溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下linux上numa架構實例分析的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。

以下案例基于 Ubuntu 16.04,同樣適用于其他的 Linux 系統。我使用的案例環境如下所示:
機器配置:32 CPU,64GB 內存
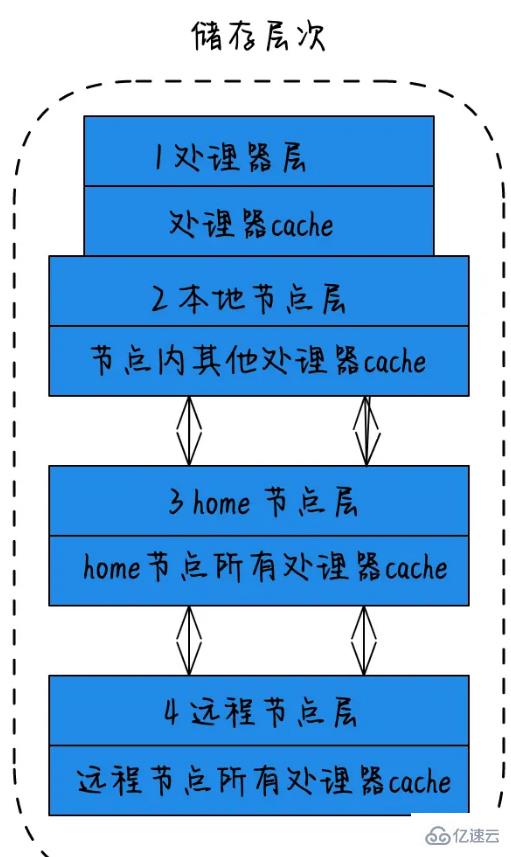
1)處理器層:單個物理核,稱為處理器層。
2)本地節點層:對于某個節點中的所有處理器,此節點稱為本地節點。
3)home節點層:與本地節點相鄰的節點稱為home節點。
4)遠程節點層:非本地節點或鄰居節點的節點,稱為遠程節點。CPU訪問不同類型節點內存的速度是不相同的,訪問本地節點的速度最快,訪問遠端節點的速度最慢,即訪問速度與節點的距離有關,距離越遠訪問速度越慢,此距離稱作Node Distance。應用程序要盡量的減少不同CPU模塊之間的交互,如果應用程序能有方法固定在一個CPU模塊里,那么應用的性能將會有很大的提升。
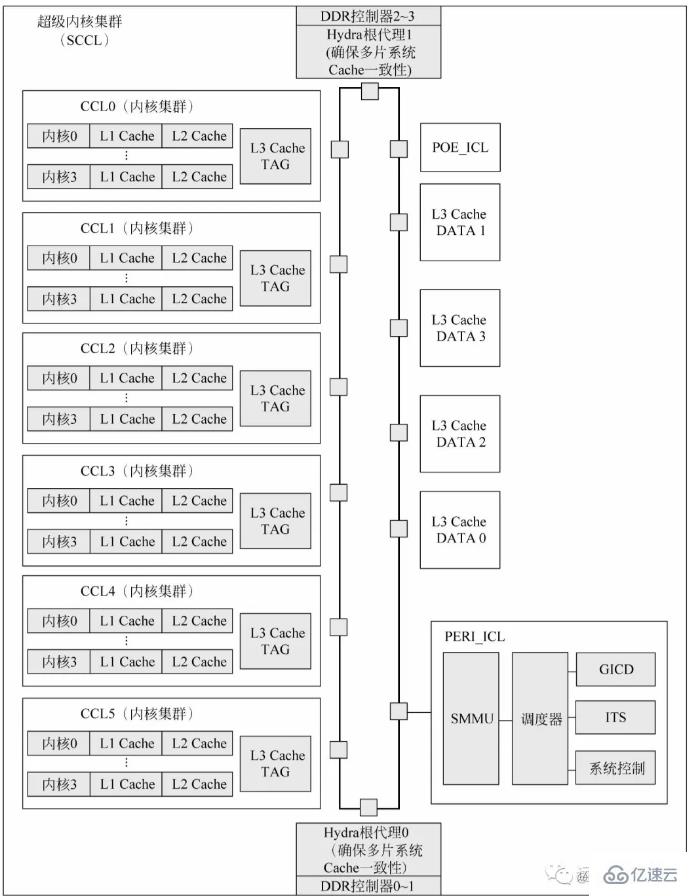
**以鯤鵬920處理器講一下cpu芯片的的構成:**鯤鵬920處理器片上系統的每個超級內核集群包含6個內核集群、2個I/O集群和4個DDR控制器。每個超級內核集群封裝成一個CPU晶片。每個晶片上集成了4個72位(64位數據加8位ECC)、數據傳輸率最高為3200MT/s的高速DDR4通道,單晶片可支持最多512GB×4的DDR存儲空間。L3 Cache在物理上被分為兩部分:L3 Cache TAG和L3 Cache DATA。L3 Cache TAG集成在每個內核集群中,以降低監聽延遲。L3 Cache DATA則直接連接片上總線。Hydra根代理(Hydra Home Agent,HHA)是處理多芯片系統Cache一致性協議的模塊。POE_ICL是系統配置的硬件加速器,一般可以用作分組順序整理器、消息隊列、消息分發或者實現某個處理器內核的特定任務等。此外,每個超級內核集群在物理上還配置了一個通用中斷控制器分發器(GICD)模塊,兼容ARM的GICv4規范。當單芯片或多芯片系統中有多個超級內核集群時,只有一個GICD對系統軟件可見。
Linux提供了一個一個手工調優的命令numactl(默認不安裝),在Ubuntu上的安裝命令如下:
sudo apt install numactl -y
首先你可以通過man numactl或者numactl --h了解參數的作用與輸出的內容。查看系統的numa狀態:
numactl --hardware
運行得到如下的結果:
available: 4 nodes (0-3) node 0 cpus: 0 1 2 3 4 5 6 7 node 0 size: 16047 MB node 0 free: 3937 MB node 1 cpus: 8 9 10 11 12 13 14 15 node 1 size: 16126 MB node 1 free: 4554 MB node 2 cpus: 16 17 18 19 20 21 22 23 node 2 size: 16126 MB node 2 free: 8403 MB node 3 cpus: 24 25 26 27 28 29 30 31 node 3 size: 16126 MB node 3 free: 7774 MB node distances: node 0 1 2 3 0: 10 20 20 20 1: 20 10 20 20 2: 20 20 10 20 3: 20 20 20 10
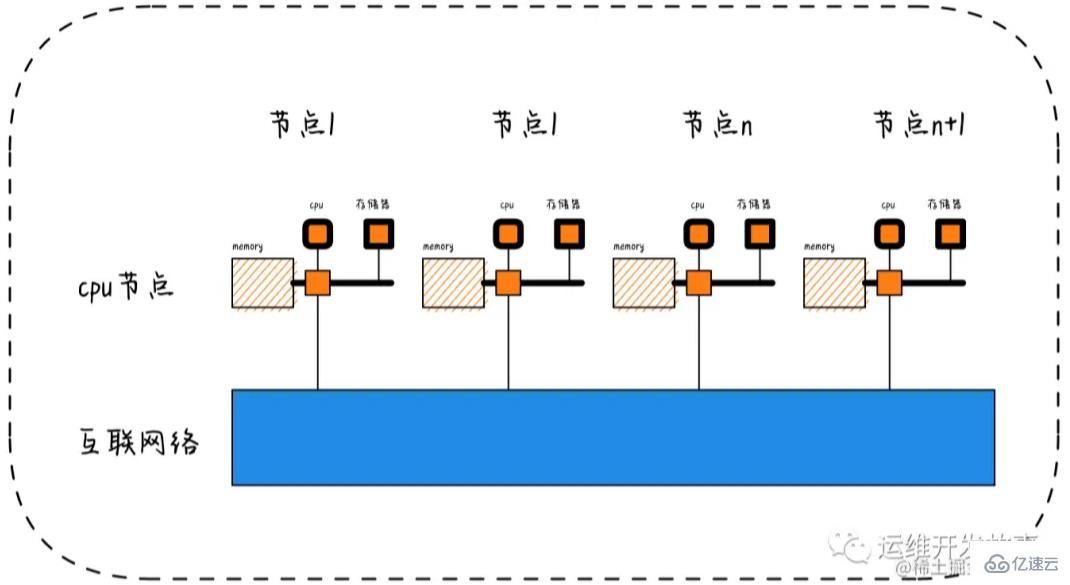
根據這個圖與命令得到的結果,可以看到,此系統共有4個node,各領取8個CPU和16G內存。 這里還需要注意的就是CPU共享的L3 cache也是會自己領取相應的空間。通過numastat命令可以查看numa狀態,返回值內容:
numa_hit:是打算在該節點上分配內存,最后從這個節點分配的次數;
numa_miss:是打算在該節點分配內存,最后卻從其他節點分配的次數;
numa_foreign:是打算在其他節點分配內存,最后卻從這個節點分配的次數;
interleave_hit :采用interleave策略最后從本節點分配的次數
local_node:該節點上的進程在該節點上分配的次數
other_node:是其他節點進程在該節點上分配的次數
注:如果發現 numa_miss 數值比較高時,說明需要對分配策略進行調整。例如將指定進程關聯綁定到指定的CPU上,從而提高內存命中率。
root@ubuntu:~# numastat node0 node1 node2 node3 numa_hit 19480355292 11164752760 12401311900 12980472384 numa_miss 5122680 122652623 88449951 7058 numa_foreign 122652643 88449935 7055 5122679 interleave_hit 12619 13942 14010 13924 local_node 19480308881 11164721296 12401264089 12980411641 other_node 5169091 122684087 88497762 67801
--localalloc或者-l:規定進程從本地節點上請求分配內存。--membind=nodes或者-m nodes:規定進程只能從指定的nodes上請求分配內存。--preferred=node:指定一個推薦的node來獲取內存,如果獲取失敗,則嘗試別的node。--interleave=nodes或者-i nodes:規定進程從指定的nodes上,以round robin算法交織地請求內存分配。
numactl --interleave=all mongod -f /etc/mongod.conf
因為NUMA默認的內存分配策略是優先在進程所在CPU的本地內存中分配,會導致CPU節點之間內存分配不均衡,當開啟了swap,某個CPU節點的內存不足時,會導致swap產生,而不是從遠程節點分配內存。這就是所謂的swap insanity 現象。或導致性能急劇下降。所以在運維層面,我們也需要關注NUMA架構下的內存使用情況(多個內存節點使用可能不均衡),并合理配置系統參數(內存回收策略/Swap使用傾向),盡量去避免使用到Swap。
Node->Socket->Core->Processor
隨著多核技術的發展,將多個CPU封裝在一起,這個封裝被稱為插槽Socket;Core是socket上獨立的硬件單元;通過intel的超線程HT技術進一步提升CPU的處理能力,OS看到的邏輯上的核Processor數量。
Socket = Node
Socket是物理概念,指的是主板上CPU插槽;Node是邏輯概念,對應于Socket。
Core = 物理CPU
Core是物理概念,一個獨立的硬件執行單元,對應于物理CPU;
Thread = 邏輯CPU = Processor
Thread是邏輯CPU,也就是Processo
lscpu的使用
顯示格式:
Architecture:架構
CPU(s):邏輯cpu顆數
Thread(s) per core:每個核心線程,也就是指超線程
Core(s) per socket:每個cpu插槽核數/每顆物理cpu核數
CPU socket(s):cpu插槽數
L1d cache:級緩存(google了下,這具體表示表示cpu的L1數據緩存)
L1i cache:一級緩存(具體為L1指令緩存)
L2 cache:二級緩存
L3 cache:三級緩存
NUMA node0 CPU(s) :CPU上的邏輯核,也就是超線程
執行lscpu,結果部分如下:
root@ubuntu:~# lscpu Architecture: x86_64 CPU(s): 32 Thread(s) per core: 1 Core(s) per socket: 8 Socket(s): 4 L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 20480K NUMA node0 CPU(s): 0-7 NUMA node1 CPU(s): 8-15 NUMA node2 CPU(s): 16-23 NUMA node3 CPU(s): 24-31
以上就是“linux上numa架構實例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





