溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
大數據:海量數據
結構化數據:即行數據,能夠存儲在二維表中的數據
非結構化數據:無法使用數據的二維邏輯表示數據。如word,ppt,圖片
半結構化數據:在結構化與非結構化之間,自我描述,將結構與數據本身存儲在一起的數據:xml、json、html
goole的論文:MapReduce:Simplified Date Processing On Large Clusters
Dynam
Map:把大數據映射為分割的多個節點處理的小數據
Reduce:折疊
i1,i2 ==> o1,i3 ==>o2,i4==>o4
MapReduce:將大數據中映射為鍵值對
數據的搜集,監控,分析,處理
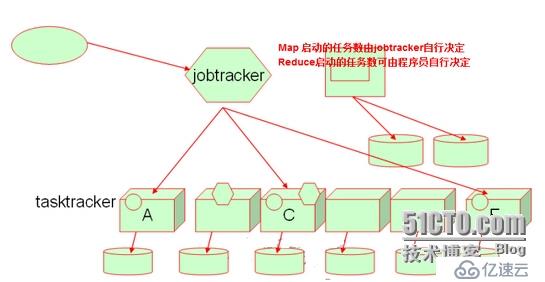
hadoop: jobtracker、tasktracker,namenode,datanode
hadoop的的特性:
(1)向外擴展
(2)數據冗余
(3)將程序移向數據
(4)順序處理數據,避免隨機訪問
(5)向程序員隱藏系統級別的細節
(6)平滑擴展
如何將大數據切割為多個可處理的小數據,如何將處理的結果合并
如何選擇將任務移向多個不同的小數據所在的主機處理任務
如何獲取被分割的小數據
如何保證個Map進程如何同步
Map如何將處理的結果傳輸給Reduce
如何在出現軟件故障或硬件故障后保證任務的完整性
mapreduce:
1.編程框架:API
2.運行平臺
3.具體實現
hadoop:HDFS-->MapReduce(API,Java)
HDFS:
HDFS分布式集群 數據存儲
1)HDFS
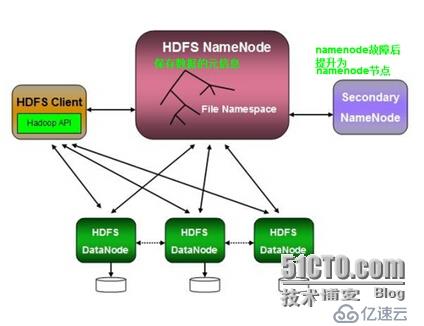
2)向HDFS分文件系統保存數據存儲

MapReduce集群 數據處理 大文件
HBase,運行在HDFS之上 由zookeeper協調工作
Hadoop DataBase
通過zookeeper使hadoop能夠存儲單個小文件,實現隨機存儲
colum:列式存儲
存儲松散型數據,基于鍵值對的列式存儲
將單個小文件合并為大文件
bigtable:大表
ETL
數據的抽取、轉換、加載
日志搜集:
flume
scrible
chukwa
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





