溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“C語言數據的存儲怎么實現”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“C語言數據的存儲怎么實現”文章能幫助大家解決問題。
在基礎階段已經學習了基本的類型和存儲空間的大小。
知道了使用某個類型開辟內存空間的大小(大小決定了使用范圍)。
char //字符數據類型
short //短整型
int //整形
long //長整型
long long //更長的整形
float //單精度浮點數
double //雙精度浮點數
整形家族
char
unsigned char//無符號
signed char//有符號
short
unsigned short [int]//無符號
signed short [int]//有符號
int
unsigned int//無符號
signed int//有符號
long
unsigned long [int]//無符號
signed long [int]//有符號
浮點數家族
float
double
構造類型
> 數組類型
> 結構體類型 struct
> 枚舉類型 enum
> 聯合類型 union
指針類型
int *pi;
char *pc;
float* pf;
void* pv;
空類型
void 表示空類型(無類型)
通常應用于函數的返回類型、函數的參數、指針類型
一個變量的創建是要在內存中開辟空間的。空間的大小是根據變量的類型而決定的
//舉例 int a = 20; int b = -10;
int 為整形,占用4個字節,下面將具體分析變量 a 的數值20 在內存空間中是如何分配的
計算機中的整數有三種表示方法,即原碼、反碼和補碼:
原碼:直接將二進制按照正負數的形式翻譯成二進制就可以
**反碼:**將原碼的符號位不變,其他位依次按位取反就可以得到了
**補碼:**反碼+1就得到補碼
三種表示方法均有符號位和數值位兩部分:
符號位都是用0表示“正”,用1表示“負”
正整數數的原、反、補碼都相同
負整數的三種表示方法各不相同
注意,整數存放在內存中的是補碼,操作符的對象都是補碼,最后打印的是原碼。
舉例說明數值的原碼、反碼、補碼,
//
int main()
{
int a = 10;//正數
00000000 00000000 00000000 00001010 原碼
00000000 00000000 00000000 00001010 反碼
00000000 00000000 00000000 00001010 補碼
a在內存中的存儲形式 00 00 00 0a
int b = -10;//負數
10000000 00000000 00000000 00001010 原碼
11111111 11111111 11111111 11110101 反碼
11111111 11111111 11111111 11110110 補碼=反碼+1
b在內存中存儲的數值 ff ff ff f6
return 0;
}a的數值在內存中的存儲形式:

b的數值在內存中的存儲形式:
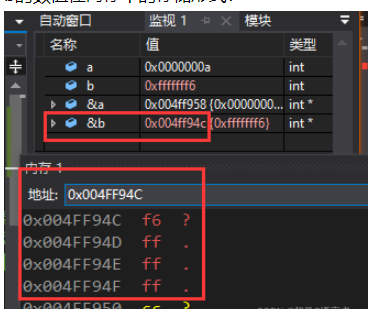
在計算機系統中,數值一律用補碼來表示和存儲。原因在于,使用補碼,可以將符號位和數值域統一處理;
由于CPU只有加法器,加法和減法也可以統一處理,此外,補碼與原碼相互轉換,其運算過程是相同的,不需要額外的硬件電路。
下面將舉例說明,數據在內存中的操作是運用補碼而不是原碼的:
int main()使用補碼計算,打印的是原碼
{
1-1//CPU只有加法器
1+(-1)
第一步:
00000000 00000000 00000000 00000001 1補碼
第二步:
10000000 00000000 00000000 00000001 -1原碼
11111111 11111111 11111111 11111110 -1反碼
11111111 11111111 11111111 11111111 -1補碼
第三步:補碼相加
00000000 00000000 00000000 00000001 1補碼
11111111 11111111 11111111 11111111 -1補碼
結果是33位,超出范圍
100000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 截斷32位為0
如果使用原碼計算,結果是錯誤的
00000000000000000000000000000001 1補碼
10000000000000000000000000000001 -1原碼
10000000000000000000000000000010 -2
}大端(存儲)模式,是指數據的低位保存在內存的高地址中,而數據的高位,保存在內存的低地址中
小端(存儲)模式,是指數據的低位保存在內存的低地址中,而數據的高位,,保存在內存的高地址中
因為在計算機系統中,我們是以字節為單位的,每個地址單元都對應著一個字節,一個字節為8bit
但是在C語言中除了8 bit的char之外,還有16 bit的short型,32 bit的long型(要看具體的編譯器)
另外,對于位數大于8位的處理器,例如16位或者32位的處理器,由于寄存器寬度大于一個字節,那么必然存在著一個如何將多個字節安排的問題。因此就導致了大端存儲模式和小端存儲模式
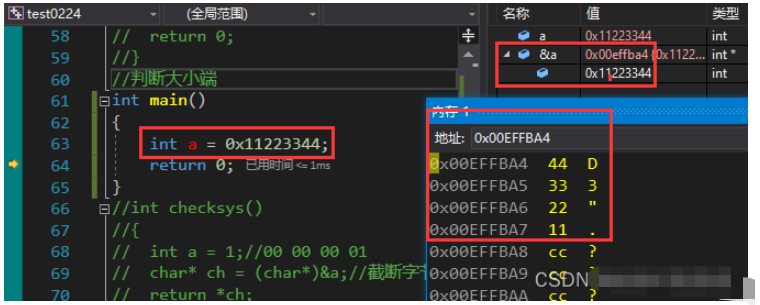
舉例說明大小端,例如:一個 16bit 的 short 型 x ,在內存中的地址為 0x0010 , x 的值為 0x1122 ,那么 0x11 為高字節, 0x22 為低字節。
對于大端模式,就將 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中
對于小端模式,剛好相反
我們常用的 X86 結構是小端模式,而 KEIL C51 則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以由硬件來選擇是大端模式還是小端模式。
int main()
{
int a = 0x11223344;
return 0;
}低字節0x44擋在低地址中,因此是小端模式:

設計一個小程序來判斷當前機器的字節序
int checksys()
{
int a = 1;//00 00 00 01
char* ch = (char*)&a;//char* 截斷字節,指針指向低地址數據
return *ch;//解引用,返回低地址數據
//return *(char*)&a;//上面兩行代碼也可寫成一行代碼
}
int main()
{
int a = checksys();
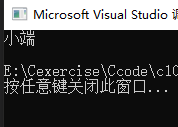
if (a==1)//如果低地址保存的數據是1,即0x01,就是低字節
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
關于“C語言數據的存儲怎么實現”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





