溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“awk具體使用方法有哪些”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“awk具體使用方法有哪些”這篇文章吧。
awk是一個強大的文本分析工具,相對于grep的查找,sed的編輯,awk在其對數據分析并生成報告時,顯得尤為強大。簡單來說awk就是把文件逐行的讀入,以空格為默認分隔符將每行切片,切開的部分再進行各種分析處理。

學習具體使用前,先來看下 awk 能干些什么事情:
當然 awk 不僅能做這些事情,當你將它的用法融匯貫通時,可以隨心所欲的按照你的意愿,來進行高效的數據分析和統計。
不過我們需要知道,awk 不是萬能的,它比較擅長處理格式化的文本,比如 日志、csv 格式數據等;
我們先來簡單了解 awk 基本工作原理,通過下邊的圖文講述,希望你能了解 awk 到底是如何工作的。
awk 基本命令格式
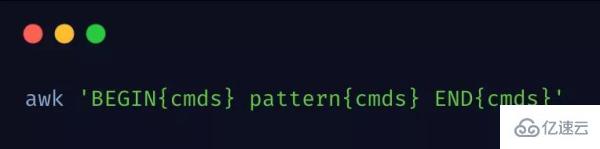
結合下圖來詳細說明 awk 工作原理
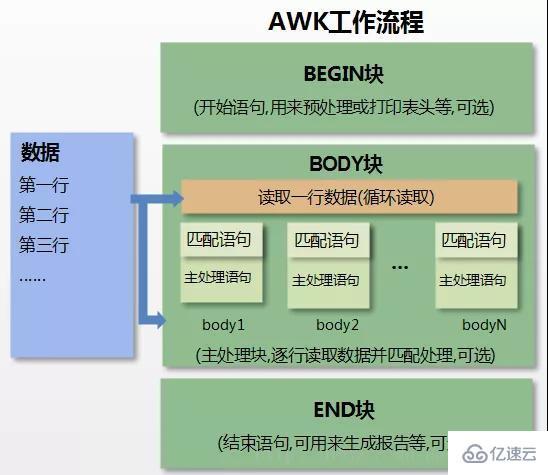
awk 是輸入驅動的,有多少輸入行,就會執行多少次 body 命令。
我們在下邊的示例學習中,要時刻記著:記錄 (Record) 就是行,字段 (Field) 就是列,BEGIN 是預處理階段,body 是 awk 真正工作的階段,END 是最后處理階段。
從下邊內容開始,我們直接進入到實戰。為了方便舉例,我先把如下信息保存到 file.txt
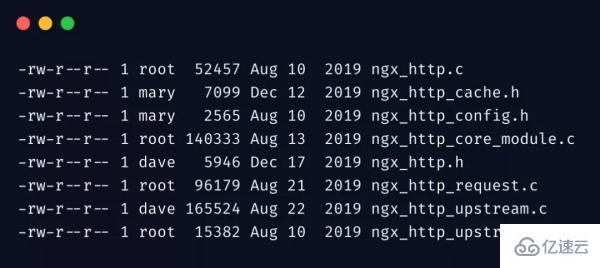
好了,我們先來一個最簡單最常用的 awk 示例,輸出第 1、4、8 列:
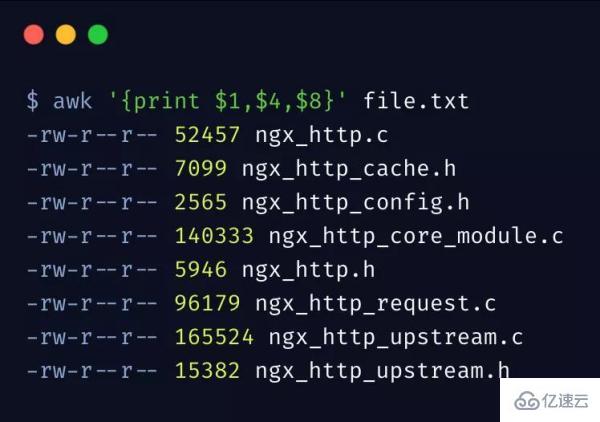
大括號里邊的就是 awk 語句,只能被單引號包含,其中,N表示第幾列,$0 表示整個行內容
再來看下 awk 比較實用的功能 格式化輸出。和 C 語言的 printf 格式輸出是一毛一樣,我個人特別喜歡這種格式化方式,而不是 C++ 中的流的方式。
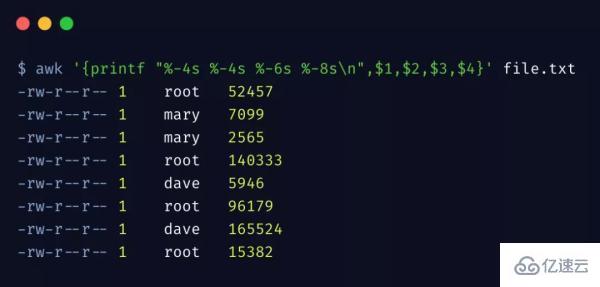
%s 表示字符串占位符,-4表示列寬度為 4,且左對齊,我們還可以根據需要,列出更復雜的格式來,這里先不詳細舉例了。
(一)過濾記錄
有些數據可能不是你想要的,可以根據需要進行過濾
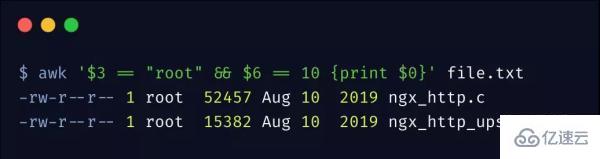
上邊的過濾條件為,第 3 列為 root 且第 6 列為 10 的行,才會被輸出。
awk 支持各種比較運算符號 !=、>、=、(二)內置變量
awk 內置了一些變量,更方便我們對數據的處理
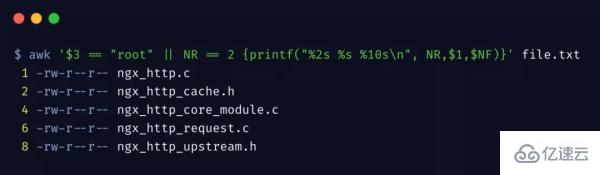
過濾第 3 列為 root 用戶,以及第 2 行內容,且打印時輸出行號。NR 表示當前第幾行,NF表示當前行有幾列。
(三)指定分隔符
我們的數據,不總是以空格為分隔符,我們可以通過 FS 變量指定分隔符。
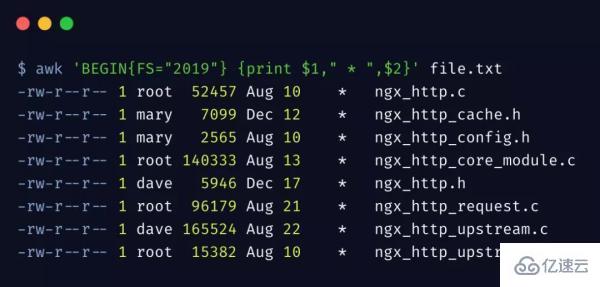
我們指定分隔符為 2019,這樣就將行內容分割為了兩部分,將 2019 替換成了 *
上邊的命令也可以通過 -F 選項指定分割符
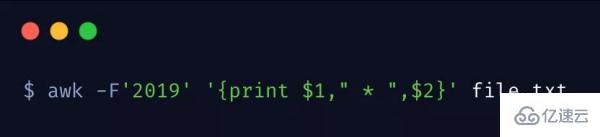
如果你需要指定多個分隔符,可以這樣做 -F ‘[;:]’。相信聰明的你,一定能夠理解并融會貫通的。
同樣,awk 可以指定輸出時的分隔符,通過 OFS 變量來設置
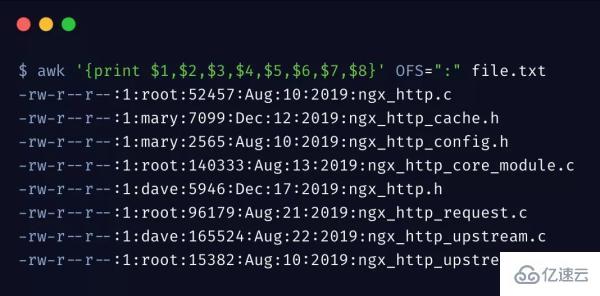
輸出時,各字段用 OFS 指定的符號進行了分隔。
(一)條件匹配
列出 root 用戶的所有文件,以及第一行文件
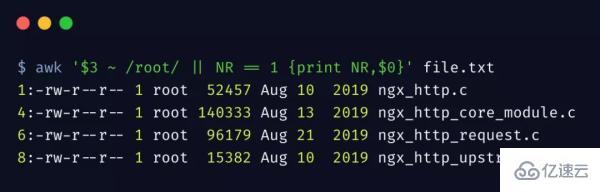
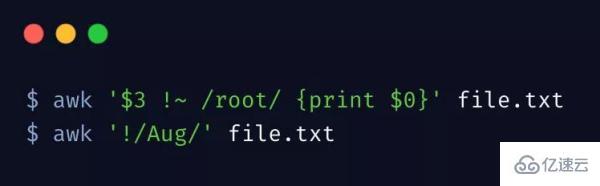
上邊匹配第三列中包含 root 的行,~ 其實就是正則表達式的匹配。
同樣,awk 可以像 grep 一樣匹配某一行,就像這樣
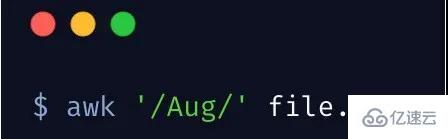
另外,可以這樣 /Aug|Dec/ 匹配多個關鍵詞。
模式取反可以使用 ! 符號
(二)拆分文件
我們來做一件有意思的事情,可以將文本信息拆分為多個文件,下邊命令按照月份(第5列)將文件信息拆分為多個文件
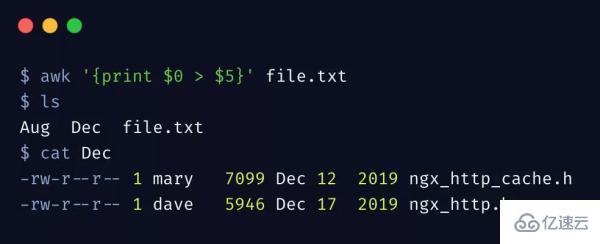
awk 支持重定向符號 >,直接將每行內容重定向到月份命名的文件了,當然你也可以把指定的列輸出到文件
(三)if 語句
復雜的條件判斷,可以使用 awk 的 if 語句,awk 的強大正因為它是個腳本解釋器,擁有一般腳本語言的編程能力,下邊示例通過稍微復雜的條件進行拆分文件
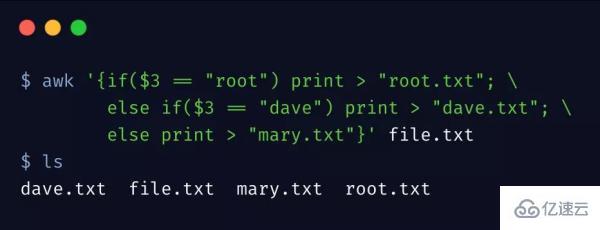
要注意,if 語句是在大括號里邊的。
(四)統計
統計當前目錄下,所有 .c、.h 文件所占用空間大小總和
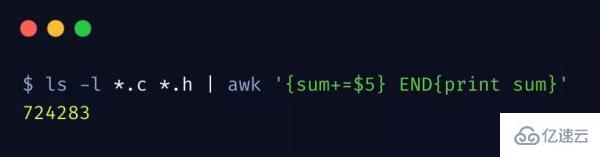
第 5 列表示文件大小,每讀取一行就會將該文件大小計算到 sum 變量中,在最后 END 階段打印出 sum,也就是所有文件的大小總和。
再來看一個例子,統計每個用戶的進程占用了多少內存,注意取值的是 RSS 那一列
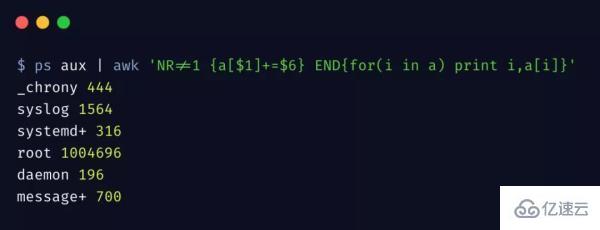
這里用到了 數組 和 for 循環,值得一提的是,awk 的數組可以理解為字典或 Map,key 可以是數值和字符串,這種數據類型在平時很常用。
(五)字符串
通過下邊簡單示例,展示 awk 對字符串操作的支持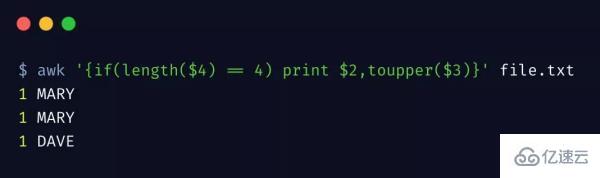
awk 內置支持一系列的字符串函數,length 計算字符串長度,toupper 函數轉換字符串為大寫。
為了從整體上理解 awk 工作機制,我們再來看一個綜合的示例,假設有一個學生成績單:

由于此示例程序稍顯復雜,在命令行上不易讀,另外呢,也想通過此案例介紹另外一種 awk 的執行方式,我們的 awk 腳本如下:
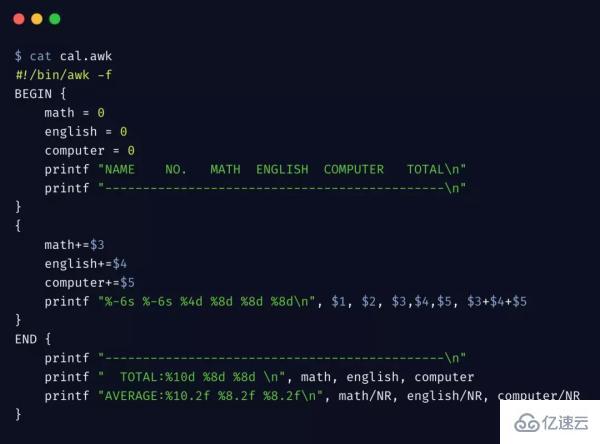
執行 awk 結果如下

我們可以將復雜的 awk 語句寫入腳本文件 cal.awk,然后通過 -f 選項指定從腳本文件執行。
這個簡單示例,完整的體現了 awk 的工作機制和原理,希望通過此示例能夠幫你真正理解 awk 是如何工作的。
通過上述的示例,我們學習到了 awk 的工作原理,下邊我們來總結下幾個概念和常用的知識點。
(一)內置變量
\1. 每一行內容記錄,叫做記錄,英文名稱 Record
\2. 每行中通過分隔符隔開的每一列,叫做字段,英文名稱 Field
明確這幾個概念后,我們來總結幾個重要的內置變量:
NR:表示當前的行數;
NF:表示當前的列數;
RS:行分隔符,默認是換行;
FS:列分隔符,默認是空格和制表符;
OFS:輸出列分隔符,用于打印時分割字段,默認為空格
ORS:輸出行分隔符,用于打印時分割記錄,默認為換行符
(二)輸出格式
awk 提供 printf 函數進行格式化輸出功能,具體的使用方式和 C 語法基本一致。
基本用法
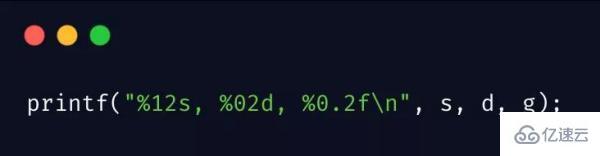
常用的格式化方式:
%d 十進制有符號整數
%u 十進制無符號整數
%f 浮點數
%s 字符串
%c 單個字符
%e 指數形式的浮點數
%x %X 無符號以十六進制表示的整數
%0 無符號以八進制表示的整數
%g 自動選擇合適的表示法
\n 換行符
\t Tab符
(三)編程語句
awk 不僅是一個 Linux 命令行工具,它其實是一門腳本語言,支持程序設計語言所有的控制結構,它支持:
條件語句
循環語句
數組
函數
(四)常用函數
awk 內置了大量的有用函數功能,也支持自定義函數,允許你編寫自己的函數來擴展內置函數。
這里只簡單羅列一些比較常用的字符串函數:
index(s, t) 返回子串 t 在 s 中的位置
length(s) 返回字符串 s 的長度
split(s, a, sep) 分割字符串,并將分割后的各字段存放在數組 a 中
substr(s, p, n) 根據參數,返回子串
tolower(s) 將字符串轉換為小寫
toupper(s) 將字符串轉換為大寫
這里只簡單總結一些常用的字符串功能函數,具體使用方法,還需要你參照前邊的示例程序,舉一反三,運用到實際問題中。
以上是“awk具體使用方法有哪些”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





