溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
安裝JDK 1.7以上 Hadoop 2.7.0不支持JDK1.6,Spark 1.5.0開始不支持JDK 1.6
安裝Scala 2.10.4
安裝 Hadoop 2.x 至少HDFS
spark-env.sh
export JAVA_HOME= export SCALA_HOME= export HADOOP_CONF_DIR=/opt/modules/hadoop-2.2.0/etc/hadoop //運行在yarn上必須要指定 export SPARK_MASTER_IP=server1 export SPARK_MASTER_PORT=8888 export SPARK_MASTER_WEBUI_PORT=8080 export SPARK_WORKER_CORES= export SPARK_WORKER_INSTANCES=1 export SPARK_WORKER_MEMORY=26g export SPARK_WORKER_PORT=7078 export SPARK_WORKER_WEBUI_PORT=8081 export SPARK_JAVA_OPTS="-verbose:gc -XX:-PrintGCDetails -XX:PrintGCTimeStamps"
slaves指定worker節點
xx.xx.xx.2 xx.xx.xx.3 xx.xx.xx.4 xx.xx.xx.5
運行spark-submit時默認的屬性從spark-defaults.conf文件讀取
spark-defaults.conf
spark.master=spark://hadoop-spark.dargon.org:7077
啟動集群
start-master.sh start-salves.sh
spark-shell命令其實也是執行spark-submit命令
spark-submit --help
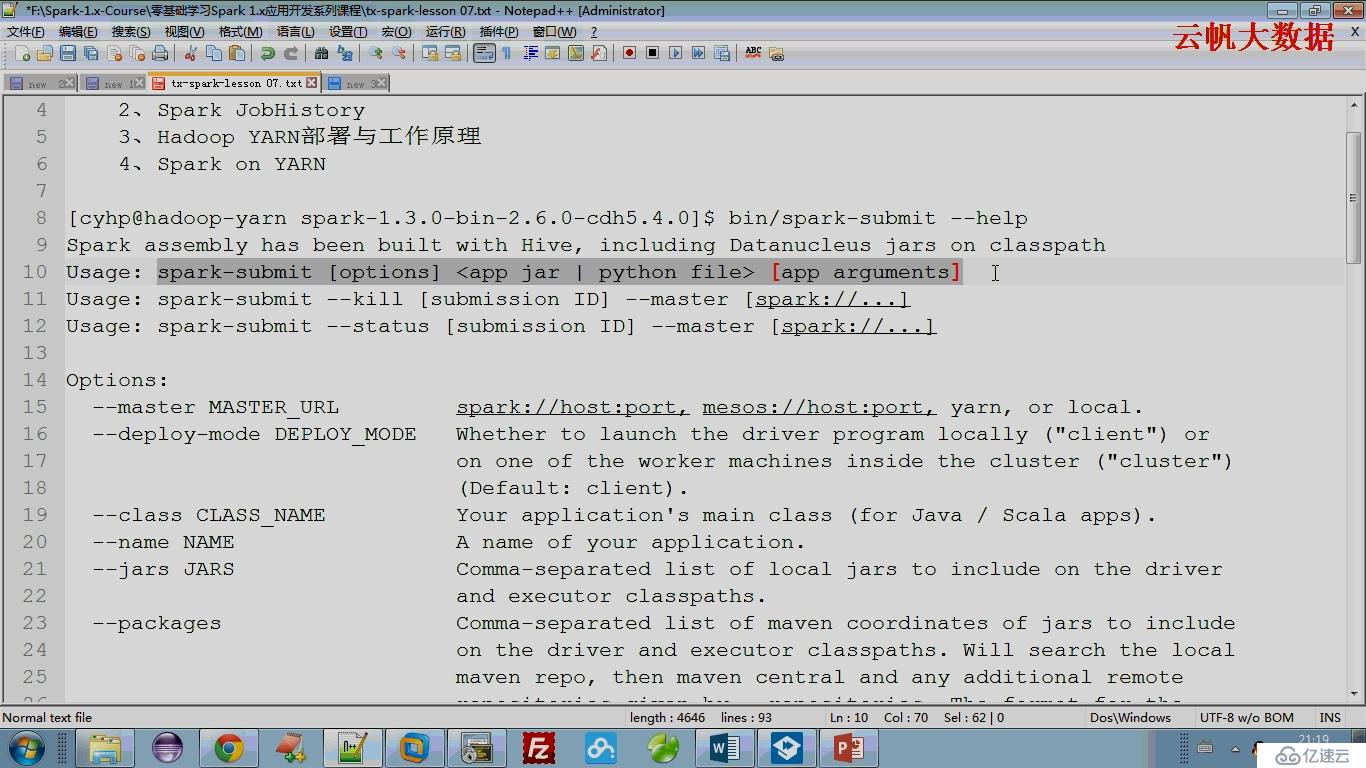
deploy-mode針對driver program(SparkContext)的client(本地)、cluster(集群)
默認是client的,SparkContext運行在本地,如果改成cluster則SparkContext運行在集群上
hadoop on yarn的部署模式就是cluster,SparkContext運行在Application Master
spark-shell quick-start鏈接
http://spark.apache.org/docs/latest/quick-start.html
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





