溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python Pandas讀取Excel日期數據的異常處理怎么辦,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
有時我們的Excel有一個調整過自定義格式的日期字段:
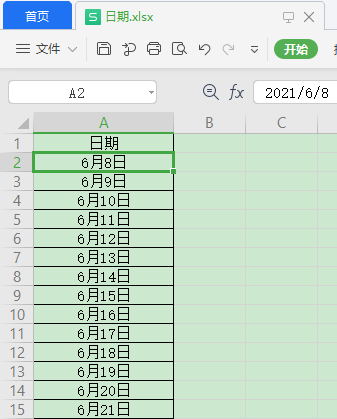
當我們用pandas讀取時卻是這樣的效果:
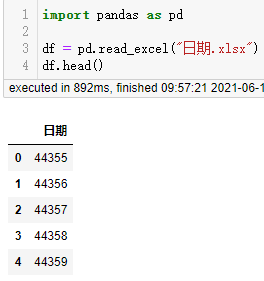
不管如何指定參數都無效。
沒有使用系統內置的日期單元格格式,自定義格式沒有對負數格式進行定義,pandas讀取時無法識別出是日期格式,而是讀取出單元格實際存儲的數值。
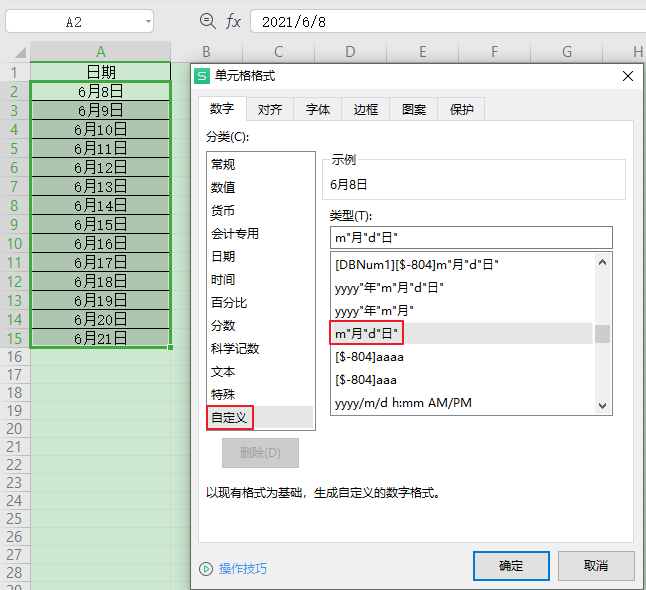
可以修改為系統內置的自定義格式:
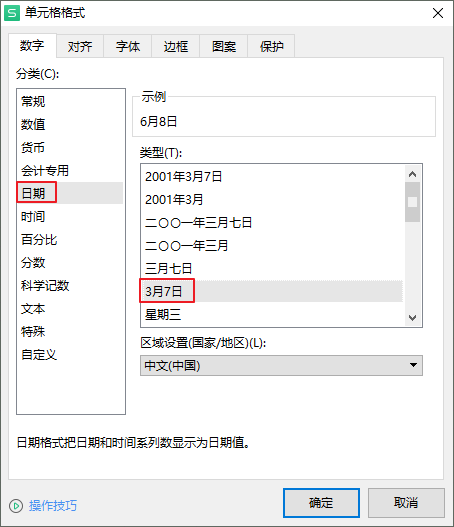
或者在自定義格式上補充負數的定義:
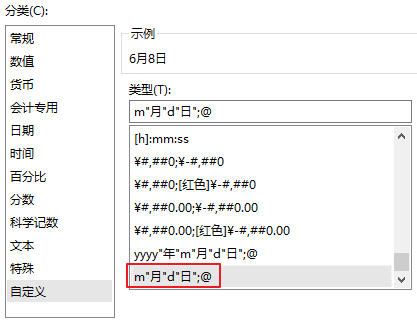
增加;@即可
有時這種Excel很多,我們需要通過pandas批量讀取,挨個人工修改Excel的自定義格式費時費力,下面我演示如何使用pandas直接解析這些數值成為日期格式。
excel中常規格式和日期格式的轉換規則如下:
1900/1/1為起始日期,轉換的數字是1,往后的每一天增加1
1900/1/2轉換為數字是 2
1900/1/3轉換為數字是 3
1900/1/4轉換為數字是 4
以此類推
excel中時間轉換規則如下:
在時間中的規則是把1天轉換為數字是 1
每1小時就是 1/24
每1分鐘就是 1/(24×60)=1/1440
每1秒鐘就是 1/(24×60×60)=1/86400
根據Excel的日期存儲規則,我們只需要以1900/1/1為基準日期,根據數值n偏移n-1天即可得到實際日期。不過還有個問題,Excel多存儲了1900年2月29日這一天,而正常的日歷是沒有這一天的,而我們的日期又都是大于1900年的,所以應該偏移n-2天,干脆使用1899年12月30日作為基準,這樣不需要作減法操作。
解析代碼如下:
import pandas as pd
from pandas.tseries.offsets import Day
df = pd.read_excel("日期.xlsx")
basetime = pd.to_datetime("1899/12/30")
df.日期 = df.日期.apply(lambda x: basetime+Day(x))
df.日期 = df.日期.apply(lambda x: f"{x.month}月{x.day}日")
df.head()| 日期 | |
|---|---|
| 0 | 6月8日 |
| 1 | 6月9日 |
| 2 | 6月10日 |
| 3 | 6月11日 |
| 4 | 6月12日 |
如果需要調用time的strftime方法,由于包含中文則需要設置locale:
import pandas as pd
from pandas.tseries.offsets import Day
import locale
locale.setlocale(locale.LC_CTYPE, 'chinese')
df = pd.read_excel("日期.xlsx")
basetime = pd.to_datetime("1899/12/30")
df.日期 = df.日期.apply(lambda x: basetime+Day(x))
df.日期 = df.日期.dt.strftime('%Y年%m月%d日')
df.head()| 日期 | |
|---|---|
| 0 | 2021年06月08日 |
| 1 | 2021年06月09日 |
| 2 | 2021年06月10日 |
| 3 | 2021年06月11日 |
| 4 | 2021年06月12日 |
看完了這篇文章,相信你對“Python Pandas讀取Excel日期數據的異常處理怎么辦”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





