溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Elasticsearch Recovery索引分片分配的方法”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Elasticsearch Recovery索引分片分配的方法”吧!
在Eleasticsearch中recovery指的就是一個索引的分片分配到另外一個節點的過程;一般在快照恢復、索引副本數變更、節點故障、節點重啟時發生。由于master保存整個集群的狀態信息,因此可以判斷出哪些shard需要做再分配,以及分配到哪個結點,例如:
如果某個shard主分片在,副分片所在結點掛了,那么選擇另外一個可用結點,將副分片分配(allocate)上去,然后進行主從分片的復制。
如果某個shard的主分片所在結點掛了,副分片還在,那么將副分片升級為主分片,然后做主從分片復制。
如果某個shard的主副分片所在結點都掛了,則暫時無法恢復,等待持有相關數據的結點重新加入集群后,從該結點上恢復主分片,再選擇另外的結點復制副分片。
正常情況下,我們可以通過ES的health的API接口,查看整個集群的健康狀態和整個集群數據的完整性:

狀態及含義如下:
green: 所有的shard主副分片都是正常的;
yellow: 所有shard的主分片都完好,部分副分片沒有或者不完整,數據完整性依然完好;
red: 某些shard的主副分片都沒有了,對應的索引數據不完整。
recovery過程要消耗額外的資源,CPU、內存、結點之間的網絡帶寬等等。 這些額外的資源消耗,有可能會導致集群的服務性能下降,或者一部分功能暫時不可用。了解一些recovery的過程和相關的配置參數,對于減小recovery帶來的資源消耗,加快集群恢復過程都是很有幫助的。
ES集群可能會有整體重啟的情況,比如需要升級硬件、升級操作系統或者升級ES大版本。重啟所有結點可能帶來的一個問題: 某些結點可能先于其他結點加入集群, 先加入集群的結點可能已經可以選舉好master,并立即啟動了recovery的過程,由于這個時候整個集群數據還不完整,master會指示一些結點之間相互開始復制數據。 那些晚到的結點,一旦發現本地的數據已經被復制到其他結點,則直接刪除掉本地“失效”的數據。 當整個集群恢復完畢后,數據分布不均衡,顯然是不均衡的,master會觸發rebalance過程,將數據在節點之間挪動。整個過程無謂消耗了大量的網絡流量;合理設置recovery相關參數則可以防范這種問題的發生。
gateway.expected_nodes gateway.expected_master_nodes gateway.expected_data_nodes
以上三個參數是說集群里一旦有多少個節點就立即開始recovery過程。 不同之處在于,第一個參數指的是master或者data都算在內,而后面兩個參數則分指master和data node。
在期待的節點數條件滿足之前, recovery過程會等待gateway.recover_after_time (默認5分鐘) 這么長時間,一旦等待超時,則會根據以下條件判斷是否啟動:
gateway.expected_nodes gateway.expected_master_nodes gateway.expected_data_nodes
舉例來說,對于一個有10個data node的集群,如果有以下的設置:
gateway.expected_data_nodes: 10 gateway.recover_after_time: 5m gateway.recover_after_data_nodes: 8
那么集群5分鐘以內10個data node都加入了,或者5分鐘以后8個以上的data node加入了,都會立即啟動recovery過程。
如果不是full restart,而是重啟單個data node,仍然會造成數據在不同結點之間來回復制。為避免這個問題,可以在重啟之前,先關閉集群的shard allocation:
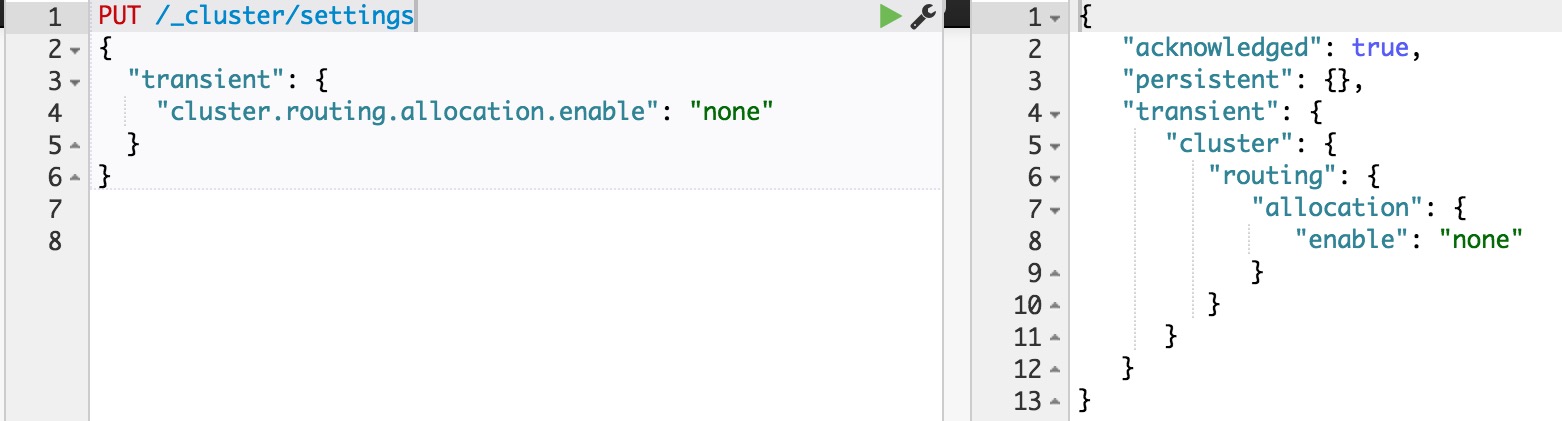
然后在節點重啟完成加入集群后,再重新打開:
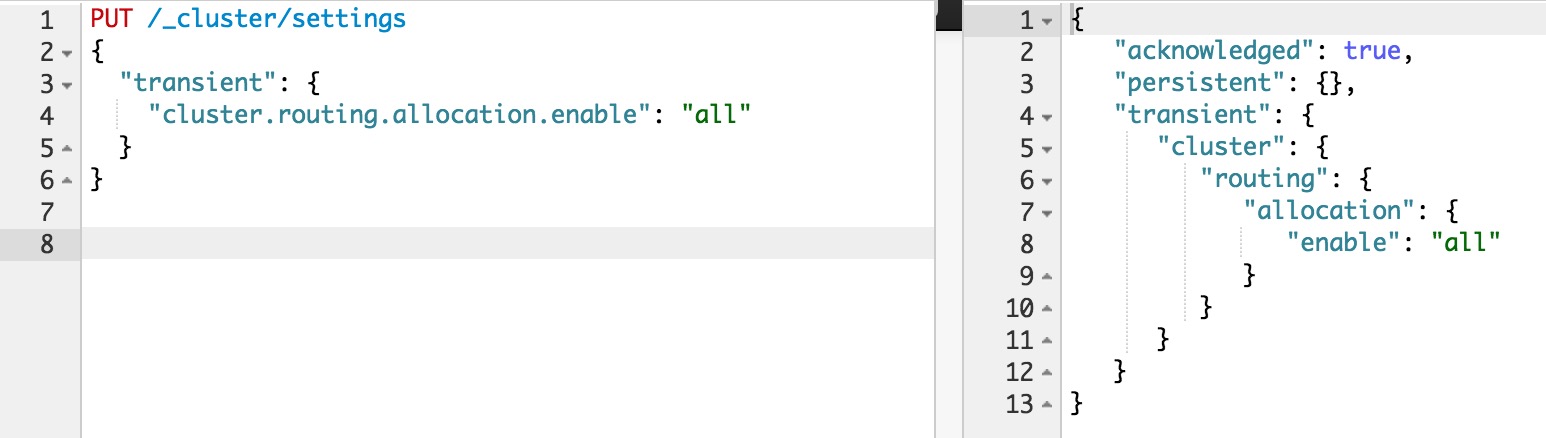
這樣在節點重啟完成后,盡量多的從本地直接恢復數據。
但是在ES1.6版本之前,即使做了以上措施,仍然會發現有大量主副本之間的數據拷貝。從表面去看,這點很讓人不能理解。
主副本數據完全一致,ES應該直接從副本本地恢復數據就好了,為什么要重新從主片再復制一遍呢? 原因在于recovery是簡單對比主副本的segment file來判斷哪些數據一致可以本地恢復,哪些不一致需要遠端拷貝的。
而不同節點的segment merge是完全獨立運行的,可能導致主副本merge的深度不完全一樣,從而造成即使文檔集完全一樣,產生的segment file卻不完全一樣。
為了解決這個問題,ES1.6版本以后加入了synced flush的新特性。 對于5分鐘沒有更新過的shard,會自動synced flush一下,實質是為對應的shard加了一個synced flush ID。這樣當重啟節點的時候,先對比一下shard的synced flush ID,就可以知道兩個shard是否完全相同,避免了不必要的segment file拷貝,極大加快了冷索引的恢復速度。
需要注意的是synced flush只對冷索引有效,對于熱索引(5分鐘內有更新的索引)沒有作用。 如果重啟的結點包含有熱索引,那么還是免不了大量的文件拷貝
。因此在重啟一個結點之前,最好按照以下步驟執行,recovery幾乎可以瞬間完成:
暫停數據寫入程序
關閉集群shard allocation
手動執行POST /_flush/synced
重啟節點
重新開啟集群shard allocation
等待recovery完成,集群health status變成green
重新開啟數據寫入程序
對于冷索引,由于數據不再更新,利用synced flush特性,可以快速直接從本地恢復數據。 而對于熱索引,特別是shard很大的熱索引,;除了synced flush派不上用場需要大量跨節點拷貝segment file以外,translog recovery是導致慢的更重要的原因。
從主片恢復數據到副片需要經歷3個階段:
對主片上的segment file做一個快照,然后拷貝到復制片分配到的結點。數據拷貝期間,不會阻塞索引請求,新增索引操作記錄到translog里。
對translog做一個快照,此快照包含第一階段新增的索引請求,然后重放快照里的索引操作。此階段仍然不阻塞索引請求,新增索引操作記錄到translog里。
為了能達到主副片完全同步,阻塞掉新索引請求,然后重放階段二新增的translog操作。
可見,在recovery完成之前,translog是不能夠被清除掉的(禁用掉正常運作期間后臺的flush操作)。
如果shard比較大,第一階段耗時很長,會導致此階段產生的translog很大。重放translog比起簡單的文件拷貝耗時要長得多,因此第二階段的translog耗時也會顯著增加。
等到第三階段,需要重放的translog可能會比第二階段還要多。 而第三階段是會阻塞新索引寫入的,在對寫入實時性要求很高的場合,就會非常影響用戶體驗。
因此,要加快大的熱索引恢復速度,最好的方式是遵從上一節提到的方法: 暫停新數據寫入,手動sync flush,等待數據恢復完成后,重新開啟數據寫入,這樣可以將數據延遲影響可以降到最低。
萬一遇到Recovery慢,想知道進度怎么辦呢? CAT Recovery API可以顯示詳細的recovery各個階段的狀態。 這個API怎么用就不在這里贅述了,參考: CAT Recovery。
還有其他一些專家級的設置(參見: recovery)可以影響recovery的速度,但提升速度的代價是更多的資源消耗,因此在生產集群上調整這些參數需要結合實際情況謹慎調整,一旦影響應用要立即調整回來。
對于搜索并發量要求高,延遲要求低的場合,默認設置一般就不要去動了。
對于日志實時分析類對于搜索延遲要求不高,但對于數據寫入延遲期望比較低的場合,可以適當調大indices.recovery.max_bytes_per_sec,提升recovery速度,減少數據寫入被阻塞的時長。
最后要說的一點是ES的版本迭代很快,對于Recovery的機制也在不斷的優化中。 其中有一些版本甚至引入了一些bug,比如在ES1.4.x有嚴重的translog recovery bug,導致大的索引trans log recovery幾乎無法完成 。
因此實際使用中如果遇到問題,最好在Github的issue list里搜索一下,看是否使用的版本有其他人反映同樣的問題。
到此,相信大家對“Elasticsearch Recovery索引分片分配的方法”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





