |
1 | 小明 | 82 | 93 | 91 | 1 |
2 | 小華 | 82 | 87 | 94 | 1 |
3 | 小草 | 96 | 55 | 88 | 0 |
4 | 小紅 | 51 | 41 | 70 | 0 |
5 | 小花 | 58 | 59 | 40 | 0 |
6 | 小龍 | 70 | 55 | 59 | 1 |
7 | 杰克 | 53 | 44 | 42 | 1 |
8 | 韓梅梅 | 45 | 51 | 67 | 0 |
apply可以對DataFrame類型數據按照列或行進行函數處理,默認情況下是按照列(單獨對Series亦可)。
在案例數據中,比如我們想將性別列中的1替換為男,0替換為女,那么可以這樣搞定。
先自定義一個函數,這個函數有一個參數 s(Series類型數據)。
def getSex(s): if s==1: return '男' elif s==0: return '女'
上述函數還有更簡潔寫法,這里方便理解采用最直觀的寫法哈。
然后,我們直接使用apply去調用這個函數即可。
df['性別'].apply(getSex)
可以看到輸出結果如下:
0 男
1 男
2 男
3 女
4 女
5 女
6 男
7 男
8 女
Name: 性別, dtype: object
當然,我們也可以直接用調用匿名函數lambda的形式:
df['性別'].apply( lambda s: '男' if s==1 else '女' )
可以看到結果是一樣的:
0 男
1 男
2 男
3 女
4 女
5 女
6 男
7 男
8 女
Name: 性別, dtype: object
以上是單純根據一列的值條件進行的數據處理,我們也可以根據多列組合條件(可以了解為按行)進行處理,需要注意這種情況下需要指定參數axis=1,具體看下面案例。
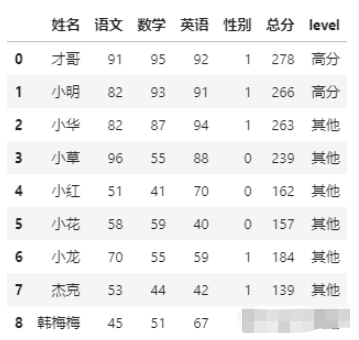
案例中,我們認為總分高于200且數學分數高于90為高分
# 多列條件組合 df['level'] = df.apply(lambda df: '高分' if df['總分']>=200 and df['數學']>=90 else '其他', axis=1) df
同樣,上述用apply調用的函數都是自定義的,實際上我們也可以調用內置或者pandas/numpy等自帶的函數。
比如,求語數外和總分最高分:
# python內置的函數 df[['語文','數學','英語','總分']].apply(max)
語文 96
數學 95
英語 94
總分 278
dtype: int64
求語數外和總分平均分:
# numpy自帶的函數 import numpy as np df[['語文','數學','英語','總分']].apply(np.mean)
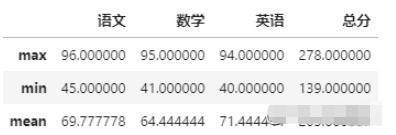
語文 69.777778
數學 64.444444
英語 71.444444
總分 205.666667
dtype: float64
applymap則是對每個元素的函數處理,變量是每個元素值。
比如對語數外三科超過90分認為是科目高分
df[['語文','數學','英語']].applymap(lambda x:'高分' if x>=90 else '其他')
語文 | 數學 | 英語 |
0 | 高分 | 高分 |
1 | 其他 | 高分 |
2 | 其他 | 其他 |
3 | 高分 | 其他 |
4 | 其他 | 其他 |
5 | 其他 | 其他 |
6 | 其他 | 其他 |
7 | 其他 | 其他 |
8 | 其他 | 其他 |
map則是根據輸入對應關系映射值返回最終數據,作用于某一列。傳入的值可以是字典,鍵值為原始值,值為需要替換的值。也可以傳入一個函數或者字符格式化表達式等等。
以上面性別列中的1替換為男,0替換為女為例,還可以通過map來實現
df['性別'].map({1:'男', 0:'女'})輸出結果也是一致的:
0 男
1 男
2 男
3 女
4 女
5 女
6 男
7 男
8 女
Name: 性別, dtype: object
比如總分列想變成格式化字符:
df['總分'].map('總分:{}分'.format)0 總分:278分
1 總分:266分
2 總分:263分
3 總分:239分
4 總分:162分
5 總分:157分
6 總分:184分
7 總分:139分
8 總分:163分
Name: 總分, dtype: object
agg一般用于聚合,在分組或透視操作中常見到,用法是和apply比較接近。
比如,求語數外和總分的最高分、最低分和平均分
df[['語文','數學','英語','總分']].agg(['max','min','mean'])
我們還可以對不同的列進行不同的運算(用字典形式指定)
# 語文最高分、數學最低分和英文最高最低分
df.agg({'語文':['max'],'數學':'min','英語':['max','min']})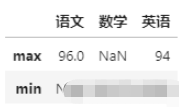
當然也支持自定義函數的調用
以上四個調用函數的方法,我們發現被調用的函數的參數就是 DataFrame或Serise數據,如果我們被調用的函數還需要別的參數,那么該如何做呢?
所以,pipe就出現了。
pipe又稱管道方法,可以將我們的處理分析過程標準化、流程化。它在調用函數的時候可以帶被調用函數的其他參數,這樣就方便自定義函數的功能擴展了。
比如,我們需要獲取總分大于n,性別為sex的同學的數據,其中n和sex是可變參數,那么用apply等就不太好處理。這個時候,就可以用到pipe方法來搞事了!
我們先定義一個函數:
# 定義一個函數,總分大于等于n,性別為sex的同學數據(sex為2表示不分性別) def total(df, n, sex): dfT = df.copy() if sex == 2: return dfT[(dfT['總分']>=n)] else: return dfT[(dfT['總分']>=n) & (dfT['性別']==sex)]
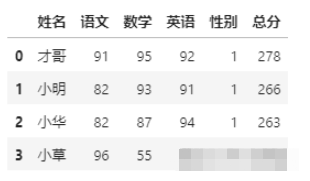
如果我們要找到總分大于200,不分性別的學生成績,可以這樣:
df.pipe(total,200,2)
再找總分大于150,性別為男生(1)的學生成績,可以這樣:
df.pipe(total,150,1)
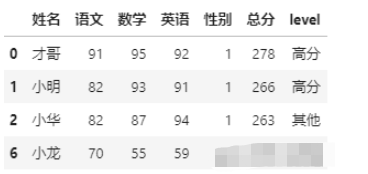
再找總分大于200,性別為女生(0)的學生成績,可以這樣:
df.pipe(total,200,0)

以上就是關于“pandas調用函數怎么用”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





