溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Python如何實現實時增量數據加載工具,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
單例模式:提供全局訪問點,確保類有且只有一個特定類型的對象。通常用于以下場景:日志記錄或數據庫操作等,避免對用一資源請求沖突。
import sqlite3
import datetime
import pymssql
import pandas as pd
import time
pd.set_option('expand_frame_repr', False)導入所需模塊
# 創建數據表 database_path = r'.\Database\ID_Record.db' from sqlite3 import connect with connect(database_path) as conn: conn.execute( 'CREATE TABLE IF NOT EXISTS Incremental_data_max_id_record(id INTEGER PRIMARY KEY AUTOINCREMENT,F_SDaqID_MAX TEXT,record_date datetime)')
增量最新記錄ID-F_SDaqID_MAX數據庫存儲
#數據保存到本地txt
def text_save(filename, record):#filename為寫入txt文件的路徑,record為要寫入F_SDaqID_MAX、record_date數據列表.
file = open(filename,'a') 追加方式
# file = open(filename, 'w') #覆蓋方式
for i in range(len(record)):
s = str(record[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',','') +'\n' #去除單引號,逗號,每行末尾追加換行符
file.write(s)
file.close()增量最新記錄ID-F_SDaqID_MAX臨時文件存儲
增量ID記錄提供了兩種實現方案 ,一個是數據持久化存儲模式,另一個是臨時文件存儲模式。數據持久化模式顧名思義,也就是說在創建對象的時候,能將操作關鍵信息如增量ID-F_SDaqID_MAX記錄下來,這種flag記錄映射是常選擇的設計模式。
實現實時增量數據獲取需要實現兩個數據庫連接類:增量數據ID存儲類和增量目標數據源類。這里利用單例模式實現數據庫操作類,將增量服務記錄信息按照順序存儲到數據庫或特定的日志文件中,以維護數據的一致性。
1、增量數據ID存儲sqlite連接類代碼
class Database_sqlite(metaclass=MetaSingleton):
database_path = r'.\Database\energy_rc_configure.db'
connection = None
def connect(self):
if self.connection is None:
self.connection = sqlite3.connect(self.database_path,check_same_thread=False,isolation_level=None)
self.cursorobj = self.connection.cursor()
return self.cursorobj,self.connection
# 插入最大記錄
@staticmethod
def Insert_Max_ID_Record(f1, f2):
cursor = Database_sqlite().connect()
print(cursor)
sql = f"""insert into Incremental_data_max_id_record(F_SDaqID_MAX,record_date) values("{f1}","{f2}")"""
cursor[0].execute(sql)
# sql = "insert into Incremental_data_max_id_record(F_SDaqID_MAX,record_date) values(?,?)"
# cursor[0].execute(sql,(f"{f1}",f"{f2}"))
cursor[1].commit()
print("插入成功!")
# cursor[0].close()
return
# 取出增量數據庫中最新一次ID記錄
@staticmethod
def View_Max_ID_Records():
cursor = Database_sqlite().connect()
sql = "select max(F_SDaqID_MAX) from Incremental_data_max_id_record"
cursor[0].execute(sql)
results = cursor[0].fetchone()[0]
# #單例模式不用關閉數據庫連接
# cursor[0].close()
print("最新記錄ID", results)
return results
#刪除數據記錄ID
@staticmethod
def Del_Max_ID_Records():
cursor = Database_sqlite().connect()
sql = "delete from Incremental_data_max_id_record where record_date = (select MAX(record_date) from Incremental_data_max_id_record)"
cursor[0].execute(sql)
# results = cursor[0].fetchone()[0]
# # cursor[0].close()
cursor[1].commit()
print("刪除成功")
return2、增量數據源sqlserver連接類代碼
class Database_sqlserver(metaclass=MetaSingleton):
"""
#實時數據庫
"""
connection = None
# def connect(self):
def __init__(self):
if self.connection is None:
self.connection = pymssql.connect(host="xxxxx",user="xxxxx",password="xxxxx",database="xxxxx",charset="utf8")
if self.connection:
print("連接成功!")
# 打開數據庫連接
self.cursorobj = self.connection.cursor()
# return self.cursorobj, self.connection
# 獲取數據源中最大ID
@staticmethod
def get_F_SDaqID_MAX():
# cursor_insert = Database_sqlserver().connect()
cursor_insert = Database_sqlserver().cursorobj
sql_MAXID = """select MAX(F_SDaqID) from T_DaqDataForEnergy"""
cursor_insert.execute(sql_MAXID) # 執行查詢語句,選擇表中所有數據
F_SDaqID_MAX = cursor_insert.fetchone()[0] # 獲取記錄
print("最大ID值:{0}".format(F_SDaqID_MAX))
return F_SDaqID_MAX
# 提取增量數據
@staticmethod
def get_incremental_data(incremental_Max_ID):
# 開始獲取增量數據
sql_incremental_data = """select F_ID,F_Datetime,F_Data from T_DaqDataForEnergy where F_ID > {0}""".format(
incremental_Max_ID)
# cursor_find = Database_sqlserver().connect()
cursor_find = Database_sqlserver().cursorobj
cursor_find.execute(sql_incremental_data) # 執行查詢語句,選擇表中所有數據
Target_data_source = cursor_find.fetchall() # 獲取所有數據記錄
# cursor_find.close()
cursor_find.close()
df = pd.DataFrame(
Target_data_source,
columns=[
"F_ID",
"F_Datetime",
"F_Data"])
print("提取數據", df)
return df數據資源應用服務設計主要考慮數據庫操作的一致性和優化數據庫的各種操作,提高內存或CPU利用率。
實現多種讀取和寫入操作,客戶端操作調用API,執行相應的DB操作。
注:
1、使用metaclass實現創建具有單例特征的類
Database_sqlserver(metaclass=MetaSingleton)
Database_sqlite(metaclass=MetaSingleton)
使用class定義新類時,數據庫類Database_sqlserver由MetaSingleton裝飾后即指定了metaclass,那么MetaSingleton的特殊方法__call__方法將自動執行。
class MetaSingleton(type):
_instances={}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super(MetaSingleton,cls).__call__(*args,**kwargs)
return cls._instances[cls]以上代碼基于元類的單例實現,當客戶端對數據庫執行某些操作時,會多次實例化數據庫類,但是只創建一個對象,所以對數據庫的調用是同步的。
2、多線程使用同一數據庫連接資源需采取一定同步機制
如果沒采用同步機制,可能出現一些意料之外的情況
1)with cls.lock加鎖
class MetaSingleton(type):
_instances={}
lock = threading.Lock()
def __call__(cls, *args, **kwargs):
with cls.lock:
if cls not in cls._instances:
time.sleep(0.05) #模擬耗時
cls._instances[cls] = super(MetaSingleton,cls).__call__(*args,**kwargs)
return cls._instances[cls]鎖的創建和釋放需要消耗資源,上面代碼每次創建都必須獲得鎖。
3、如果我們開發的程序非單個應用,而是集群化的,即多個客戶端共享單個數據庫,導致數據庫操作無法同步,而數據庫連接池是更好的選擇。大大節省了內存,提高了服務器地服務效率,能夠支持更多的客戶服務。
數據庫連接池的解決方案是在應用程序啟動時建立足夠的數據庫連接,并講這些連接組成一個連接池,由應用程序動態地對池中的連接進行申請、使用和釋放。對于多于連接池中連接數的并發請求,應該在請求隊列中排隊等待。
增量處理策略:第一次加載先判斷增量數據表中是否存在最新記錄,若有直接加載;否則,記錄一下最大/最新的數據記錄ID或時間點,保存到一個增量數據庫或記錄文件中。
從第二次加載開始只加載最大/最新的ID或時間點以后的數據。當加載過程全部成功完成之后并同步更新增量數據庫或記錄文件,更新這次數據記錄的最后記錄ID或時間點。
一般這類數據記錄表有自增長列,那么也可以使用自增長列來實現這個標識特征。比如本次我用到數據表增長列F_ID。
class IncrementalRecordServer:
_servers = []
_instance = None
def __new__(cls, *args, **kwargs):
if not IncrementalRecordServer._instance:
# IncrementalRecordServer._instance = super().__new__(cls)
IncrementalRecordServer._instance = super(IncrementalRecordServer,cls).__new__(cls)
return IncrementalRecordServer._instance
def __init__(self,changeServersID=None):
"""
變量初始化過程
"""
self.F_SDaqID_MAX = Database_sqlserver().get_F_SDaqID_MAX()
self.record_date = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
self.changeServersID = changeServersID
# 回調更新本地記錄,清空記錄替換,臨時記錄
def record(func):
def Server_record(self):
v = func(self)
text_save(filename=r"F:\AutoOps_platform\Database\Server_record.txt",record=IncrementalRecordServer._servers)
print("保存成功")
return v
return Server_record
#增加服務記錄
@record
def addServer(self):
self._servers.append([int(self.F_SDaqID_MAX),self.record_date])
print("添加記錄")
Database_sqlite.Insert_Max_ID_Record(f1=self.F_SDaqID_MAX, f2=self.record_date)
#修改服務記錄
@record
def changeServers(self):
# self._servers.pop()
# 此處傳入手動修改的記錄ID
self._servers.append([self.changeServersID,self.record_date])
#先刪除再插入實現修改
Database_sqlite.Del_Max_ID_Records()
Database_sqlite.Insert_Max_ID_Record(f1=self.changeServersID, f2=self.record_date)
print("更新記錄")
#刪除服務記錄
@record
def popServers(self):
# self._servers.pop()
print("刪除記錄")
Database_sqlite.Del_Max_ID_Records()
# 最新服務記錄
def getServers(self):
# print(self._servers[-1])
Max_ID_Records = Database_sqlite.View_Max_ID_Records()
print("查看記錄",Max_ID_Records)
return Max_ID_Records
#提取數據
def Incremental_data_client(self):
"""
# 提取數據(增量數據MAXID獲取,并提取增量數據)
"""
# 實時數據庫
# 第一次加載先判斷是否存在最新記錄
if self.getServers() == None:
# 插入增量數據庫ID
self.addServer()
# 提取增量數據
data = Database_sqlserver.get_incremental_data(self.F_SDaqID_MAX)
return data
# 獲取增量數據庫中已有的最新最大ID記錄
incremental_Max_ID = self.getServers()
#添加記錄
self.addServer()
# 提取增量數據
Target_data_source = Database_sqlserver.get_incremental_data(incremental_Max_ID)
return Target_data_source優化策略:
1、延遲加載方式
以上增量記錄服務類IncrementalRecordServer通過覆蓋__new__方法來控制對象的創建,我們在創建對象的時候會先檢查對象是否存在。也可以通過懶加載的方式實現,節約資源優化如下。
class IncrementalRecordServer:
_servers = []
_instance = None
def __init__(self,changeServersID=None):
"""
變量初始化過程
"""
self.F_SDaqID_MAX = Database_sqlserver().get_F_SDaqID_MAX()
self.record_date = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
self.changeServersID = changeServersID
if not IncrementalRecordServer._instance:
print("__init__對象創建")
else:
print("對象已經存在:",IncrementalRecordServer._instance)
self.getInstance()
@classmethod
def getInstance(cls):
if not cls._instance:
cls._instance = IncrementalRecordServer()
return cls._instance懶漢式實例化能夠確保實際需要時才創建對象,實例化a= IncrementalRecordServer()時,調用初始化__init__方法,但是沒有新的對象創建。懶漢式這種方式加載類對象,也稱為延遲加載方式。
2、單例模式能有效利用空間資源,每次利用同一空間資源。
不同操作對象的內存地址相同,且不同對象初始化將上一個對象初始化變量覆蓋,確保最新記錄實時更新。表面上以上代碼實現了單例模式沒問題,但多線程并發情況下,存在線程安全問題,可能同時創建不同的對象空間。考慮到線程安全,也可以進一步加鎖處理.
3、適用范圍及注意事項
本次代碼適用于部署生產指定時間點運行之后產出的增量數據,長時間未啟用再啟動需要清空歷史記錄即增量數據庫或文件ID需清空,一般實時數據增量實現一次加載沒有什么問題,所以這一點也不用很關注(文件方式代碼可自行完善);當加載歷史數據庫或定時間隔產生數據量過大時,需要進一步修改代碼,需要判斷數據規模,指定起始節點及加載數據量,綜合因素考慮,下次分享一下億級數據量提取方案。
4、進一步了解Python垃圾回收機制;并發情況下,通過優化線程池來管理資源。
最后可以添加一個函數來釋放資源
def __del__(self): class_name = self.__class__.__name__ print(class_name,"銷毀")
del obj 調用__del__() 銷毀對象,釋放其空間;只有Python 對象在不再引用對象時被釋放。當程序中有其它變量引用該實例對象時,即便手動調用 __del__() 方法,該方法也不會立即執行。這和 Python 的垃圾回收機制的實現有關。
if __name__ == '__main__':
for i in range(6):
hc1 = IncrementalRecordServer()
hc1.addServer()
print("Record_ID",hc1._servers[i])
# del hc1
time.sleep(60)
#Server2-客戶端client
# 最新服務記錄
hc2 = IncrementalRecordServer()
hc2.getServers()
#查看增量數據
hc2.Incremental_data_client()插入記錄
模擬每1分鐘插入一條記錄,向增量數據庫插入7條
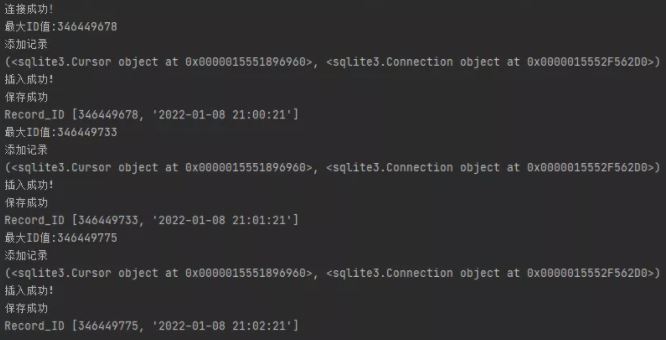
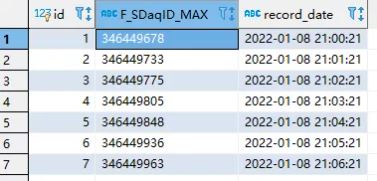
if __name__ == '__main__': # Server3-客戶端client # 手動添加增量起始ID記錄 hc3 = IncrementalRecordServer(changeServersID='346449980') hc3.changeServers()

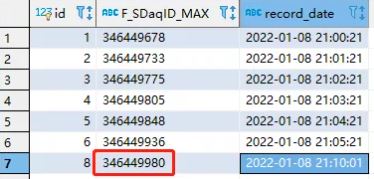
if __name__ == '__main__': #刪除ID hc3 = IncrementalRecordServer(changeServersID='346449980') # hc3.changeServers() hc3.popServers()
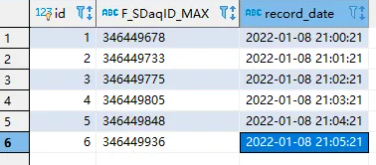
以上是“Python如何實現實時增量數據加載工具”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





