溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹MySQL中Like模糊查詢速度太慢該怎么進行優化,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
1、like %keyword 索引失效,使用全表掃描。
2、like keyword% 索引有效。
3、like %keyword% 索引失效,使用全表掃描。
使用explain測試了一下:
原始表(注:案例以學生表進行舉例)
-- 用戶表 create table t_users( id int primary key auto_increment, -- 用戶名 username varchar(20), -- 密碼 password varchar(20), -- 真實姓名 real_name varchar(50), -- 性別 1表示男 0表示女 sex int, -- 出生年月日 birth date, -- 手機號 mobile varchar(11), -- 上傳后的頭像路徑 head_pic varchar(200) );
建立索引
#create index 索引名 on 表名(列名); create index username on t_users(username);
like %keyword% 索引失效,使用全表掃描
explain select id,username,password,real_name,sex,birth,mobile,head_pic from t_users where username like '%h%';

like keyword% 索引有效。
explain select id,username,password,real_name,sex,birth,mobile,head_pic from t_users where username like 'wh%';

like %keyword 索引失效,使用全表掃描。

這個我最開始都沒聽說過,今天查閱了一下資料,才知道有這個寶貝東西,
instr(str,substr):返回字符串str串中substr子串第一個出現的位置,沒有找到字符串返回0,否則返回位置(從1開始)
#instr(str,substr)方法 select id,username,password,real_name,sex,birth,mobile,head_pic from t_users where instr(username,'wh')>0 #0.00081900 #模糊查詢 select id,username,password,real_name,sex,birth,mobile,head_pic from t_users where username like 'whj'; # 0.00094650
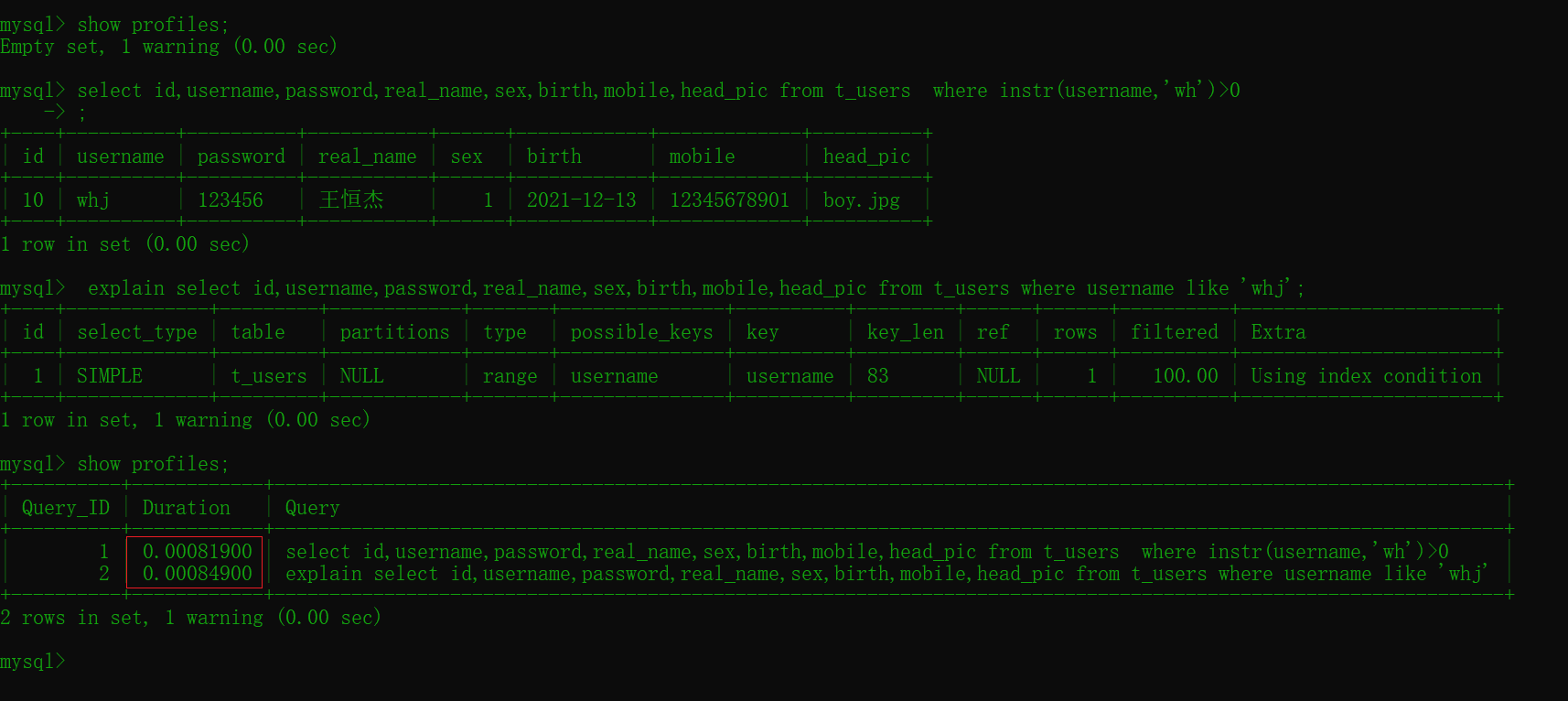
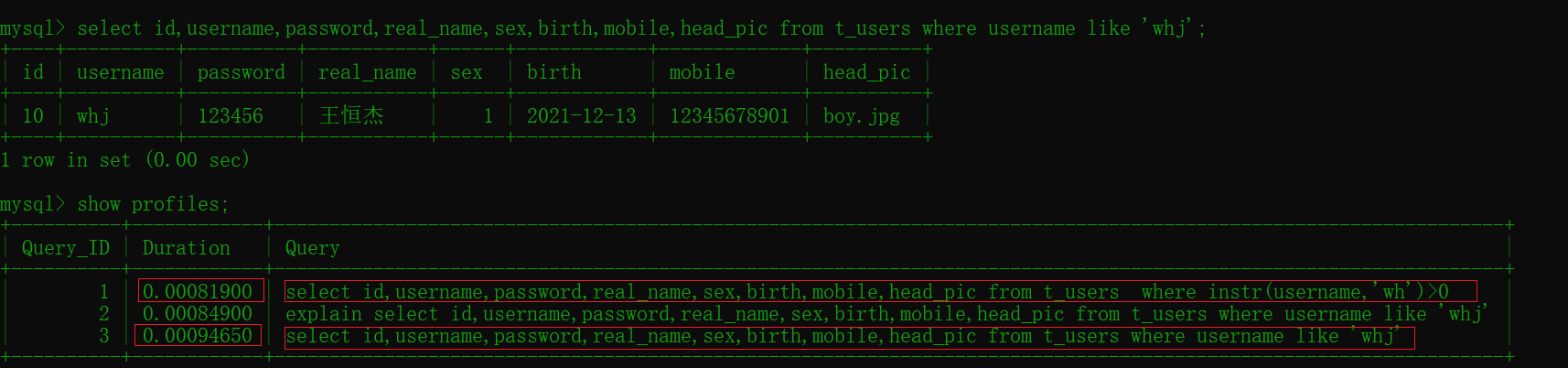
比較兩個效率差距不大主要原因是數據較少,最好多準備點原始數據進行測試效果最佳
以上是“MySQL中Like模糊查詢速度太慢該怎么進行優化”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





