溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關怎么用Python實現數據篩選與匹配的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
數據篩選要求我們在表中篩選出符合條件的數據。
數據匹配需要我們在多個表之間匹配相關的數據。
與之前一樣,完成項目問題的代碼,需要我們先分析數據篩選和數據匹配的需求,再找到對應知識點,確定代碼的執行順序,從而實現項目代碼。
這個案例需要我們篩選出遲到人員的信息,來具體看看。
在【10月考勤統計.xlsx】工作簿中,保存了公司一百名員工的遲到信息,這些信息包含了遲到時間和遲到次數。
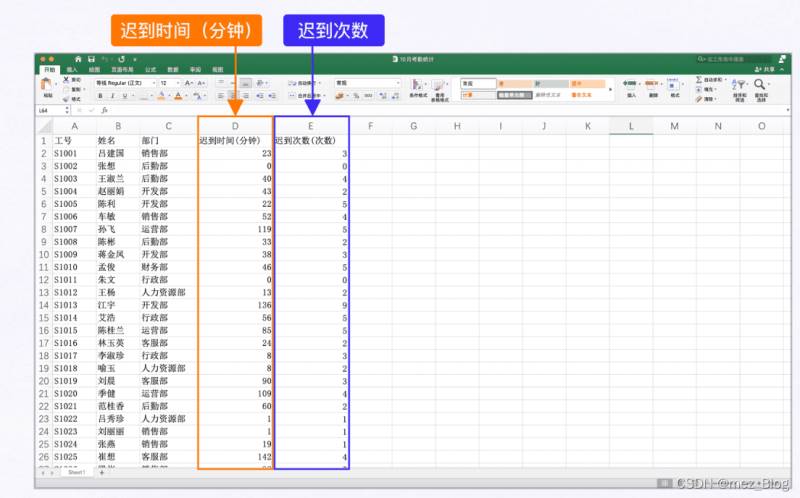
公司規定,遲到時間超過45分鐘且遲到過3次以上的員工記為考勤不合格,需要扣除300的考勤保證金。

之前的同事需要把篩選后的結果保存為【10月遲到人員信息.xlsx】,并將整理后的信息上報給領導。
那么如何用代碼實現這個場景呢?
在編寫代碼之前,我們要先明確任務需求。
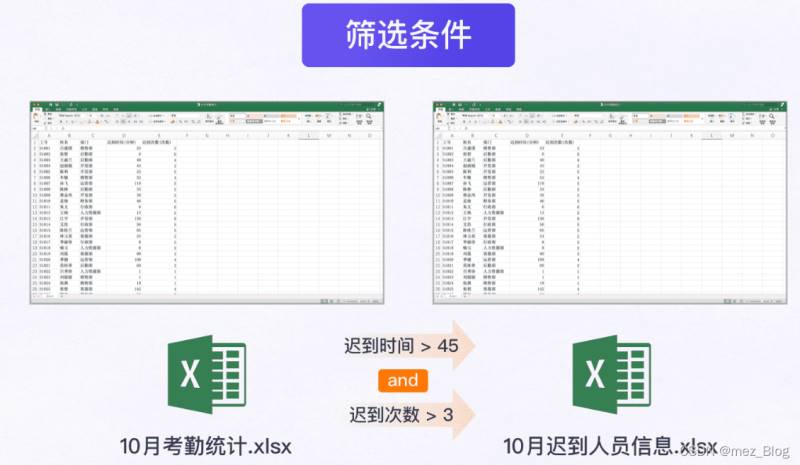
根據公司的規定,篩選出【10月考勤統計.xlsx】中遲到時間大于45分鐘并且遲到次數超過3次以上的員工信息,將遲到人員信息打印出來后再存入新工作簿【10月遲到人員信息.xlsx】中。
代碼實現:
from openpyxl import load_workbook, Workbook
# 打開【10月考勤統計.xlsx】工作簿
wb = load_workbook('./material/10月考勤統計.xlsx')
# 獲取活動工作表
ws = wb.active
print(ws)
print(ws[1])
print('----------------')
# 獲取表頭
late_header = []
for cell in ws[1]:
late_header.append(cell.value)
print(cell.value)
# 新建工作簿
new_wb = Workbook()
# 獲取新工作簿中的工作表
new_ws = new_wb.active
# 將表頭寫入新工作簿的工作表中
new_ws.append(late_header)
# 從第二行開始遍歷表格
for row in ws.iter_rows(min_row=2, values_only=True):
# 取出姓名,遲到時間和遲到次數
name = row[1]
time = row[3]
number = row[-1]
# 判斷是否遲到
if time > 45 and number > 3:
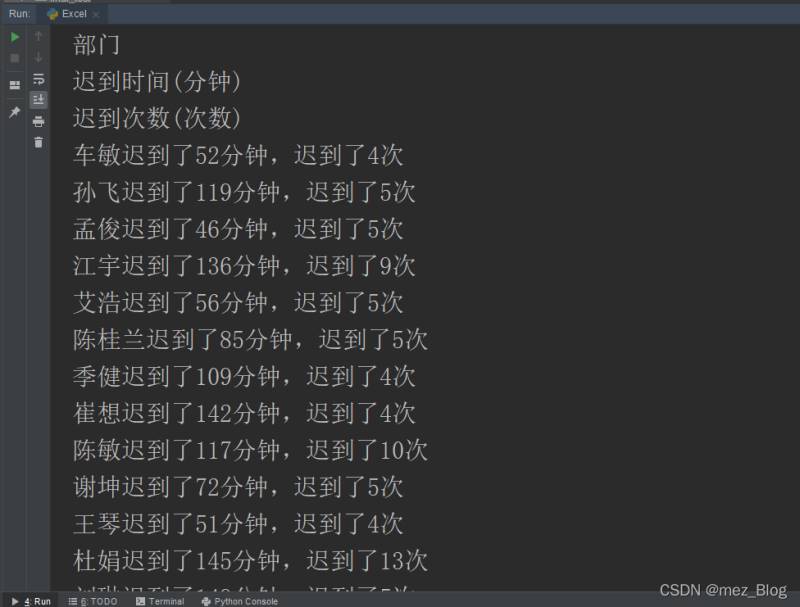
print('{}遲到了{}分鐘,遲到了{}次'.format(name, time, number))
# 將遲到人員信息寫入新工作簿的工作表中
new_ws.append(row)
# 將新工作簿保存為【10月遲到人員信息.xlsx】
new_wb.save('./material/10月遲到人員信息.xlsx')運行結果:

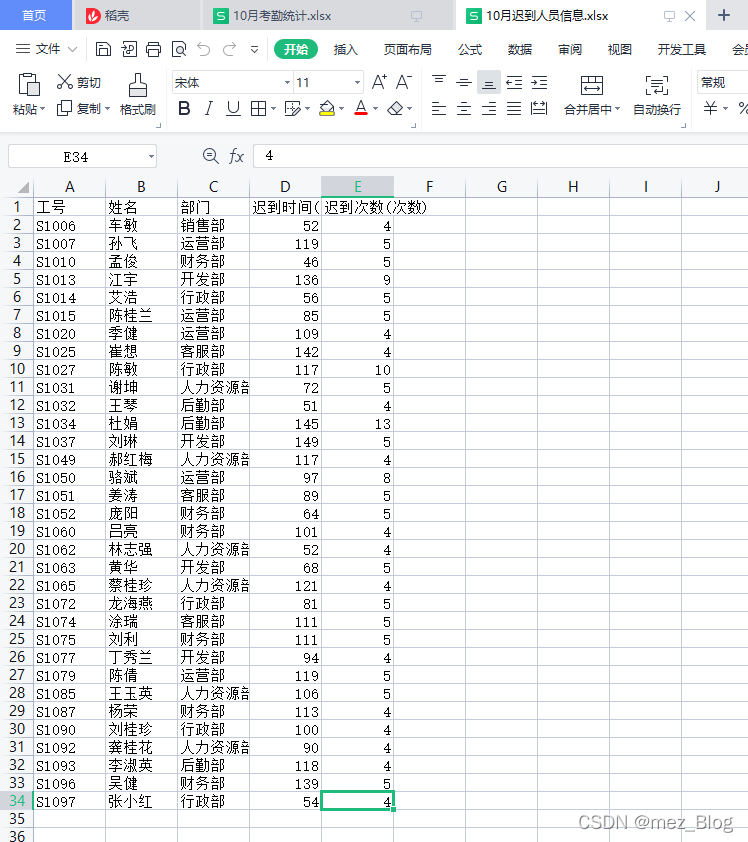
根據任務需求,我們需要獲取兩部分數據:表頭數據和表頭以外的所有數據。
你可能會比較疑惑,為什么要單獨獲取表頭數據呢?

由于任務需要我們生成新的工作簿【10月遲到人員信息.xlsx】,新工作簿中的表頭與【10月考勤統計.xlsx】相同,所以我們需要獲取到表頭的數據以便后續使用。
使用數據
我們需要在這一步實現數據篩選功能,通過分析任務需求可以總結出三個篩選條件:
1)遲到時間大于45分鐘。
2)遲到次數大于3次。
3)同時滿足上面兩個條件。
明確了篩選條件后,就可以借助條件判斷語句,比較運算符,成員運算符和邏輯運算符等Python基礎知識,實現對于數據的篩選,即將上面得到的篩選條件用Python語言實現出來。
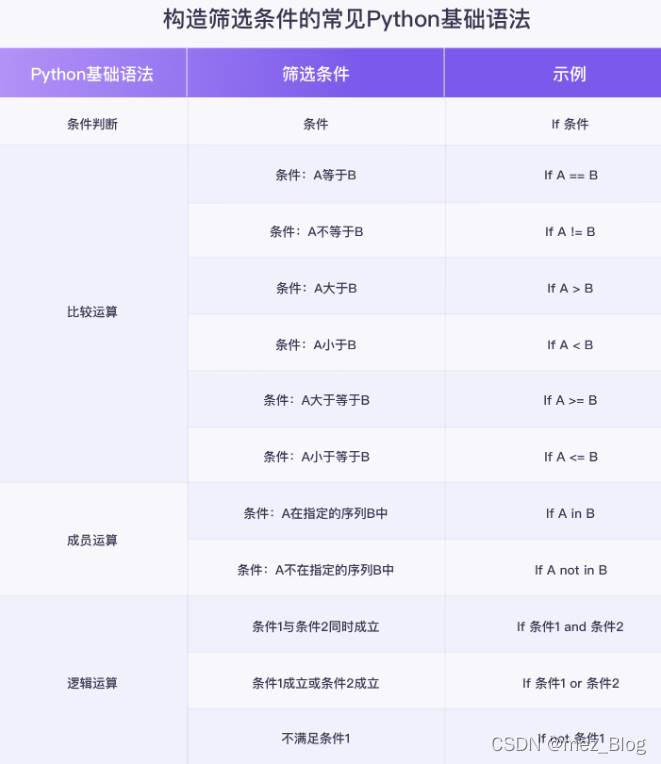
假設我們用time來代表遲到時間,用number代表遲到次數,那么篩選條件就可以寫為:if time > 45 and number > 3:
數據輸出
完成篩選后,我們需要根據實際需求將篩選結果輸出到終端,或將篩選結果保存起來。
本次任務要求我們將篩選后的員工信息打印出來,并且存儲到【10月遲到人員信息.xlsx】中。
如果需要獲取工作簿中滿足某些條件的數據,這種場景就可以被歸類為數據篩選場景。
處理該場景時,可以按照獲取數據,使用數據和數據輸出這三個步驟來處理。
首先是獲取數據,使用上節課學習過的表格讀寫的相關知識,根據任務需求,確定要獲取的是零散的單元格,是單行/單列,還是多行/多列的數據。
數據篩選的關鍵落在了篩選二字上,我們可以在使用數據這一步中實現篩選功能。
在這一步,要仔細理解任務需求,明確篩選條件,然后根據實際情況,選擇Python基礎語法的相關知識(條件判斷語句,比較運算符,成員運算符和邏輯運算符),構造篩選條件。

最后是數據輸出部分,根據實際需要輸出篩選結果,或將篩選結果保存起來。總結起來可以分為三類:
1)將篩選的結果存入學過的數據結構里,比如:列表,元組或字典。
2)將篩選的結果存入文件中。
3)將篩選的結果打印出來。
這個案例需要我們匹配兩張表格中指定的遲到次數,先來看看案例場景。
現有兩張表格,【10月考勤統計.xlsx】中記錄了員工十月份的遲到次數數據,這份表格是公司行政手動記錄的。
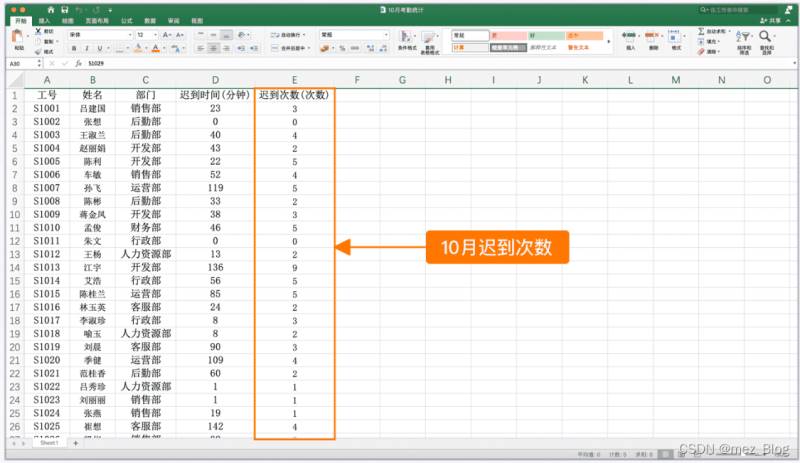
【遲到次數月度統計(10月更新).xlsx】中按月記錄了員工每月的遲到次數數據,這份表格是由公司的考勤系統自動生成的。

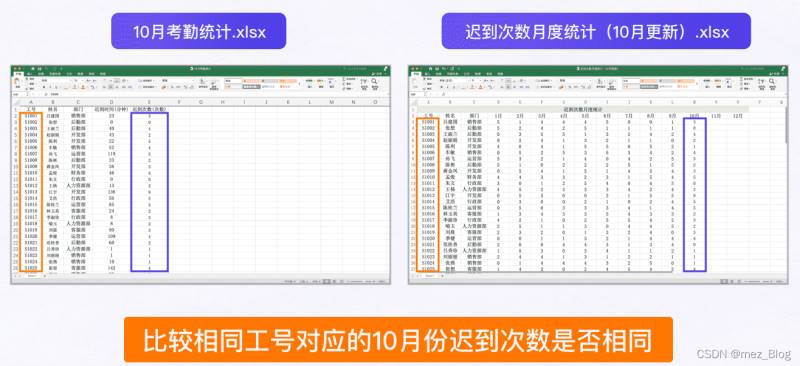
兩份表格中的數據可以通過工號一一對應。
現需要核對兩張表格中10月遲到次數是否匹配(即兩表中相同工號在十月份的遲到次數是否一致),并在終端提醒相關人員去核查不匹配的情況。
代碼實現:
from openpyxl import load_workbook
# 打開工作簿【10月考勤統計.xlsx】,獲取活動工作表
wb = load_workbook('./material/10月考勤統計.xlsx')
ws = wb.active
# 創建遲到人員字典
info_dict = {}
# 循環讀取除表頭外的表格數據
for row in ws.iter_rows(min_row=2, values_only=True):
# 取出員工工號
staff_id = row[0]
# 取出遲到次數
staff_late = row[-1]
# 將信息添加入字典,字典格式為{'員工工號': '遲到次數'}
info_dict[staff_id] = staff_late
# 打開工作簿【遲到次數月度統計(10月更新).xlsx】,獲取活動工作表
monthly_wb = load_workbook('./material/遲到次數月度統計(10月更新).xlsx')
monthly_ws = monthly_wb.active
# 循環讀取出表頭外的表格數據
for monthly_row in monthly_ws.iter_rows(min_row=3, max_col=13, values_only=True):
# 取出員工工號
member_id = monthly_row[0]
# 取出十一月份的遲到次數
member_late = monthly_row[-1]
# 匹配遲到次數是否相等
if member_late != info_dict[member_id]:
print('工號{}遲到情況不匹配,請核查后更新'.format(member_id))運行結果:
為什么會選擇存儲到字典中呢?
因為字典可以很好地體現出工號與遲到次數的對應關系,即{'工號': '遲到次數'}。
然后把【遲到次數月度統計(10月更新).xlsx】中的遲到次數,與字典中存儲的遲到次數進行匹配,再判斷相同工號對應的遲到次數是否相同。
感謝各位的閱讀!關于“怎么用Python實現數據篩選與匹配”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





