溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“OpenCV停車場車位實時檢測項目分析”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“OpenCV停車場車位實時檢測項目分析”文章吧。
今天整理OpenCV入門的第三個實戰小項目,前面的兩篇文章整理了信用卡數字識別以及文檔OCR掃描, 大部分用到的是OpenCV里面的基礎圖像預處理技術,比如輪廓檢測,邊緣檢測,形態學操作,透視變換等, 而這篇文章的項目呢,不僅需要一些基礎的圖像預處理,還需要搭建模型進行識別和預測,所以通過這個項目,能把圖像預處理以及建模型等一整套流程拉起來,并應用到實際的應用場景,還是非常有意思的。
停車場車位實時檢測任務,是拿到停車場的一段視頻video,主要完成兩件事情:
檢測整個停車場當中,當前一共有多少輛車,一共有多少個空余的車位
把空余的停車位標識出來,這樣用戶停車的時候,就可以直接去空余的停車位處, 為停車節省了很多時間
所以這個項目還是非常有實踐應用價值的,用了大約一天半的時間搞定這個項目,參考的是唐老師的OpenCV入門教程視頻, 不過這里面對于這個任務做的相對粗糙,我在這個基礎上基于我的理解進行了一些優化,主要改動如下:
據處理方面,按列框出停車位之后,我對每一列框的坐標手工進行了調整,確保每個停車位不遺漏,不多余, 然后是對每個停車位的坐標位置進行了微調,盡量讓其標記的準一些
模型方面,原視頻采用遷移學習方式,基于keras對VGG網絡進行的微調,而我模型這里統一基于pytorch,用的ResNet32預訓練模型進行的finetune,驗證集正確率能到0.94多,但第一版還是有少量預測的不是很準,所以又基于已有的幀圖片做了數據增強,額外增加了一些數據,把準確率提升到0.98左右
項目的整體架構全部改變,算是聽懂了上面的思想,然后基于自己的理解進行的重構,好處是后面可以進行各種優化,按照自己需求做數據增強,數據預處理以及訓練各種高級模型等。
不過,發現小resnet就夠強大的了,最終的預測效果如下:

這是視頻中的某一幀圖像,實際運行的時候,是讀入視頻,快速分開幀,每一幀做出這樣的預測標記,然后實時顯示。這樣在每個時刻,都能動態的知道該停車場有哪些車位空了出來。
下面就對這個項目中用到的關鍵技術進行整理,由于這個項目稍微大一些,代碼量多,不可能在這里全部展示,但想記錄下對于這個項目我的思考過程,以及各種處理的動機,以及如何進行的處理,我覺得這個才是對以后有用的東西。
首先,拿到這個任務之后, 得大致上梳理下流程,才能確定行動方案。 我們開始拿到了這樣的一段視頻,那么為了完成上面停車位檢測以及識別的任務,就需要考慮兩步:
我得先把停車場的每個停車位給提取出來
有了每個停車位,我訓練一個模型,去預測這個停車位上有沒有車就行啦,把沒有車的標識出來,然后統計個數
其實宏觀上就這么兩大步。那么后面的問題就是怎么把每個車位提取出來,又怎么訓練模型預測呢?
我這里主要分為了兩大步, 數據預處理以及模型的訓練及預測:
數據預處理方面
以視頻中某一幀的圖像為單位,進行處理
通過二值化,灰度化,邊緣檢測,特定點標定連線等,把圖片中多余的部分去掉,只保留停車場內的這部分對象
霍夫變換的直線檢測,去找圖片中的直線,根據直線坐標,先按列為單位,把車位按列框起來, 然后對框手動微調
在每一列中,鎖定每個停車位的位置,并對每個停車位進行標號,把這個保存成字典
有了每個停車位的位置,就能提取出對應圖片,可以作為后面模型的訓練以及驗證的數據集,不過需要人工手動劃分
通過上面步驟,會積累一些數據,大約800多張圖片,接下來就可以訓練模型,但是由于數據量太少,從頭訓練模型往往效果不好,所以這里采用遷移學習的方式,使用了預訓練的resnet34,用這800多張圖片微調。
訓練好了模型保存,接下來,對于每一幀圖像,有了停車位位置字典,就能直接提取出每一個停車位,然后對于這每個停車位,模型預測有沒有車即可
所以有了這樣的一個流程,就能再進一步分解細化,就可以大處著眼小處著手啦,下面整理每一步里面的關鍵細節。
首先,把一幀圖像讀入進來,原始圖像如下:

先通過二值化的方式過濾掉背景,突出重要信息,然后轉成灰度圖。
def select_rgb_white_yellow(image): # 過濾背景 lower = np.uint8([120, 120, 120]) upper = np.uint8([255, 255, 255]) # 三個通道內,低于lower和高于upper的部分分別變成0, 在lower-upper之間的值變成255, 相當于mask,過濾背景 # 保留了像素值在120-255之間的像素值 white_mask = cv2.inRange(image, lower, upper) masked_img = cv2.bitwise_and(image, image, mask=white_mask) return masked_img masked_img = select_rgb_white_yellow(test_image)
這里看到inRange(),想到了之前用到的二值化的方法threshold, 我在想這倆有啥區別? 為啥這里不用這個了? 下面是我經過探索得到的幾點使用經驗:
cv2.threshold(src, thresh, maxval, type[, dst]):針對的是單通道圖像(灰度圖), 二值化的標準,type=THRESH_BINARY: if x > thresh, x = maxval, else x = 0, 而type=THRESH_BINARY_INV: 和上面的標準反著,目前常用到了這倆個
cv2.inRange(src, lowerb, upperb):可以是單通道圖像,可以是三通道圖像,也可以進行二值化,標準是if x >= lower and x <= upper, x = 255, else x = 0
這里做了一個實驗, 事先把圖片轉化成灰度圖warped = cv2.cvtColor(test_image, cv2.COLOR_BGR2GRAY),然后下面兩句代碼的執行結果是一樣的:
cv2.threshold(warped, 119, 255, cv2.THRESH_BINARY)[1]
cv2.inRange(warped, 120, 255)
處理之后的圖片長這樣:

接下來,采用Canny邊緣檢測算法,檢測出邊緣來
low_threshold, high_threshold = 50, 200 edges_img = cv2.Canny(gray_img, low_threshold, high_threshold)
結果如下:

下面嘗試把停車場這塊提取出來, 把其余那些沒用的去掉。
這里的思路就是,先用6個標定點把停車場的這幾個角給他定住,這個標定點得需要自己找。 找到之后, 采用OpenCV中的填充函數,就能制作一個mask矩陣,然后就能把其余部分去掉了。
def select_region(image):
"""這里手動選擇區域"""
rows, cols = image.shape[:2]
# 下面定義6個標定點, 這個點的順序必須讓它化成一個區域,如果調整,可能會交叉起來,所以不要動
pt_1 = [cols*0.06, rows*0.90] # 左下
pt_2 = [cols*0.06, rows*0.70] # 左上
pt_3 = [cols*0.32, rows*0.51] # 中左
pt_4 = [cols*0.6, rows*0.1] # 中右
pt_5 = [cols*0.90, rows*0.1] # 右上
pt_6 = [cols*0.90, rows*0.90] # 右下
vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32)
point_img = image.copy()
point_img = cv2.cvtColor(point_img, cv2.COLOR_GRAY2BGR)
for point in vertices[0]:
cv2.circle(point_img, (point[0], point[1]), 10, (0, 0, 255), 4)
# cv_imshow('points_img', point_img)
# 定義mask矩陣, 只保留點內部的區域
mask = np.zeros_like(image)
if len(mask.shape) == 2:
cv2.fillPoly(mask, vertices, 255) # 點框住的地方填充為白色
#cv_imshow('mask', mask)
roi_image = cv2.bitwise_and(image, mask)
return roi_image
roi_image = select_region(edges_img)處理的效果如下:

這樣處理好了,我們就需要找到這里面的直線,然后通過直線去猜測大致的位置。
這里采用霍夫變換檢測直線, 函數是cv2.HoughLinesP, 該函數能檢測直線的兩個端點(x0,y0, x1, y1)。函數原型:
HoughLinesP(image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]]) -> lines
image: 邊緣檢測的輸出圖像,這里要注意必須是邊緣檢測的輸出圖像
rho: 參數極徑r以像素值為單位的分辨率,一般1
threa: 以弧度為單位的分辨率,一般1
threshold: 檢測一條直線所需最少的曲線交點
minLineLength: 能形成一條直線的最小長度,太短,不認為是一條直線
maxLineGap: 兩條直線直接最大間隔,小于這個值,認為是一條直線
所以,這個函數拿來直接用。
def hough_lines(image): # 輸入的圖像需要是邊緣檢測后的結果 # minLineLengh(線的最短長度,比這個短的都被忽略)和MaxLineCap(兩條直線之間的最大間隔,小于此值,認為是一條直線) # rho距離精度,theta角度精度,threshod超過設定閾值才被檢測出線段 return cv2.HoughLinesP(image, rho=0.1, theta=np.pi/10, threshold=15, minLineLength=9, maxLineGap=4) list_of_lines = hough_lines(roi_image) # (2338, 1, 4)
竟然檢測到了2338條直線,這里面肯定有很多不能用的,所以后面處理,需要對直線先進行一波篩選。篩選原則是線不能是斜的,且水平方向不能太長或者是太短。 具體代碼下面會看到,這里先展示下過濾之后的效果。

過濾完了,總共628條直線。
下面的代碼會稍微復雜,所以需要分塊講思路。
首先,我們拿到了停車場的直線以及它的坐標位置。 過濾操作已經做好,接下來,就是對每條直線進行排序。 讓這些線,從一列一列的,從上往下依次排列好。
def identity_blocks(image, lines, make_copy=True): if make_copy: new_image = image.copy() # 過濾部分直線 stayed_lines = [] for line in lines: for x1, y1, x2, y2 in line: # 這里是過濾直線,必須保證不能是斜的線,且水平方向不能太長或者太短 if abs(y2-y1) <=1 and abs(x2-x1) >=25 and abs(x2-x1) <= 55: stayed_lines.append((x1,y1,x2,y2)) # 對直線按照x1排序, 這樣能讓這些線從上到下排列好, 這個排序是從第一列的第一條橫線,往下走,然后是第二列第一條橫線往下,... list1 = sorted(stayed_lines, key=operator.itemgetter(0, 1))
排列好之后,遍歷所有線, 看看相鄰兩條線之間的距離,如果是一列, 那么兩條線的x_1應該離得非常近,畢竟是同一列,如果這個值太大了,說明是下一列了。根據這個準則,遍歷完之后,就能把這些線劃分到不同的列里面。這里是用了一個字典,鍵表示列,值表示每一列里面的直線。
代碼接上:
# 找到多個列,相當于每列是一排車 clusters = collections.defaultdict(list) dIndex = 0 clus_dist = 10 # 每一列之間的那個距離 for i in range(len(list1) - 1): # 看看相鄰兩條線之間的距離,如果是一列的,那么x1這個距離應該很近,畢竟是同一列上的 # 如果這個值大于10了,說明是下一列的了,此時需要移動dIndex, 這個表示的是第幾列 distance = abs(list1[i+1][0] - list1[i][0]) if distance <= clus_dist: clusters[dIndex].append(list1[i]) clusters[dIndex].append(list1[i+1]) else: dIndex += 1
有了每一列里面的直線,下面就是就是遍歷每一列,先拿到所有直線,然后找到縱坐標的最大值和最小值,以及橫坐標的最大和最小值,但由于橫坐標這里,首尾列都一排車位,中間排都是兩列,不好直接取到最大最小坐標,所以這里采用了求平均的方式。 這樣遍歷完,針對每一列,就能得到左上角點和右下角點,這是一個矩形框。
代碼接上:
# 得到每列停車位的矩形框
rects = {}
i = 0
for key in clusters:
all_list = clusters[key]
cleaned = list(set(all_list))
# 有5個停車位至少
if len(cleaned) > 5:
cleaned = sorted(cleaned, key=lambda tup: tup[1])
avg_y1 = cleaned[0][1]
avg_y2 = cleaned[-1][1]
if abs(avg_y2-avg_y1) < 15:
continue
avg_x1 = 0
avg_x2 = 0
for tup in cleaned:
avg_x1 += tup[0]
avg_x2 += tup[2]
avg_x1 = avg_x1 / len(cleaned)
avg_x2 = avg_x2 / len(cleaned)
rects[i] = [avg_x1, avg_y1, avg_x2, avg_y2]
i += 1
print('Num Parking Lanes: ', len(rects))下面,把矩形框畫出來:
# 把列矩形畫出來 buff = 7 for key in rects: tup_topLeft = (int(rects[key][0] - buff), int(rects[key][1])) tup_botRight = (int(rects[key][2] + buff), int(rects[key][3])) cv2.rectangle(new_image, tup_topLeft, tup_botRight, (0, 255, 0), 3) return new_image, rects
這里的buff,也是進行了一點微調操作。 這種是根據實際場景來的,不是死的。 效果如下:

這樣就會發現,對于每一列的停車位,有了大致上的矩形框標定,但是這個非常粗糙。 原視頻里面就基于這個往后面走了。 我這里對于每一列框進行微調,因為這個框非常重要。不準的話影響后面的具體車位劃分。
def rect_finetune(image, rects, copy_img=True): if copy_img: image_copy = image.copy() # 下面需要對上面的框進行坐標微調, 讓框更加準確 # 這個框很重要,影響后面停車位的統計,盡量不能有遺漏 for k in rects: if k == 0: rects[k][1] -= 10 elif k == 1: rects[k][1] -= 10 rects[k][3] -= 10 elif k == 2 or k == 3 or k == 5: rects[k][1] -= 4 rects[k][3] += 13 elif k == 6 or k == 8: rects[k][1] -= 18 rects[k][3] += 12 elif k == 9: rects[k][1] += 10 rects[k][3] += 10 elif k == 10: rects[k][1] += 45 elif k == 11: rects[k][3] += 45 buff = 8 for key in rects: tup_topLeft = (int(rects[key][0]-buff), int(rects[key][1])) tup_botRight = (int(rects[key][2]+buff), int(rects[key][3])) cv2.rectangle(image_copy, tup_topLeft, tup_botRight, (0, 255, 0), 3) return image_copy, rects
微調之后的效果如下:
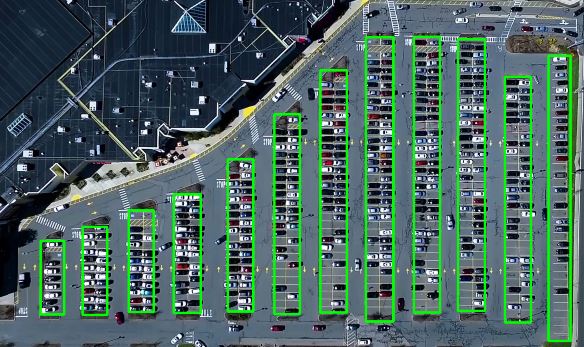
原則就是不遺漏,不多余。
這里就是針對每個矩形框, 對里面的停車位用直線切割成一個個的,每個停車位用(x1,y1,x2,y2)標識,左上角和右下角的坐標。并進行標號,最終形成一個字典,字典的鍵就是位置,值就是序號。當然,這里的一個細節,依然是中間排是兩排,首尾是一排,這個在具體劃分停車位的時候,一定要注意。
def draw_parking(image, rects, make_copy=True, save=True):
gap = 15.5
spot_dict = {} # 一個車位對應一個位置
tot_spots = 0
#微調
adj_x1 = {0: -8, 1:-15, 2:-15, 3:-15, 4:-15, 5:-15, 6:-15, 7:-15, 8:-10, 9:-10, 10:-10, 11:0}
adj_x2 = {0: 0, 1: 15, 2:15, 3:15, 4:15, 5:15, 6:15, 7:15, 8:10, 9:10, 10:10, 11:0}
fine_tune_y = {0: 4, 1: -2, 2: 3, 3: 1, 4: -3, 5: 1, 6: 5, 7: -3, 8: 0, 9: 5, 10: 4, 11: 0}
for key in rects:
tup = rects[key]
x1 = int(tup[0] + adj_x1[key])
x2 = int(tup[2] + adj_x2[key])
y1 = int(tup[1])
y2 = int(tup[3])
cv2.rectangle(new_image, (x1, y1),(x2,y2),(0,255,0),2)
num_splits = int(abs(y2-y1)//gap)
for i in range(0, num_splits+1):
y = int(y1+i*gap) + fine_tune_y[key]
cv2.line(new_image, (x1, y), (x2, y), (255, 0, 0), 2)
if key > 0 and key < len(rects) - 1:
# 豎直線
x = int((x1+x2) / 2)
cv2.line(new_image, (x, y), (x, y2), (0, 0, 255), 2)
# 計算數量 除了第一列和最后一列,中間的都是兩列的
if key == 0 or key == len(rects) - 1:
tot_spots += num_splits + 1
else:
tot_spots += 2 * (num_splits + 1)
# 字典對應好
if key == 0 or key == len(rects) - 1:
for i in range(0, num_splits+1):
cur_len = len(spot_dict)
y = int(y1 + i * gap) + fine_tune_y[key]
spot_dict[(x1, y, x2, y+gap)] = cur_len + 1
else:
for i in range(0, num_splits+1):
cur_len = len(spot_dict)
y = int(y1 + i * gap) + fine_tune_y[key]
x = int((x1+x2) / 2)
spot_dict[(x1, y, x, y+gap)] = cur_len + 1
spot_dict[(x, y, x2, y+gap)] = cur_len + 2
return new_image, spot_dict這里的fine_tune_y也是我后來加上去的,也是為了讓每一列盡量把車位劃分的準確些。

從這個效果上來看,基本上就把車位一個個的劃分開了,劃分開之后,會發現,這里面有些并不是車位, 但依然給框住了。這樣統計個數的時候,以及后面給信息停車的時候會受到影響,所以我這里又一一排查,去掉了這些無效的車位。
# 去掉多余的停車位
invalid_spots = [10, 11, 33, 34, 37, 38, 61, 62, 93, 94, 95, 97, 98, 135, 137, 138, 187, 249,
250, 253, 254, 323, 324, 327, 328, 467, 468, 531, 532]
valid_spots_dict = {}
cur_idx = 1
for k, v in spot_dict.items():
if v in invalid_spots:
continue
valid_spots_dict[k] = cur_idx
cur_idx += 1這樣,還可以把處理好的車位信息進行可視化,再進行微調,不過,我這里由于之前的一些微調操作,感覺效果還可以,就沒有做任何調整啦。
# 把每一個有效停車位標記出來
tmp_img = test_image.copy()
for k, v in valid_spots_dict.items():
cv2.rectangle(tmp_img, (int(k[0]), int(k[1])),(int(k[2]),int(k[3])), (0,255,0) , 2)
cv_imshow('valid_pot', tmp_img)效果如下:
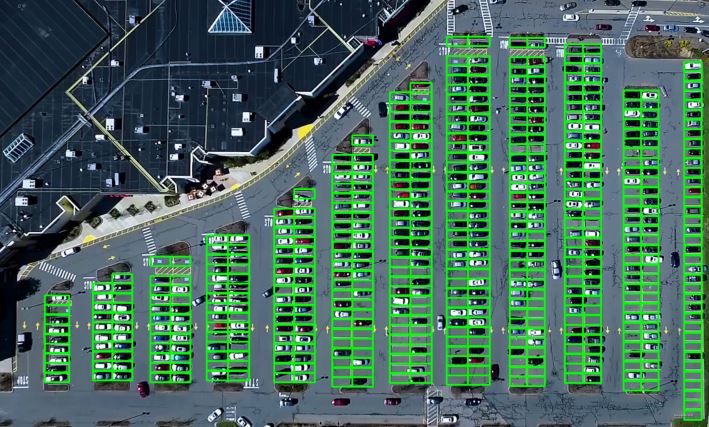
如果要想讓后面模型對于每個車位預測的更加準確,這里的劃分一定要盡量的細致和標準。 否則如果矩形框和真實的車位對應不上,比如矩形框卡在了兩個車位中間這種,這樣劃分出的車位拿給模型看,就很容易判斷出錯。
另外,最終的這個字典很重要,因為這個字典里面保存的是各個車位的位置信息。 有了這個東西,拿到一幀圖片,就可以直接把每個車位標定出來,拿給模型預測。 并且對于同一停車場,這個每個車位是固定的。所以這個也不會變,視頻的所有圖像共用。 這樣能保證實時性。
有了各個車位的具體位置信息,下面直接按照這里面的左邊把每個車位切割出來,就能得到后面CNN的訓練和驗證的數據集了。
def save_images_for_cnn(image, spot_dict, folder_name = '../cnn_pred_data'):
for spot in spot_dict.keys():
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
# 裁剪
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (0, 0), fx=2.0, fy=2.0)
spot_id = spot_dict[spot]
filename = 'spot_{}.jpg'.format(str(spot_id))
# print(spot_img.shape, filename, (x1,x2,y1,y2))
cv2.imwrite(os.path.join(folder_name, filename), spot_img)
save_images_for_cnn(test_image, valid_spots_dict)這樣,就把模型的訓練數據集準備好。 在文件中組織成這個樣子:
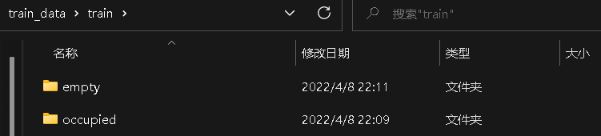
每個目錄里面,就是劃分出來的一張張小的車位圖像,不過這里是人為劃分到了有車還是無車里面。所以后面的模型其實做一個二分類任務,給定這樣一張車位的小圖像,預測下是不是空的即可。
下面開始說模型的細節。
由于目前的樣本非常少,不足以訓練一個大模型到收斂,所以這里采用的遷移學習技術,用的預訓練模型。
模型這里和視頻中不一樣的是,我統一采用pytorch寫的模型訓練和測試代碼,原因是最近正在嘗試pytorch復現cv里面的各個經典網絡,這個項目正好讓我拿來練手。另外一個就是感覺keras搭建的靈活度不夠,在數據預處理方面不如torchvision里面transforms用起來方便。 基于這兩個原因, 我這里直接用pytorch,采用的resnet34預訓練模型,使用這個的原因是這兩天正好把resnet復現了一遍,稍微熟悉了一點罷了,正好能學以致用,沒有啥偏愛。
由于這里的代碼非常多,這里就不過多羅列了,簡單說下邏輯即可,感興趣的可以看具體項目。
首先是訓練模型。
這個整體邏輯倒是可以看下:
def train_model(): # 獲取dataloader data_root = os.getcwd() image_path = os.path.join(data_root, "train_data") train_data_path = os.path.join(image_path, "train") val_data_path = os.path.join(image_path, "test") train_loader, validat_loader, train_num, val_num = get_dataloader(train_data_path, val_data_path, data_transform_pretrain, batch_size=8) # 創建模型 注意這里沒指定類的個數,默認是1000類 net = resnet34() model_weight_path = 'saved_model_weight/resnet34_pretrain_ori_low_torch_version.pth' # 使用預訓練的參數,然后進行finetune net.load_state_dict(torch.load(model_weight_path, map_location='cpu')) # 改變fc layer structure 把fc的輸出維度改為2 in_channel = net.fc.in_features net.fc = nn.Linear(in_channel, 2) net.to(device) # 模型訓練配置 loss_function = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.0001) epochs = 30 save_path = "saved_model_weight/resnet34_pretrain.pth" best_acc = 0. train_steps = len(train_loader) model_train(net, train_loader, validat_loader, epochs, device, optimizer, loss_function, train_steps, val_num, save_path, best_acc)
因為我這里采用了一些函數封裝,所以這個邏輯應該稍微清晰些,首先pytorch模型訓練,要先把數據封裝成dataloader的格式,后面模型訓練的時候,是從這個類里面讀取數據。關于dataloader與dataset的原理這里就不過多整理。之前我詳細在pytorch基礎那里整理過了。
不過這里的細節,就是data_transform_pretrain, 也就是數據預處理操作。
data_transform_pretrain = {
"train": transforms.Compose([
transforms.RandomResizedCrop(224), # 對圖像隨機裁剪, 訓練集用,驗證集不用
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# 這里的中心化處理參數需要官方給定的參數,這里是ImageNet圖片的各個通道的均值和方差,不能隨意指定了
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
]),
"val": transforms.Compose([
# 驗證過程中,這里也進行了一點點改動
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
]),
"test": transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
}這里由于是采用的官方訓練好的resnet網絡,我們這里中心化要參考官方給定的參數,因為它預訓練是ImageNet這個大數據集上訓練的,所以這里每個通道的均值和方差,我們最好別隨意指定。用人家官方給出的。
有了dataloader,接下來創建模型, 這里是直接使用的resnet34, 把預訓練的模型參數導入進來。導入的時候,會發現我這個參數名字的文件有個low_torch_version, 是因為之前導入的時候出現了報錯:
xxx.pt is a zip archive(did you mean to use torch.jit.load()?)“
這個報錯的原因是,官方預訓練保存的模型參數使用的pytorch版本是1.6以上,PyTorch的1.6版本將torch.save切換為使用新的基于zipfile的文件格式。
torch.load仍然保留以舊格式加載文件的功能。 如果希望torch.save使用舊格式,請傳遞kwarg _use_new_zipfile_serialization = False。
我電腦本子的pytorch版本是1.0,所以導入1.6以上版本保存的模型參數,就會報這樣的錯誤。 那么,我怎么解決的呢? 那就是從我服務器上,運行了下面這個代碼
model_weight_path = "saved_models/resnet34_pretrain_ori.pth" state_dict = torch.load(model_weight_path) torch.save(state_dict, 'saved_models/resnet34_pretrain_ori_low_torch_version.pth', _use_new_zipfile_serialization=False)
我服務器上的pytorch版本是1.10的版本,是能導入這個參數的,導入完了重新保存,指定官方給定的參數即可。
這個問題解決之后,下面就說下預訓練模型了, 導入參數之后,我們需要修改網絡最后的一層,因為resnet本身做的是1000分類,最后一層神經元個數是1000,我們這里需要做二分類,所以需要改成2。
另外,就是遷移學習的三種方式:
載入權重后重新訓練所有參數 – 硬件設施好
載入權重后只訓練最后幾層參數,前面的層進行凍結, 或者是前面幾層的學習率降低, 后面全連接層的學習率變大,即分組調整學習率
載入全中后在原網絡基礎上再添加一層全連接層, 僅訓練最后一個全連接層
我這里采用的全部訓練的方式,但是這里有必要整理下,如果是想只訓練后面幾層,或者前面層和后面層不同學習率訓練的時候,應該怎么做:
# 創建模型 注意這里沒指定類的個數,默認是1000類
net = resnet34()
model_weight_path = 'saved_model_weight/resnet34_pretrain_ori_low_torch_version.pth'
# 使用預訓練的參數,然后進行finetune
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# 改變fc layer structure 把fc的輸出維度改為2
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 2)
net.to(device)
# 模型訓練配置
loss_function = nn.CrossEntropyLoss()
# 訓練的時候,也可以凍結掉卷積層的參數, 也可以指定不同層的參數使用不同的學習率進行訓練
res_params, conv_params, fc_params = [], [], []
# named_parameters()能返回每一層的名字以及參數,是一個字典
for name, param in net.named_parameters():
# layer 系列是殘差層
if ('layer' in name):
res_params.append(param)
# 全連接層
elif ('fc' in name):
fc_params.append(param)
else:
param.requires_grad = False
params = [
{'params': res_params, 'lr': 0.0001},
{'params': fc_params, 'lr': 0.0002},
]
optimizer = optim.Adam(params)這里修改優化器的參數即可。
這樣完事之后,調用模型訓練的函數,直接進行訓練即可。這個腳本就是常規操作了,這里就不貼代碼了。
有了保存好的模型, 我們拿來一幀圖像,根據停車位字典劃分出一個個的停車位來,然后通過模型預測是不是空的,如果是空的, 在原圖上進行標記出來即可。
所以下面是整個項目的核心預測:
def predict_on_img(img, spot_dict, model, class_indict, make_copy=True, color=[0, 255, 0], alpha=0.5, save=True):
# 這個是停車場的全景圖像
if make_copy:
new_image = np.copy(img)
overlay = np.copy(img)
cnt_empty, all_spots = 0, 0
for spot in tqdm(spot_dict.keys()):
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = img[y1:y2, x1:x2]
spot_img_pil = Image.fromarray(spot_img)
label = model_infer(spot_img_pil, model, class_indict)
if label == 'empty':
cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
# 顯示結果的
cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
if save:
filename = 'with_marking_predict.jpg'
cv2.imwrite(filename, new_image)
# cv_imshow('new_image', new_image)
return new_image模型預測的核心,就是model_infer函數,這個也是模型預測的常規操作,這里不過多解釋了。
視頻的話,無非就是多幀圖像,對于每一幀過一下這個函數,就能進行視頻的實時預測:
def predict_on_video(video_path, spot_dict, model, class_indict, ret=True):
cap = cv2.VideoCapture(video_path)
count = 0
while ret:
ret, image = cap.read()
count += 1
if count == 5:
count = 0
new_image = predict_on_img(image, spot_dict, model, class_indict, save=False)
cv2.imshow('frame', new_image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
cap.release()以上就是關于“OpenCV停車場車位實時檢測項目分析”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





