溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本期內容:
1 解密Spark Streaming運行機制
2 解密Spark Streaming架構
一切不能進行實時流處理的數據都是無效的數據。在流處理時代,SparkStreaming有著強大吸引力,而且發展前景廣闊,加之Spark的生態系統,Streaming可以方便調用其他的諸如SQL,MLlib等強大框架,它必將一統天下。
Spark Streaming運行時與其說是Spark Core上的一個流式處理框架,不如說是Spark Core上的一個最復雜的應用程序。如果可以掌握Spark streaming這個復雜的應用程序,那么其他的再復雜的應用程序都不在話下了。這里選擇Spark Streaming作為版本定制的切入點也是大勢所趨。
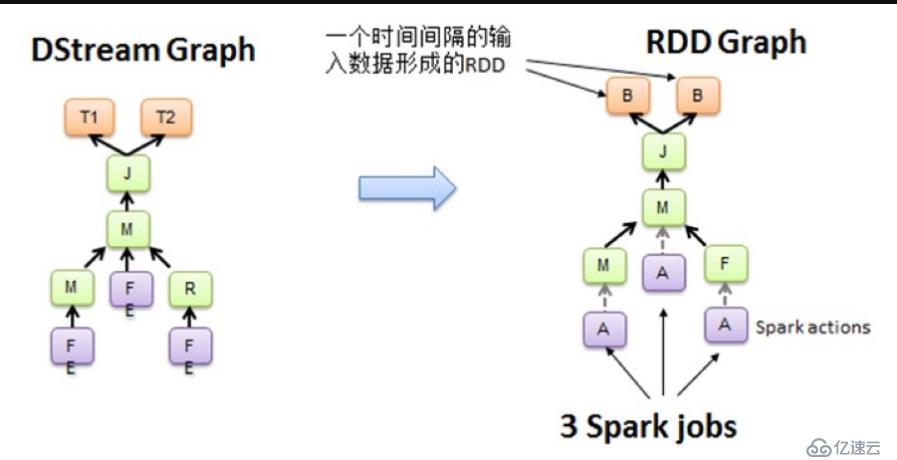
我們知道Spark Core處理的每一步都是基于RDD的,RDD之間有依賴關系。上圖中的RDD的DAG顯示的是有3個Action,會觸發3個job,RDD自下向上依賴,RDD產生job就會具體的執行。從DSteam Graph中可以看到,DStream的邏輯與RDD基本一致,它就是在RDD的基礎上加上了時間的依賴。RDD的DAG又可以叫空間維度,也就是說整個Spark Streaming多了一個時間維度,也可以成為時空維度。
從這個角度來講,可以將Spark Streaming放在坐標系中。其中Y軸就是對RDD的操作,RDD的依賴關系構成了整個job的邏輯,而X軸就是時間。隨著時間的流逝,固定的時間間隔(Batch Interval)就會生成一個job實例,進而在集群中運行。
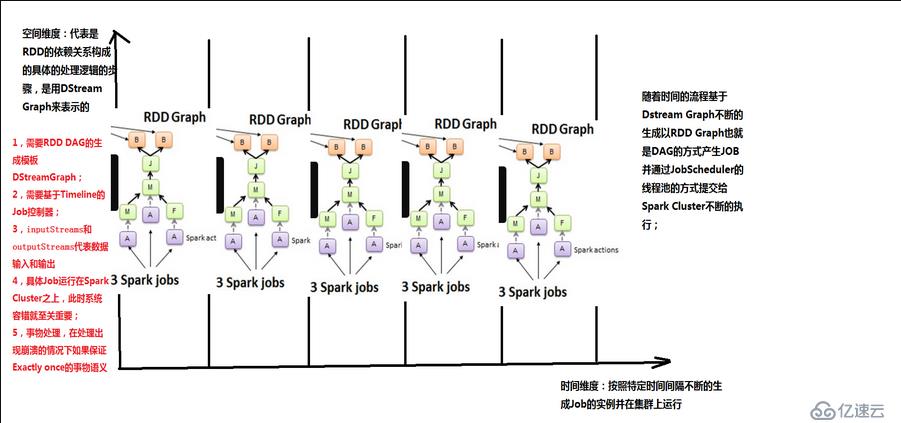
對于Spark Streaming來說,當不同的數據來源的數據流進來的時候,基于固定的時間間隔,會形成一系列固定不變的數據集或event集合(例如來自flume和kafka)。而這正好與RDD基于固定的數據集不謀而合,事實上,由DStream基于固定的時間間隔行程的RDD Graph正是基于某一個batch的數據集的。
從上圖中可以看出,在每一個batch上,空間維度的RDD依賴關系都是一樣的,不同的是這個五個batch流入的數據規模和內容不一樣,所以說生成的是不同的RDD依賴關系的實例,所以說RDD的Graph脫胎于DStream的Graph,也就是說DStream就是RDD的模版,不同的時間間隔,生成不同的RDD Graph實例。
從Spark Streaming本身出發:
1.需要RDD DAG的生成模版:DStream Graph
2需要基于Timeline的job控制器
3需要inputStreamings和outputStreamings,代表數據的輸入和輸出
4具體的job運行在Spark Cluster之上,由于streaming不管集群是否可以消化掉,此時系統容錯就至關重要
5事務處理,我們希望流進來的數據一定會被處理,而且只處理一次。在處理出現崩潰的情況下如何保證Exactly once的事務語意。
從源碼解讀DStream
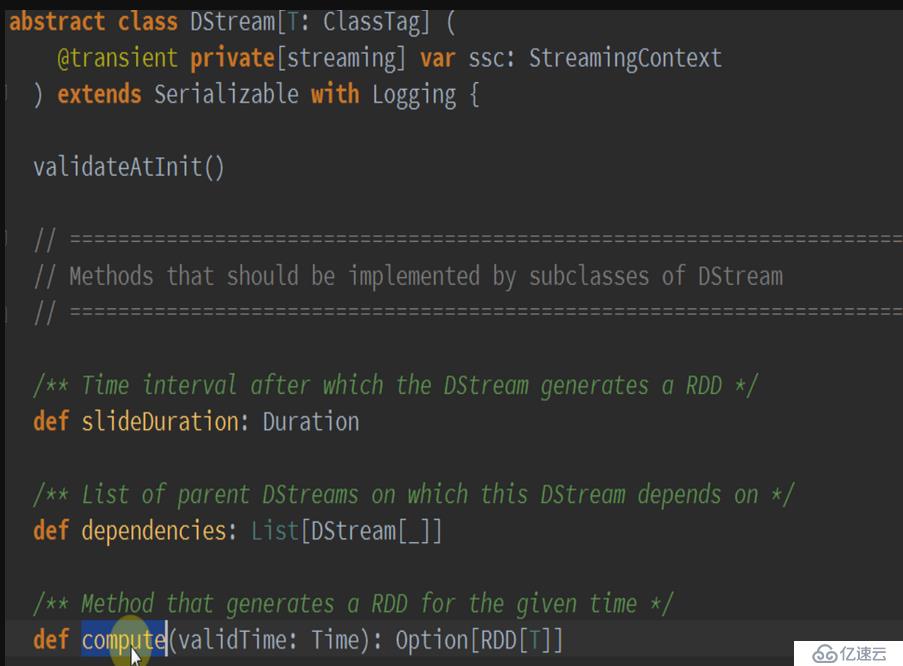
從這里可以看出,DStream就是Spark Streaming的核心,就想Spark Core的核心是RDD,它也有dependency和compute。更為關鍵的是下面的代碼:

這是一個HashMap,以時間為key,以RDD為value,這也正應證了隨著時間流逝,不斷的生成RDD,產生依賴關系的job,并通過jobScheduler在集群上運行。再次驗證了DStream就是RDD的模版。
DStream可以說是邏輯級別的,RDD就是物理級別的,DStream所表達的最終都是通過RDD的轉化實現的。前者是更高級別的抽象,后者是底層的實現。DStream實際上就是在時間維度上對RDD集合的封裝,DStream與RDD的關系就是隨著時間流逝不斷的產生RDD,對DStream的操作就是在固定時間上操作RDD。
總結:
在空間維度上的業務邏輯作用于DStream,隨著時間的流逝,每個Batch Interval形成了具體的數據集,產生了RDD,對RDD進行transform操作,進而形成了RDD的依賴關系RDD DAG,形成job。然后jobScheduler根據時間調度,基于RDD的依賴關系,把作業發布到Spark Cluster上去運行,不斷的產生Spark作業。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





