溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Python怎么實現微博動態圖片爬取”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Python怎么實現微博動態圖片爬取”吧!
我們找到微博在瀏覽器上面用于手機端的調試的APL,如何找到呢?

1.模擬搜索用戶

搜索一個用戶獲取到的api:
https://m.weibo.cn/api/container/getIndex?containerid=100103type=1&q=半半子&page_type=searchall
1.1 對api內參數進行處理
containerid=100103type=1&q=半半子 ——> containerid=100103type%3D1%26q%3D%E5%8D%8A%E5%8D%8A%E5%AD%90_
這個參數需要提前轉碼,否則無法獲取數據
1.2 對用戶名進行判斷,通過后提取uid
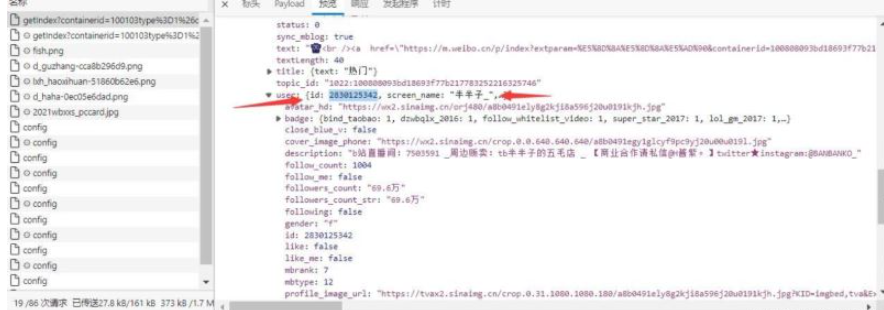
2.獲取more參數
GET
api : https://m.weibo.cn/profile/info?uid=2830125342
2.1 提取并處理more參數
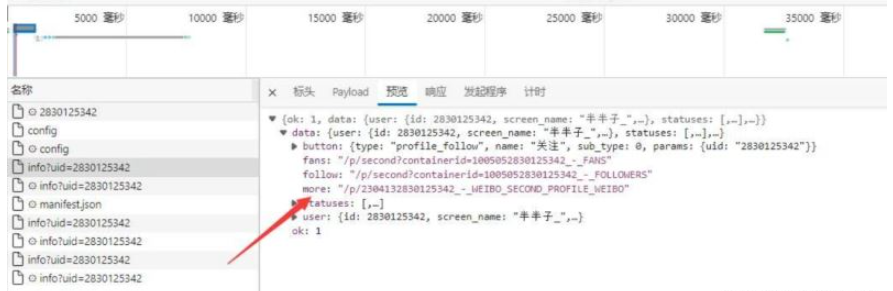
3.循環提取圖片id
GET
api : https://m.weibo.cn/api/container/getIndex?containerid=2304132830125342_-_WEIBO_SECOND_PROFILE_WEIBO&page_type=03&page=1
3.1 提取圖片id——>pic_id
3.2 獲取發送圖片用戶
3.3 根據動態創建時間生成用戶唯一識別碼
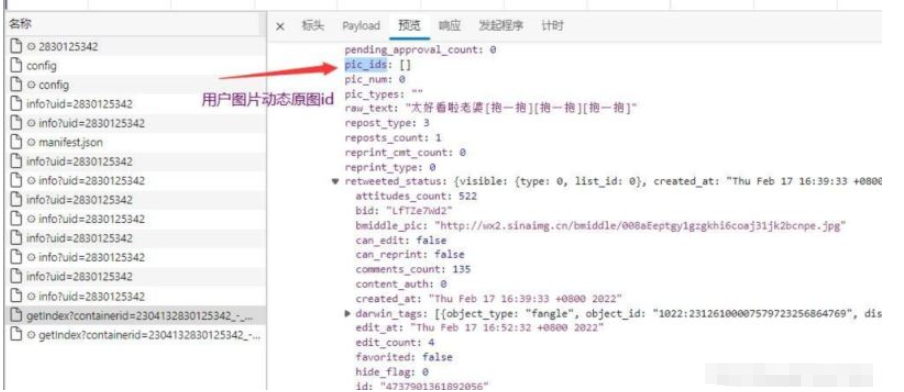
4.下載圖片
我們從瀏覽器抓包中就會獲取到后臺服務器發給瀏覽器的圖片鏈接
https://wx2.sinaimg.cn/large/pic_id.jpg
瀏覽器打開這個鏈接就可以直接下載圖片
爬取完整代碼:
import os
import sys
import time
from urllib.parse import quote
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
def time_to_str(c_at):
ti = time.strptime(c_at, '%a %b %d %H:%M:%S +0800 %Y')
time_str = time.strftime('%Y%m%d%H%M%S', ti)
return time_str
# 1. 搜索用戶,獲取uid
# 2. 通過uid獲取空間動態關鍵參數
# 3. 獲取動態內容
# 4. 提取圖片參數
# 5. 下載圖片
# 1. 搜索用戶,獲取uid
# ========= 用戶名 =========
# 輸入不同的用戶名可切換下載的用戶圖片
# 用戶名需要完全匹配
name = '半半子_'
# =========================
con_id = f'100103type=1&q={name}'
# 這個條件需要轉碼
con_id = quote(con_id, 'utf-8')
user_url = f'https://m.weibo.cn/api/container/getIndex?containerid={con_id}&page_type=searchall'
user_json = requests.get(url=user_url, headers=headers).json()
user_cards = user_json['data']['cards']
for card_num in range(len(user_cards)):
if 'mblog' in user_cards[card_num]:
if user_cards[card_num]['mblog']['user']['screen_name'] == name:
print(f'正在獲取{name}的空間')
# 2. 通過uid獲取空間動態關鍵參數
user_id = user_cards[card_num]['mblog']['user']['id']
info_url = f'https://m.weibo.cn/profile/info?uid={user_id}'
info_json = requests.get(url=info_url, headers=headers).json()
more_card = info_json['data']['more'].split("/")[-1]
break
file_name = 'weibo'
if not os.path.exists(file_name):
os.mkdir(file_name)
if len(more_card) == 0:
sys.exit()
page_type = '03'
page = 0
while True:
# 3. 獲取動態內容
page += 1
url = f'https://m.weibo.cn/api/container/getIndex?containerid={more_card}&page_type={page_type}&page={page}'
param = requests.get(url=url, headers=headers).json()
cards = param['data']['cards']
print(f'第 {page} 頁')
for i in range(len(cards)):
card = cards[i]
if card['card_type'] != 9:
continue
mb_log = card['mblog']
# 4. 提取圖片參數
# 獲取本人的圖片
pic_ids = mb_log['pic_ids']
user_name = mb_log['user']['screen_name']
created_at = mb_log['created_at']
if len(pic_ids) == 0:
# 獲取轉發的圖片
if 'retweeted_status' not in mb_log:
continue
if 'pic_ids' not in mb_log['retweeted_status']:
continue
pic_ids = mb_log['retweeted_status']['pic_ids']
user_name = mb_log['retweeted_status']['user']['screen_name']
created_at = mb_log['retweeted_status']['created_at']
time_name = time_to_str(created_at)
pic_num = 1
print(f'======== {user_name} ========')
# 5. 下載圖片
for pic_id in pic_ids:
pic_url = f'https://wx2.sinaimg.cn/large/{pic_id}.jpg'
pic_data = requests.get(pic_url, headers)
# 文件名 用戶名_日期(年月日時分秒)_編號.jpg
# 例:半半子__20220212120146_1.jpg
with open(f'{file_name}/{user_name}_{time_name}_{pic_num}.jpg', mode='wb') as f:
f.write(pic_data.content)
print(f' 正在下載:{pic_id}.jpg')
pic_num += 1
time.sleep(2)到此,相信大家對“Python怎么實現微博動態圖片爬取”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





